CVPR'21 | RMNet:又快又好!基于局部特征记忆网络的视频物体分割


CVPR 2021 文章专题
第·15·期
为了解决这个问题,我们提出了RMNet,仅提取目标物体所在区域的特征,并在该区域内进行特征匹配,从而显著减少了对相似物体的错配,并提高了计算效率。

Paper: https://arxiv.org/pdf/2103.12934 Project Page: https://haozhexie.com/project/rmnet GitHub: https://github.com/hzxie/RMNet

一、引言
现有的视频物体分割使用了掩膜传播(Mask Propagation)或者特征匹配的策略估计物体在视频序列中的掩膜。早期基于掩膜传播的方法[1-3]使用光流将物体的掩膜从上一帧传递至下一帧,并使用一个全卷积网络(FullyConvolutional Network)完善估计的物体掩膜。然而基于掩膜传播的方法很容易造成误差累积,特别是当目标物体被遮挡或是漂移时。
近几年,基于特征匹配的方法[4-7]使用全局-全局的特征匹配计算过去帧和当前帧特征相似度和匹配关系。在这些方法中,基于STM(Space-Time Memory)的方法[4-6]将过去帧记忆在网络中,从而更好地应对物体的遮挡和漂移。然而,这些方法也记忆了目标物体之外区域的特征,从而导致了对相似物体的错配,也造成了更高的计算复杂度。
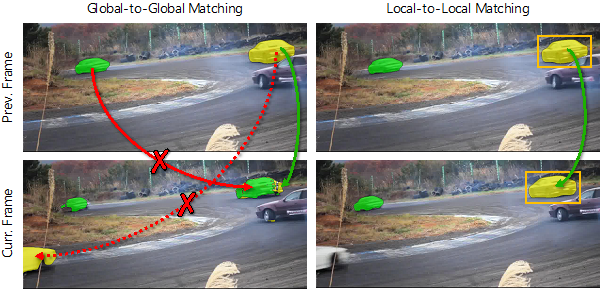
本质上,全局特征所造成的错误匹配可以被分为2种类型,如图1所示:
(I) 在当前帧中的目标物体被错误的匹配至过去帧中的物体(红色实线)
(II) 在过去帧中的目标物体被错误的匹配至当前帧中的物体(红色虚线)
造成这两种类型的错误主要是由于在不必要的区域(即目标物体未出现的区域)进行了特征匹配。事实上,对于每一帧而言,目标物体仅在较小的一个区域内出现,因此在局部区域进行特征匹配是合理的也是必要的。
为了解决这个问题,我们提出了RMNet,仅记忆过去帧中目标物体所在区域的特征,从而有效避免了(I)所描述的错误匹配。为了跟踪和预测当前帧中的目标物体,我们估计了相邻两帧的光流,并将上一帧物体的掩膜通过光流warp至当前帧。通过warp得到的物体掩膜提供了一个大致的目标物体出现区域,从而有效避免了(II)所描述的错误匹配。
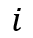 时刻,在特征尺度上目标物体的掩膜可表示为
时刻,在特征尺度上目标物体的掩膜可表示为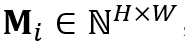 ,则对于第
,则对于第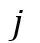 个物体的局部注意力图
个物体的局部注意力图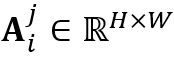 可通过如下方式计算获得:
可通过如下方式计算获得: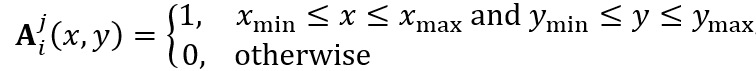
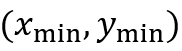 和
和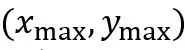 分别表示目标物体边界框左上角和右下角的坐标。这两个坐标是通过如下公式确定的:
分别表示目标物体边界框左上角和右下角的坐标。这两个坐标是通过如下公式确定的: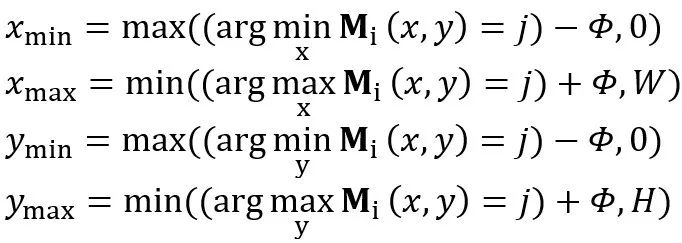
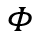 表示边界框的膨胀像素值,它决定了对于所估计的物体掩膜的错误容忍度。特别地,当第
表示边界框的膨胀像素值,它决定了对于所估计的物体掩膜的错误容忍度。特别地,当第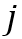 个物体在
个物体在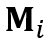 中消失时,我们定义
中消失时,我们定义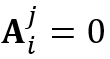 。给定第
。给定第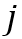 个物体在记忆帧中的局部注意力图
个物体在记忆帧中的局部注意力图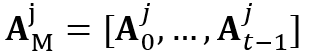 ,局部记忆特征中的局部键
,局部记忆特征中的局部键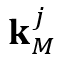 和局部值
和局部值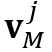 是由记忆编码器生成的局部记忆特征表示和局部注意力图
是由记忆编码器生成的局部记忆特征表示和局部注意力图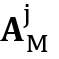 点乘得到的。
点乘得到的。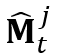 。具体而言,我们将上一帧物体的
。具体而言,我们将上一帧物体的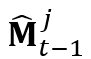 通过所提出的TinyFlowNet估计的光流映射到当前帧,得到当前帧目标物体的掩膜
通过所提出的TinyFlowNet估计的光流映射到当前帧,得到当前帧目标物体的掩膜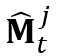 。和局部记忆特征一样,
。和局部记忆特征一样,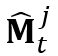 被用于生成查询帧中第
被用于生成查询帧中第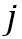 个物体的局部注意力图
个物体的局部注意力图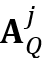 。为了更好地处理对目标物体的遮挡,当目标物体的像素个数小于
。为了更好地处理对目标物体的遮挡,当目标物体的像素个数小于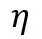 时,我们定义
时,我们定义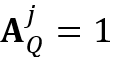 ,这将会在查询帧中触发对目标物体的全局搜索。如图3所示,当目标物体消失时,特征匹配区域(用红色边界框表示)将会被扩展至全图;当目标物体再次出现时,特征匹配区域重新聚焦至包含目标物体的区域。这个机制可以有利于基于光流的跟踪,使得网络可以感知目标物体的消失,使得网络可以对物体的遮挡更加鲁棒。和局部记忆特征类似,局部查询特征中的局部键
,这将会在查询帧中触发对目标物体的全局搜索。如图3所示,当目标物体消失时,特征匹配区域(用红色边界框表示)将会被扩展至全图;当目标物体再次出现时,特征匹配区域重新聚焦至包含目标物体的区域。这个机制可以有利于基于光流的跟踪,使得网络可以感知目标物体的消失,使得网络可以对物体的遮挡更加鲁棒。和局部记忆特征类似,局部查询特征中的局部键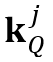 和局部值
和局部值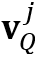 是由查询编码器生成的全局查询特征表示与局部注意力图点乘得到的。
是由查询编码器生成的全局查询特征表示与局部注意力图点乘得到的。
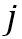 个物体记忆特征中的键
个物体记忆特征中的键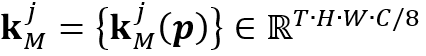 和查询特征中的键
和查询特征中的键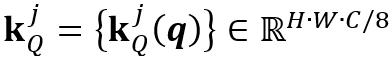 ,则
,则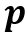 和
和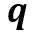 的相似度为:
的相似度为: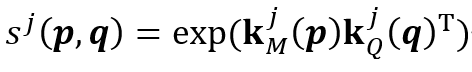
其中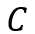 表示特征键中的通道数,
表示特征键中的通道数,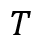 表示记忆帧的数量。令
表示记忆帧的数量。令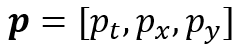 和
和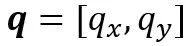 分别表示在
分别表示在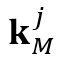 和
和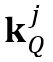 中的索引值,则
中的索引值,则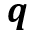 在位置上的查询值可被计算为:
在位置上的查询值可被计算为:
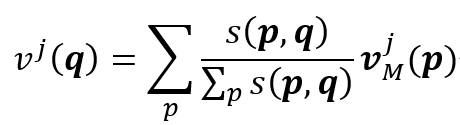
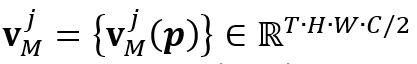 表示记忆特征中的值。最终,时空记忆阅读器在
表示记忆特征中的值。最终,时空记忆阅读器在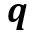 位置上的输出为:
位置上的输出为: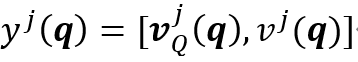
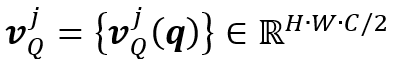 代表查询特征的值;
代表查询特征的值; 表示拼接(Concatenation)。
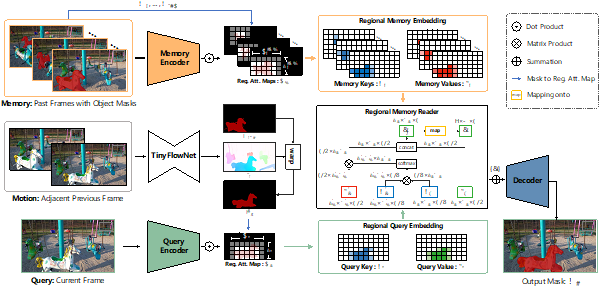
表示拼接(Concatenation)。基于局部特征表示,RMNet中使用了局部记忆阅读器仅在包含目标物体的区域内进行局部-局部的特征匹配,如图2所示。和之前工作中[4-6]使用的全局-全局的记忆阅读器相比,局部记忆阅读器可以减少在记忆帧和查询帧中对于相似物体的错误特征匹配。令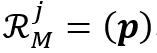 和
和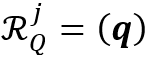 分别表示第
分别表示第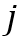 个目标物体在记忆帧和查询帧中进行特征匹配的区域。在全局-全局的特征匹配中,像素之间的相似度是通过一个大矩阵乘法获得的,即
个目标物体在记忆帧和查询帧中进行特征匹配的区域。在全局-全局的特征匹配中,像素之间的相似度是通过一个大矩阵乘法获得的,即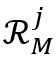 和
和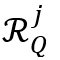 为特征表示键值中的所有位置。而在局部记忆阅读器中,和分别被定义为:
为特征表示键值中的所有位置。而在局部记忆阅读器中,和分别被定义为:
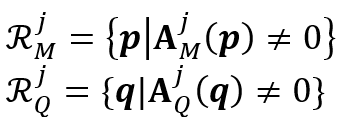
对于满足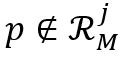 或者
或者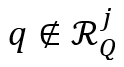 的位置,它们的相似度被定义为:
的位置,它们的相似度被定义为:
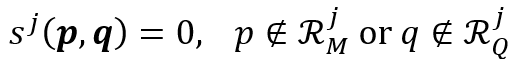
令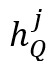 和
和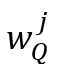 分别表示查询帧中第
分别表示查询帧中第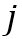 个物体所在区域的高度和宽度,
个物体所在区域的高度和宽度,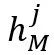 和
和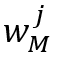 分别表示记忆帧中包含目标物体的区域的最大高度和最大宽度。因此,时空记忆阅读器的时间复杂度为
分别表示记忆帧中包含目标物体的区域的最大高度和最大宽度。因此,时空记忆阅读器的时间复杂度为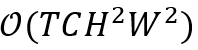 。相比之下,局部记忆阅读器的时间复杂度被减小至
。相比之下,局部记忆阅读器的时间复杂度被减小至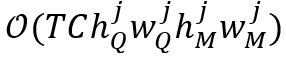 。如图4所示,
。如图4所示,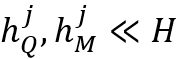 且
且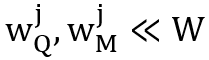 。时空记忆阅读器本质上是一个非局部神经网络(Non-LocalNeural Network),而它经常因为全局-全局特征匹配所导致的高计算复杂度被人诟病;而所提出的局部记忆阅读器通过局部-局部的特征匹配使得其的时间复杂度显著降低。
。时空记忆阅读器本质上是一个非局部神经网络(Non-LocalNeural Network),而它经常因为全局-全局特征匹配所导致的高计算复杂度被人诟病;而所提出的局部记忆阅读器通过局部-局部的特征匹配使得其的时间复杂度显著降低。
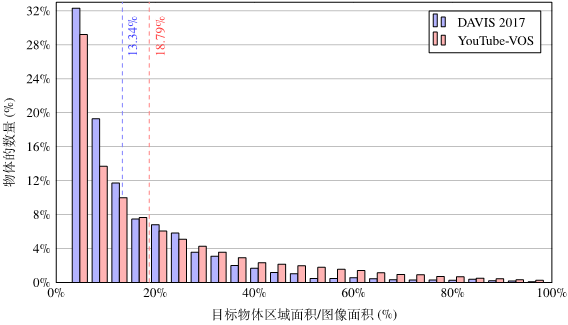
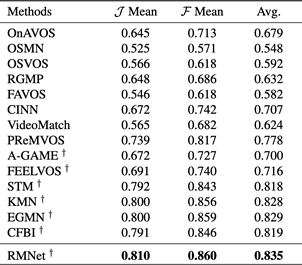
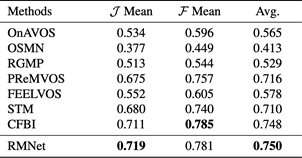 表2 DAVIS 2017测试集的量化结果
表2 DAVIS 2017测试集的量化结果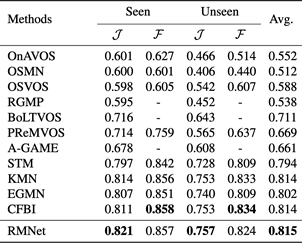 表3 YouTube-VOS(2018版本)验证集的量化结果
表3 YouTube-VOS(2018版本)验证集的量化结果
[1] Hu et al. MaskRNN: Instance level video object segmentation.NIPS2017.
[2] Luiten et al. PRe- MVOS: Proposal-generation, refinement and mergingfor video object segmentation. ACCV 2018.
[3] Perazzi et al. Learning video object segmentation from staticimages.CVPR 2017.
[4] Oh et al. Video object segmentation using space-time memory networks.ICCV 2019.
[5] Seong et al. Kernelized memory network for video objectsegmentation. ECCV 2020.
[6] Lu et al. Video object segmentation with episodic graph memorynetworks. ECCV 2020.
//
作者介绍
谢浩哲,目前于哈尔滨工业大学计算学部攻读博士学位。他以第一作者身份在CVPR、ICCV、ECCV、IJCV等计算机视觉顶级会议和期刊上发表多篇论文。他的研究方向主要包含3D重建、语义分割和计算机视觉。
个人主页:https://haozhexie.com/about
CVPR 2021 论文解读 ●●
// 1
// 2
// 3
// 4
// 5
// 6
// 7
// 8
// 9
// 10
// 11
// 12
// 13
// 14

扫码观看!
本周上新!

关于我“门”
