不使用标签数据! 自动搜索Transformer混合结构,同速度超过EfficientNet 2.1%!
来自蒙纳士大学、中山大学和暗物智能研究院等研究机构的研究人员提出了一种分块自监督神经网络结构搜索方法 (Block-wisely Self-supervised Neural Architecture Search,BossNAS)来探索CNN-Transformer混合网络 (Hybrid CNN-transformers)。
BossNAS成功解决了以往神经网络结构搜索 (NAS) 算法中庞大权重共享空间造成的评价不准问题以及有监督分块NAS中结构偏见的问题,在所提出的HyTra搜索空间中,它自动搜索出的CNN-Transformer混合网络,在ImageNet达到了82.2%的精度,在相同计算时间 (compute time) 下,超越了ViT,DeiT,BoTNet,T2T,TnT等人工设计的Transformer和混合Transformer,同时以2.1%的优势超越了自动搜索的网络EfficientNet。

论文链接:
https://arxiv.org/abs/2103.12424
代码:
https://github.com/changlin31/BossNAS

一、分块自监督NAS方法
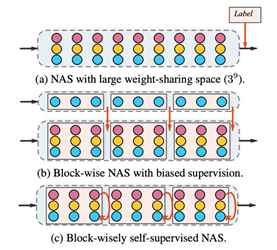
分块NAS (block-wise NAS) 方法在One-shot NAS方法的基础上,将搜索空间在深度上分块,成功的降低了权重共享导致的结构评价偏差。但分块NAS方法引入教师结构作为中间层监督,不可避免的产生了结构偏好,导致其在使用不同教师结构或应用于多样搜索空间时会产生不公平的候选网络结构评价 (上图b) 。为解决上述问题,本文舍弃教师结构,提出一种无监督NAS方法,BossNAS (上图 c) 。
2. 循环集成自监督 (ensemble bootstrapping) 训练
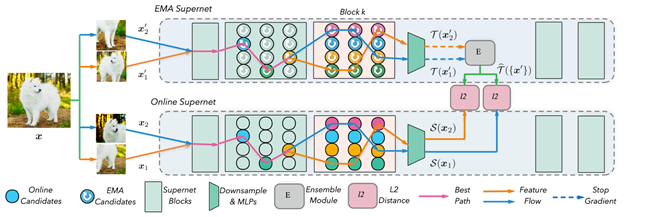
首先,作者提出以超网络 (supernet) 本身替换原本的分块NAS方法中的教师网络,由此构造出孪生超网络 (Siamese supernets) 。之前的双生网络训练使用对比学习以及bootstrapping方法。
1. 取一个训练样本,并产生此样本多个不同的随机数据增强视角 (augmented view);
2. 训练时,在线超网络 (Online supernet) 中每一条采样路径都通过此训练样本的一个视角来预测教师超网络中此训练样本的其他视角经过多条采样路径的概率集成 (probability ensemble) (见上图) ;
3. 以种群中心为目标的无监督评价和搜索

二、CNN-Transformer混合搜索空间
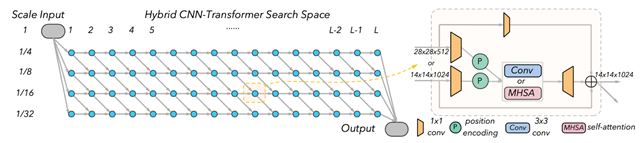
作者提出了一个纺织状 (fabric-like) 的CNN-Transformer混合搜索空间,HyTra。
首先,作者采用ResNet中的residual bottleneck 为卷积候选building block,ResConv。其次,作者为了降低transformer候选building block,ResAtt的计算复杂度,使用一种类似CPVT中隐式位置编码的模块来替换BoTNet building block中的相对位置编码分支。隐式位置编码模块也被加到ResConv中,同时负责下采样,使得纺织状空间中不同尺度的输入得以权重共享 (见上图右侧) 。
2. 纺织状 (Fabric-like) 空间
除基础模块外,CNN和Transformer在宏观网络结构上也有很大不同,CNN一般使用不同尺度的多个阶段来处理图片数据,而典型的Transformer自始至终不改变数据的空间维度大小(序列长度)。为涵盖CNN和Transformer,作者提出了纺织状宏观结构的搜索空间,具有灵活、可搜索的下采样位置(见上图左侧)。此搜索空间涵盖了类似于ResNet,BoTNet,ViT,DeiT,T2T-ViT等模型的候选结构。
三、实验
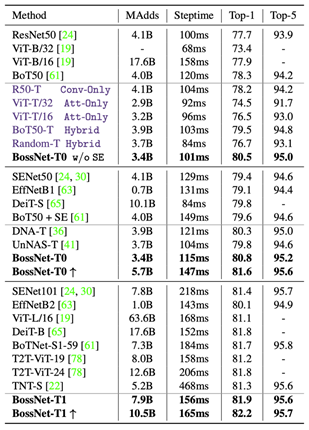
在作者提出的HyTra搜索空间中,BossNAS搜索出的BossNet-T模型在ImageNet达到了最高82.2%的精度,在相近的计算时间 (compute steptime) 下,优于现有的手工设计或自动搜索的模型,如SENet,EfficientNet,DeiT,BoTNet,T2T-ViT等等;同时优于搜索空间中的其他手动或随机选择的模型 (以深蓝色标出) ;也优于其他NAS方法 (DNA,UnNAS) 在此搜索空间中搜出的模型。
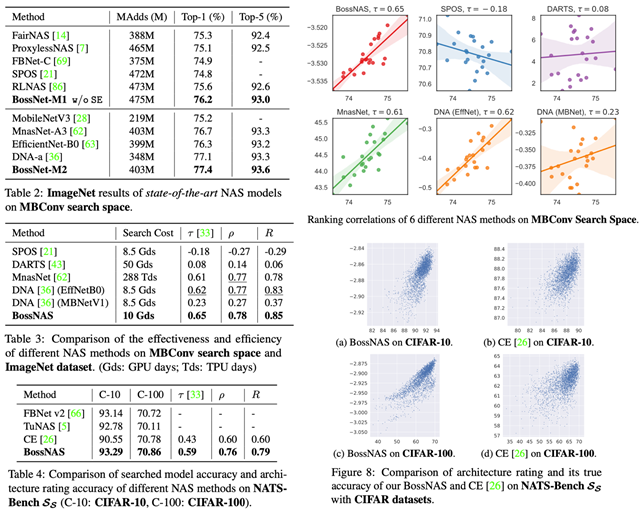
在MBConv搜索空间中,搜索出的模型BossNet-M,超越了其他NAS方法搜索的模型 (Table2) 。在模型排序相关性指标上,BossNAS达到了0.78 Spearman rho,超过了包括MnasNet和DNA的其他NAS方法 (Table 3和右上图) 。
3. 收敛表现
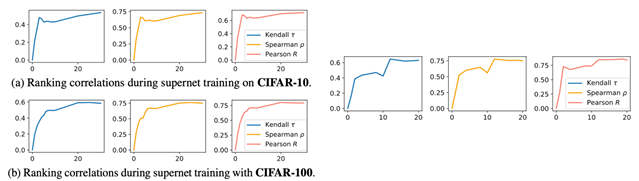
最后,作者还展示了自监督训练过程中模型评分的相关性变化,如上图,BossNAS的评分的相关性在多个搜索空间和数据集都随训练过程逐渐上升并趋于稳定(左:NATS-Benchsize搜索空间和CIFAR数据集,右:MBConv搜索空间和ImageNet数据集)。
消融实验和更多细节请参照文章。
- The End -


扫码观看!
本周上新!

如果你也想成为讲者
▼


