MVS开始"变形"了!基于Transformer的多视角三维重建算法参数减量质更优!

论文链接: https://arxiv.org/pdf/2103.12957.pdf

一、多视角三维重建问题
通过不同视角下对目标的观测图像,理论上可以重建出目标的三维信息,但传统方法需要精确的标定相机或抽取不同视角下的相对位姿,使得算法不够稳定、计算量过大、实现较为复杂。深度学习特别是卷积神经网络强大的特征抽取能力为多视角三维重建提供了新的可能。
为了从多个视角的观测结果中学习出目标的3D表达,绝大多数基于CNN的架构都采样了分治法,即先通过编码器提取出不同视角下的特征表达,而后通过融合过程将不同视角下的特征进行整合重建出目标的三维形貌。尽管两个过程紧密相关,但其设计思想却是独立的没有考虑不同视角下观测结果的相关性。虽然最近有研究利用RNN探索了不同视角下的关系,但庞大的计算量使得效率低下,输入排序敏感性使得它在处理无序的视角时候十分困难。此外,基于CNN的方法还无法有效处理模型缩放问题,当模型大小超过特定尺度时其精度会出现饱和,这显示出了单纯通过大量独立的CNN特征难以学习出互补的知识。
二、3D Volume Transformer
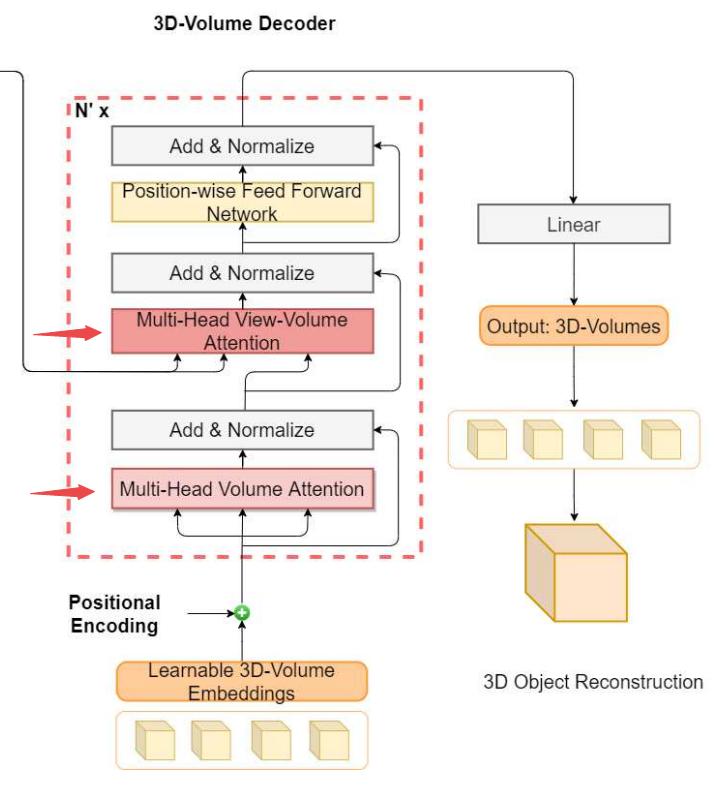
这一新的架构主要包含了两个部分:2D视角的transformer编码器和3D体积的transformer解码器。
其中2D部分的编码器主要负责从抽取2D视角下的特征,并通过探索2D视角间的关系对不同视角下的特征进行融合。而3D部分的解码器则通过对编码器的特征进行融合与解码,并为每个空间位置的查询token生成3D概率体素输出。解码器中的自注意力机制将主要学习每个输出体素栅格和输入视角间的2D视角-3D体积相关性;同时体积自注意力层则会通过学习不同空间位置的相关性来得到3D体积-3D体积间的相关性。2D-2D,2D-3D,3D-3D的相关性可以进行通过编码器和解码器中的多注意力层进行联合探索。
下图展示了本文提出模型的主要框架结构。
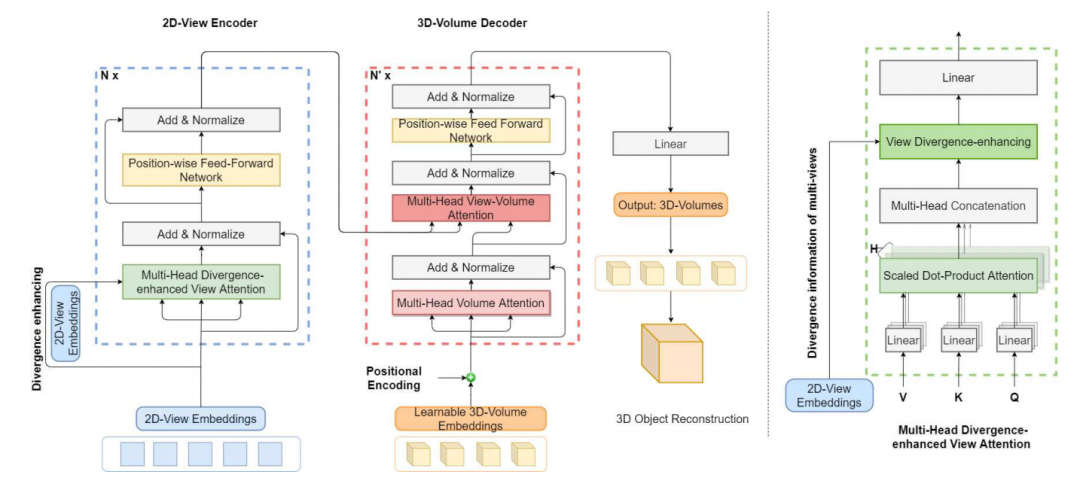
图中的左半部分是整个模型的主体架构,右半部分展示了本文提出用于抑制模型表达收敛的 divergence enhanced Transformer模块
下面的公式对编码过程进行了比较简洁的描述:
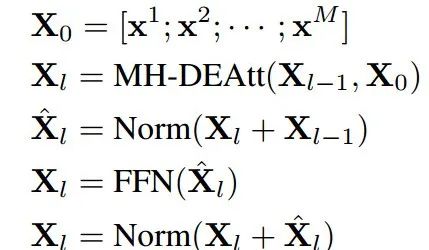
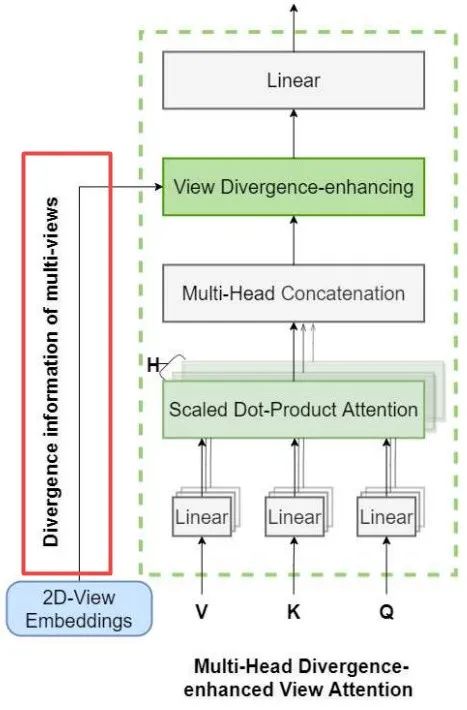
值得一提的是,在使用原始Transformer时候,特征会随着层数的增加而逐渐收敛,这使得模型会失去表达能力,使得模型无法有效探索不同视角间的相关性。为此研究人员特别提出了一种减缓收敛的机制,通过增大不同视角的embedding差异来实现。这一机制通过在输入的特征空间中引入跳接并衔接不同视角的特征来实现。
下图中左下角的支路展示了这一过程。
而针对解码器来说需要重建目标的三维形貌,那么将一系列3D体积位置编码为查询序列,并添加了对应的位置编码,其主要的流程和编码器类似,通过将体积embedding输入多头体积注意力层进行编码,而后通过归一化再于视角编码共同输出到体积视角编码,随后归一化前向传播得到最后解码结果,并通过线性映射还原为对应的3D体积,而后按照对应位置排布得到最终的重建结果。
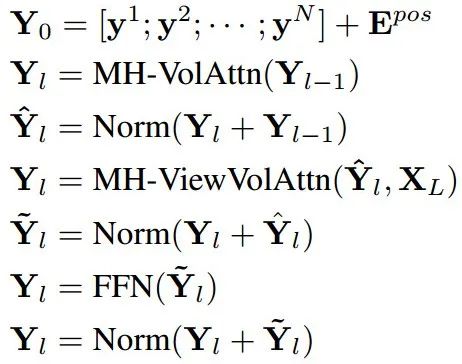
细节架构可以看到这一解码器主要探索了3D-3D以及2D-3D间的相关性。
为了对比不同实现方式的差异,研究人员分别实现了三种不同的VoIT,其中利用VGG16抽取特征并利用原始Transformer编码的结果VoIT,利用更为先进的ResNet50作为特征抽取的VoIT+,以及通过视角嵌入学习收敛抑制提升的EVoIT模型。下表展示了这些模型与先前模型的参数量比较,可以看到最先进的EVoIT只有传统方法不到30%的参数量。

三、实验结果
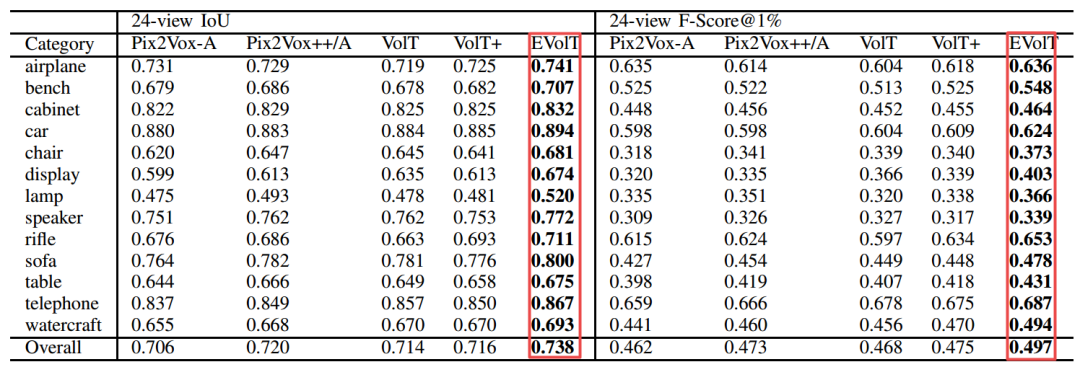
研究人员在ShapeNet上对24个视角的情况进行了重建实验,结果超过了先前的Pix2Vox等模型,在几乎左右类别上都达到了最佳效果。
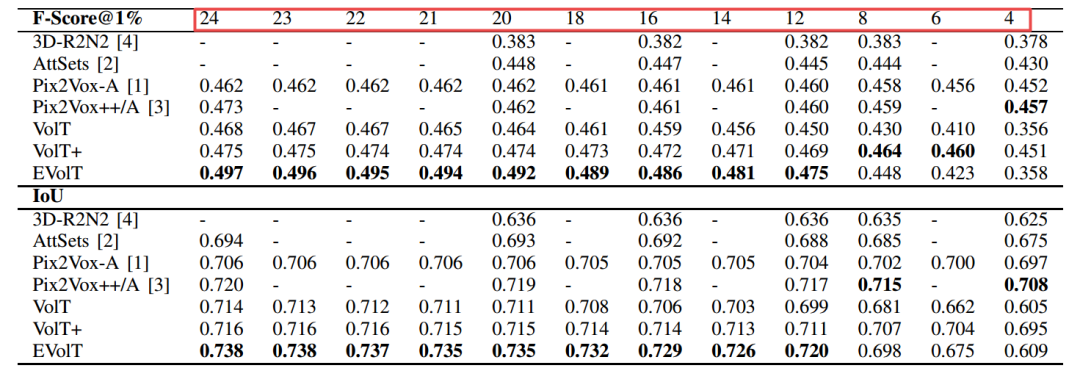
同时这一方法也在视角数量变化时展示了较强的鲁棒性:
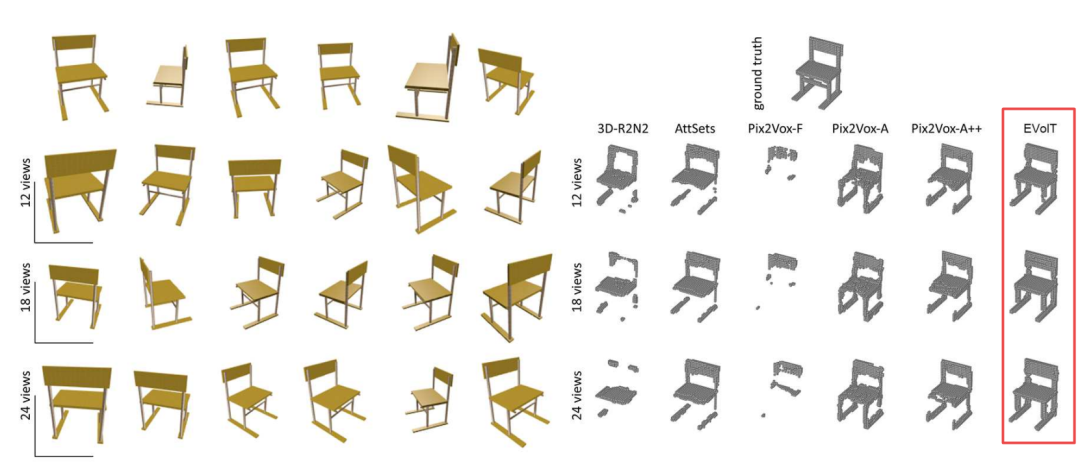
下图展示了这一方法的重建结果,可以看到完整性和精度都有较大的提升:
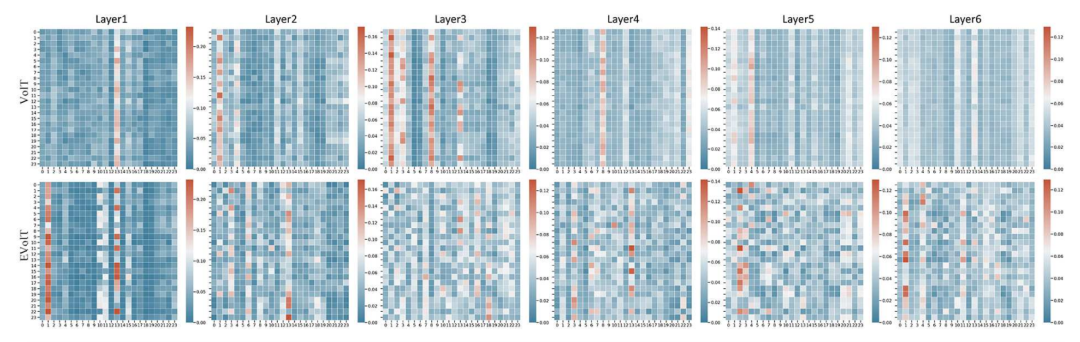
为了展示收敛抑制模块的作用,通过对于注意力矩阵的可视化分析可以发现,相比于VoIT,EVoIT的列还保持着较强的多样性,没有出现对于特定视角的强化表达。这意味着通过抑制收敛可以提升更深层对于多视角特征的多样性表达。
在未来研究人员还会在模型的可解释性方面进行进一步探索,并通过可视化的方式对于隐空间变量与输入间的对应关系进行更为深入的分析。如果想要了解更多细节,请参看论文。
Illustrastion by Oleg Shcherba from Icons8

扫码观看!
本周上新!

关于我“门”
