vivo AI计算平台的监控高可用方案

2018 年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设 AI 计算平台。经过两年的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化能力。VContainer 是计算平台的底座,是基于 Kubernetes 构建的容器平台,具备资源调度、弹性伸缩、零一混部等核心能力。VContainer 的容器集群有上千个节点,拥有超过 100PFLOPS 的 GPU 算力。集群里同时运行着上千个 VTraining 的训练任务和上百个 VServing 的推理服务。本文主要分享了 VContainer 的监控高可用方案的选型和部署实践,以及各种踩坑经验。
Prometheus 是新一代的云原生监控系统,始于 2012 年,并于 2016 年继 Kubernetes 之后成为第二个正式加入 CNCF 基金会的项目,天生完美支持 Kubernetes。Prometheus 提供强大的数据采集、数据存储、数据展示、告警等功能,并且很多设计思想都来源于 Google 内部的监控系统 Borgmon。
vivo ai 计算平台之前的方案采用了 Prometheus + AlertManager + Grafana,此方案存在以下问题:
1. 服务都是单副本的,如果故障会导致相关功能不可用;
2.prometheus 做的事情太多,指标采集,复杂查询,告警检测,数据压缩 / 存储等,出问题的概率也比较大;
3. 集群规模变大,prometheus 处理的数据更多,内存也消耗更多,容易 OOM。
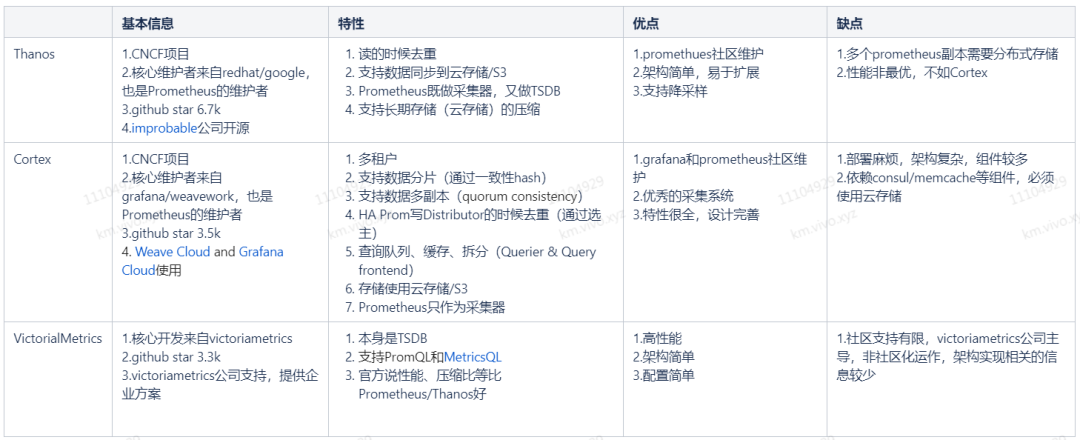
由此可见,thanos 虽然性能非最优,但架构简单,使用 / 维护方便,且有较完善的社区支持。所以我们选择了 thanos 作为集群监控的高可用方案。
Thanos 是由多个组件构成的监控高可用系统,并且有着不受限制的数据存储能力,可以无缝集成到现有的 Prometheus 上。Thanos 使用 Prometheus 2.0 存储格式,把历史数据以相对高性价比的方式保存在对象存储里,同时兼有较快的查询速度。此外,它还能对你所有的 Prometheus 提供全局查询视图。
Thanos 的目标:
1. 指标全局查询视图;
2. 指标无限期保留;
3. 组件的高可用性(包含 Prometheus)。
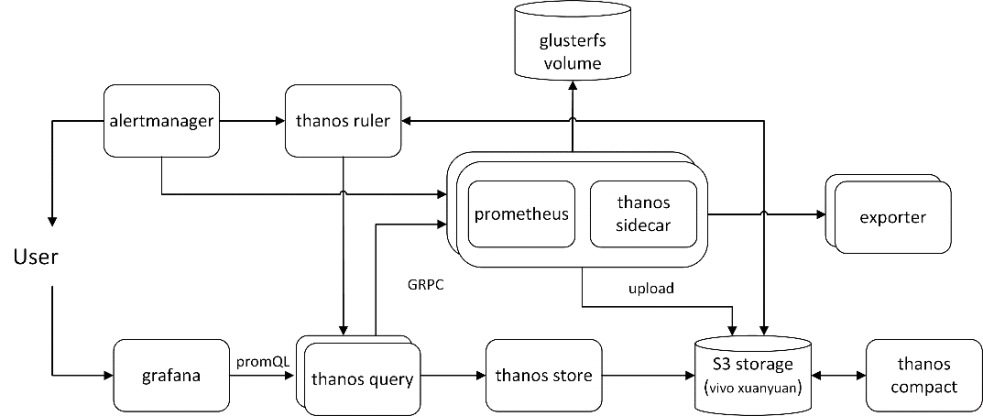
sidecar 是伴随 prometheus 的主要组件,部署时 sidecar 容器和 prometheus 容器在同一个 pod 里。sidecar 主要功能有:1. 读取和归档对象存储中的数据;2. 管理 prometheus 的配置和生命周期;3. 将外部标签注入 prometheus 配置中,并区分 Prometheus 的副本;4. 调用 prometheus 的 promQL 接口,提供给 thanos query 查询。
除了 Prometheus 的规则外,Thanos Ruler 基本上执行与查询器相同的操作。唯一的区别是它可以与 Thanos 组件进行通信。ruler 是可选组件,可根据需求评估是否使用。我们大部分的告警使用了 prometheus 自身的 rule 功能,因为告警需要最新的指标。prometheus 副本数量的告警,可以使用 ruler 实现。
query 是 thanos 的指标查询入口,使用 grafana 或 prometheus client 查询时,均可用 query 地址取代 prometheus 地址。可以部署多个副本,实现 query 的高可用。query 的主要功能有:1. 监听 HTTP 并将查询转换为 Thanos gRPC 格式;2. 汇总来自不同来源的查询结果,并且可以从 Sidecar 和 Store 中读取数据;3. 在高可用设置中,Thanos Query 可以对查询结果进行去重。
store gateway 将对象存储的数据暴露给 thanos query 去查询。store gateway 在对象存储桶中的历史数据之上实现 store API,主要充当 API 网关,因此不需要大量的本地磁盘空间。在启动时加入 Thanos 集群,并暴露其可以访问的数据。store gateway 保存了少量本地磁盘远程块与存储桶的同步信息,通常可以安全地在重新启动期间删除数据,但这样做会增加启动时间。
compact 使用 Prometheus 2.0 存储引擎,对对象存储中的数据进行压缩分块。通常不与安全语义并发,确保每个存储桶必须部署一个。compact 还会进行数据下采样,40 小时后 5 分钟下采样,10 天后 1 小时下采样。下采样能加速大时间区间监控数据查询的速度。
部署前需要对 thanos 进行测试,需确保以下功能正常。a.grafana/Querier 数据展示正常;b.query 读去重;c.query 分片合并功能;d. 历史数据(S3)和近期数据(2 小时内)的读写;e.ruler 告警;f. 停掉一个 / 多个 prometheus 时,监控系统的可用性。
集群原有的监控采用了 prometheus + grafana + exporter 的方案。因为 k8s 的组件都是松耦合的,且 thanos 的 prometheus 需要和 sidecar 一同部署。所以部署 thanos 共用了之前的 expoter,其余组件均另外单独部署。thanos 部署的 yaml 和细节可参考 https://www.metricfire.com/blog/ha-kubernetes-monitoring-using-prometheus-and-thanos/
thanos-query 查不到数据,报错“No store matched for this query”,目前只能重启解决。重启 prometheus 可能导致这个问题。
thanos 的历史数据需要上传到对象存储 S3 中,但近两小时的数据是没有上传的。S3 存储我们采用了 vivo 对象存储(轩辕),近期存储我们采用了 glusterfs 集群的高可用卷。thanos S3 配置可参考,https://thanos.io/tip/thanos/storage.md/#s3
实践中发现写入到 vivo 对象存储的数据足够多时(对象数量超过 1000),thanos-compact 会崩溃并报错。原因是对象存储服务端只支持老版本接口 listObjects,不支持新接口 listObjectsV2。listObjectsV2 要求 IsTruncated 为 true 的时候,同时设置 NextContinuationToken 参数。解决方法对对象存储服务端进行升级修复。可参考 issue,https://github.com/minio/mc/issues/3067
thanos 支持无限扩展存储容量,但考虑到存储的成本,以及较长远的历史数据没有价值。调整不同分辨率数据的保存时间,避免对象存储增长过快。
thanos-compact.yaml
- "--retention.resolution-raw=7d"
- "--retention.resolution-5m=31d"
- "--retention.resolution-1h=0d"
可参考 issue,https://github.com/thanos-io/thanos/issues/813
更新节点 label 后的几分钟内,prometheus 会采集到重复的 metrics,可能会导致 promQL 查询语句失败。在社区中提了 issue,https://groups.google.com/g/prometheus-users/c/WK-wROf3e3g/m/RKy40nFrAQAJ。或许跟使用的 prometheus/node-exporter 版本比较老有关系,可以尝试使用较新的版本。
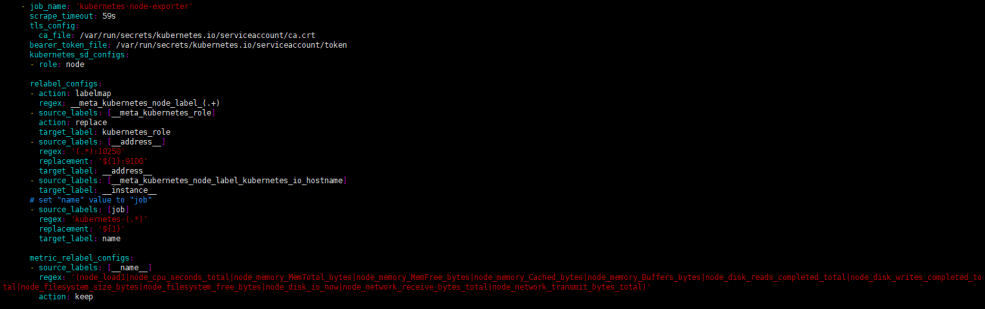
集群规模扩大,prometheus 采集的数据增加,导致其使用内存增加,OOM 风险变大,存储占用增加。并不是所有的容器指标都是有用的,可以根据集群监控 / 运维的需求进行指标筛选,筛掉大部分不需要的指标。通过 prometheus configmap 的 relabel_config 配置相应指标的保留与删除,对于 kube-state-metrics 可以直接在启动参数里配置开启相应的 collector 以及采集标签的白名单。
部分 cadvisor cpu 利用率过高,导致拉取不到容器指标。社区相关 issue:https://github.com/google/cadvisor/issues/1774。原因是读取 cgroup 的 memory.stat 耗费了较多时间,内核内存延迟释放,把内核版本更新到 4.19 及以上就能解决。
部分 node-exporter 采集到的网络收发指标过大,给社区提了 issue,https://github.com/prometheus/node_exporter/issues/1849。社区反馈是内核的问题,node-exporter 只是上报了内核的数据,没有做任何数据变换。节点的内核版本是 3.10.0,建议使用更高版本的内核。
节点负荷高的时候,节点上的 pod 会被 k8s 驱逐。监控 exporter 作为基础组件,应确保不被驱逐。若将 exporter 的 qosClass 设置成 guranteed,又缺乏资源使用的灵活性。因此我们将 node-exporter/cadvisor/dcgm 设置成 critical pod。方法有两种:1.annotations 里配置 scheduler.alpha.kubernetes.io/critical-pod: "";2. 设置 priorityClassName: system-node-critical,需要 exporter 部署在 kube-system 下。
指标获取失败,通常是由于为容器分配的 cpu/ 内存数不足导致的,增加资源即可解决。
容器内存的使用量我们采用了目前大家公认的 container_memory_working_set_bytes 指标,因为 working_set 是 kubelet 判断 OOM 的依据。但 working_set 和容器内用 top 观察,以及程序运行在物理机上的内存都会有差距。大部分情况差距不大,少数情况下会有较大差距,并不是容器指标不准,而是计算方式不同导致的。下面介绍几个我们遇到的 case。
某线上业务,容器内 top 命令看到使用 63GiB,容器监控看内存 77GiB,相差 14GiB。原因是读写文件产生了二十多 G 的 file cache,top RES 不包含 file cache,working_set 包含近期 file cache。通过查看 /sys/fs/cgroup/memeory/memory.stat,可以计算得到 top RES = total_rss,working_set = total_rss + total_cache - total_inactive_file。
某线上业务,容器内 top 统计消耗约 1.2GiB,容器监控查看约 1GiB。原因是 RES 包含共享内存 SHR,多个进程使用同样的共享内存,SHR 被重复计算了。减去被重复计算的 SHR,即可得到正确的值。
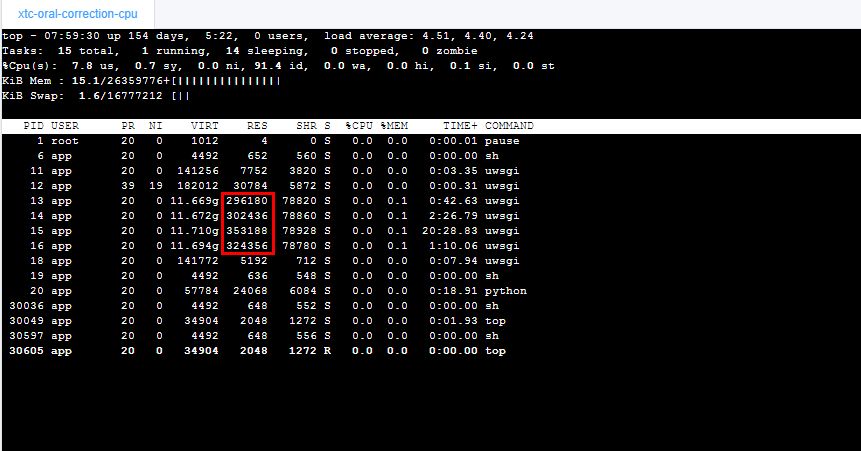
calico 占用大量内存,容器 OOM,导致业务域名不可用,业务受影响。原因是 kmem 未关闭,导致 /sys/fs/cgroup/memory/memory.kmem.usage_in_bytes 值非 0 且较大,而容器内存是把这个值加进去了的,所以导致 OOM。calico 本身并没有内存泄漏。解决方案是 disable 掉 kmem,细节可以参考之前的文章 https://www.infoq.cn/article/2LCOXVLD0WxDN4itXj35
以内存利用率为例,计算规则常采用 container_memory_working_set_bytes / memory.limit_in_bytes。对于 pod,k8s 存在两个资源限制,request 和 limit,二者常不相等。
当涉及资源超卖,limit 做分母是合理的。因为 request 会设置为一个较小的值,便于调度。request 作分母会导致利用率超 100%。
当涉及弹性伸缩,k8s 计算 pod 利用率,是以 request 做为分母的,可参见代码实现,https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/podautoscaler/metrics/utilization.go
当 limit > request,基于 POD 的 CPU/ 内存利用率做弹性伸缩时,是会出现利用率大于 100% 的情况。
作者介绍
汪凯,目前是 vivo AI 研究院计算平台组的工程师,关注 K8s、容器等云原生技术。
专题推荐:
https://www.infoq.cn/theme/93

你也「在看」吗?👇