“超A计划”创新官阵营公布 | 来自全球名企的创新官们,等你来过招!
图能够表示真实世界中许多结构化的数据,图相似度问题是关于图结构的基础性问题,同时也是生命科学、药物研发、模式识别等计算机科学及其交叉领域的基础性问题。
在CVPR 2021中发表的新论文“Combinatorial Learning of Graph Edit Distance via Dynamic Embedding.”里,研究人员实现了借助计算机的高算力,自动计算得到图结构之间的相似度分数,在本文中,我们将主要关注图编辑距离,并对其进行进一步阐释。https://arxiv.org/abs/2011.15039https://github.com/Thinklab-SJTU/ThinkML4CO
背景知识
图(graph)是一种广泛存在且普遍的数据形式,通过“节点”(vertex)与“边”(edge),图能够表示真实世界中许多结构化的数据。例如,分子、计算机程序、具有关键点的图像均可用图结构进行表示。一个关于图结构的基础性问题是,给定两个图结构,如何通过算法得到它们之间的相似程度,即图相似度问题。图相似度问题是生命科学、药物研发、模式识别等计算机科学及其交叉领域的基础性问题。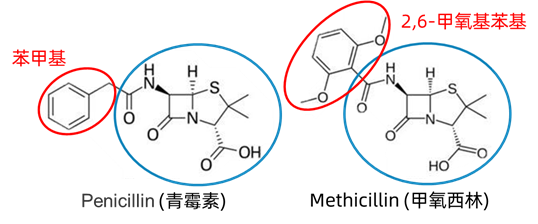
如图1所示,甲氧西林是人工合成的一种青霉素变体,它具有和青霉素相似的抗菌性质,且它们的主要分子结构(蓝色)是相同的。通过计算机程序自动判定两个分子是否相似,进而生成和目标分子相似的分子结构,就可以辅助和加速新药研发。实际上,图相似度计算是当下AI制药技术中的重要一环。
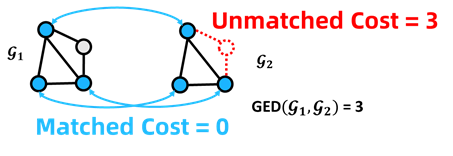
在这篇文章中,我们的目的是借助计算机的高算力,自动计算得到图结构之间的相似度分数。常见的相似度度量有图编辑距离(Graph Edit Distance,GED)、最大共同子图(Maximum Common Subgraph, MCS)等。在本文中,我们主要关注图编辑距离,如图2所示,该问题中的编辑距离为3。如图2所示,将通过若干编辑操作得到的,我们称之为一条编辑路径(edit path)。当然,理论上存在无数条编辑路径(因为可以加一个点再把它删掉),我们称对应的编辑代价最小的编辑路径为最优编辑路径(optimal edit path)。图编辑距离问题的目标即为,给定两个图结构,求最优的编辑路径。
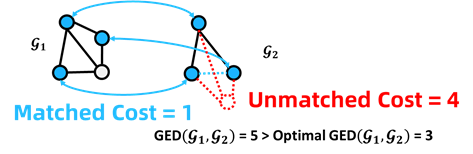
在开始讨论具体算法之前,我们需要指出,“编辑路径”与“节点匹配”两个概念是等价的。根据节点匹配关系,即可导出编辑操作,进而得到编辑代价。如图3所示,如果两个图结构之间的匹配是最优的,此时得到的GED值与最优值相等。反之,如图4所示,如果两个图结构之间匹配是次优的,那么对应的GED值也为次优的。
传统树搜索算法
在传统计算机理论研究中,科学家提出了基于树搜索的算法,用于求解图编辑距离问题的最优解。如图5所示,搜索树中的每个状态(state)是两个部分匹配的图结构,搜索树每变深一层,就会增加一对被匹配的节点。然而,图编辑距离的本质是一个NP-难的组合优化问题,即如果图的规模不断扩大,搜索树规模将呈指数级增长,我们无法在可接受的多项式时间内通过精确的树搜索算法得到问题的最优解。在实际场景中,精确地求解匹配是不可接受的。因此,在实际应用中,需要一种快速且有效的近似匹配算法,能够在可接受的时间内计算得到一个尽量好的匹配关系。本发明提出了一种基于机器学习引导的树搜索方法,通过机器学习算法的引导,使传统树搜索方法能够更快收敛。
发表在2019年WSDM会议(International Conference on Web Search and Data Mining 2019)上的论文[1]提出了一种基于机器学习的图相似度比对方法。
其中,输入两个待匹配的图结构,[1]提出依次使用机器学习中的图神经网络(Graph Neural Network,GNN)[2]和注意力机制(Attention Mechanism)[3],分别得到两个图的特征向量。随后,将两个特征向量输入神经张量网络(Neural Tensor Network)[4],神经张量网络会比对两个输入特征向量的相似程度,以回归(regression)的形式输出一个相似度分数。但是,[1]提出的方法在输出层直接采用回归算法,仅能提供一个相似度分数,无法得到匹配结果(匹配结果的意思是,G1 的每个节点和G2 的每个节点之间的对应关系)。在不提供匹配结果的情况下,如果神经网络模型出错,输出了错误的相似度分数,用户无法被告知;因此,[1]的模型不具备可解释性,也不具备模型出错情况下的鲁棒性。在这篇文章中,我们提出使用机器学习算法引导经典的A*搜索算法。A*是一种经典的优先树搜索算法,A*求解图编辑距离的流程如下所示。

其中,控制搜索优先级的关键参数即为 g(p)+h(p)。如图6所示, g(p) 代表已匹配部分的编辑代价,可以通过匹配关系精确计算得到; h(p)代表未匹配部分的编辑代价,需要使用算法进行预测。计算机科学家已经证明,如果预测得到的 h(p)永远是真值的上界,A* 算法可以得到GED问题的最优解。显然,如果能准确预测 h(p),算法必然会以最快速度搜索到最优解。当然,你可以使用另一个GED求解器精确地求得 h(p),但精确地求解 h(p)又需要进行一次指数级别的树搜索。因此,精确求解 h(p)是不可能的,只能对 h(p)进行预测。过去的传统算法采用启发式方法预测 h(p);我们在论文中提出,使用机器学习算法,利用过去的经验数据高效预测 h(p) 。我们的预测算法如图7所示。我们复用了[1]提出的主要框架,同时由于我们对计算效率非常关心,因此我们[1]模型中的冗余部分进行了剔除。根据具体的任务不同,我们选择了GCN或SplineCNN作为GNNbackbone。需要注意的是,在我们的框架中,不再保证预测得到的h(p)是最优值的上界,因此我们的算法结果不一定是最优的。我们的期望是,利用机器学习算法,更好地权衡时间与精度。
作为一个NP-难的组合优化问题,图编辑距离算法需要在时间和求解精度之间做出权衡。在实验中,我们发现,GNN的前向计算需要花费较多的时间,而算法的运行时间又是我们最关心的维度。因此,我们在这篇文章中提出了动态图嵌入(Dynamic Embedding)算法,用于高效地获得图嵌入向量。
对于图编辑距离问题,GNN的前向计算有如下特点:在搜索树中,每当我们新匹配了一对节点,那么实际上待GNN处理的图结构只改变了一个节点;如果GNN只有3层,实际上只有该节点的3阶邻居被更新了embedding。我们提出了三种可能的解决方式,分情况讨论:- 普通的GNN前向计算(图8第一行)直接对所有节点的embedding重算一遍,显然有大量的计算冗余。在实验中我们也发现该算法的运算速度无法满足需求;
- 利用上述特性“如果GNN只有3层,实际上只有该节点的3阶邻居被更新了embedding”,我们搭建了图 8第二行所示的节点embedding方法。但是,我们的代码实现下,该算法会带来额外计算和存储开销,没法获得显著的速度提升;
- 在论文中,我们采用了图 8第三行所示的节点embedding方法,一次前向计算过后,所有节点的特征被缓存,在需要的时候从缓存中读取复用。我们的这一设计能够为图编辑距离计算带来显著的加速。实际上,我们的embedding方法设计动机来自于动态规划算法中的设计理念:利用缓存,最大限度地复用中间结果。
3个实验数据集分别是AIDS(分子),LINUX(二进制程序)和Willow-Cars(图像)。其中,AIDS与Willow-Cars较困难(AIDS的节点有类别之分、Willow-Cars的边有权重),LINUX较为简单(无类别的点、无权边)。在实验中,我们比较了现有的深度学习方法(表格上半部分)以及传统算法(表格下半部分)。可以看到,我们的算法保持了传统树搜索算法的高精度。
下图所示的是我们的机器学习引导的A*算法(红色)和传统启发式引导的A*算法(蓝色)在搜索树规模的差异。可以看到,随着问题规模(横轴)增大,我们的算法能够显著地降低搜索树规模。下表所示的是传统A*算法(第一行)与我们的机器学习A*算法(第二行)在三个数据集上的运算时间差异。对于较难的AIDS和Willow-Cars数据集,我们的算法都可以显著地节省运算时间。
参考资料
[1] Bai, Yunsheng and Ding, Hao and Bian,Song and Chen, Ting and Sun, Yizhou and Wang, Wei. SimGNN: A Neural Network Approach to Fast Graph Similarity Computation. WSDM 2019.[2] Kipf, Thomas N and Welling, Max. Semi-supervised Classification with Graph Convolutional Networks. ICLR 2017.[3] Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Lukasz and Polosukhin, Illia. Attention is all you need. NIPS 2017.[4] Socher, Richard and Chen, Danqi and Manning, Christopher D. and Ng, Andrew Y. Reasoning with Neural Tensor Networks for Knowledge Base Completion. NIPS 2013.
Illustrastion by Oleg Shcherba from Icons8
- The End -
机会难得,赶快上车吧!
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:


















