随身携带的动捕系统!基于稀疏惯性传感器的实时人体动作捕捉 | SIGGRAPH 2021
作者 | 伊昕宇
AI科技评论报道
本文是对发表于计算机图形学顶级会议SIGGRAPH 2021 的论文《 TransPose: Real-time 3D Human Translation and Pose Estimation with Six Inertial Sensors 》的解读。
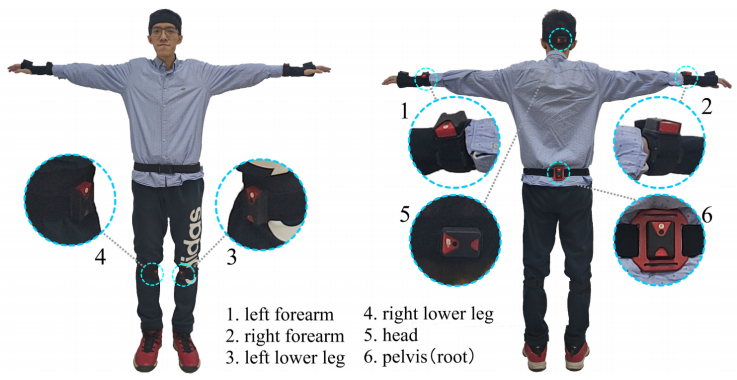
该工作由清华大学徐枫团队完成,使用仅6个惯性测量单元(Inertial Measurement Unit,IMU)进行实时人体动作捕捉,实现了三维人体姿态和全局运动的估计。
该系统在已有方法中达到了最高的估计精度、运行速度以及平滑程度,并且首次完成了基于稀疏惯性传感器的实时全局运动估计。
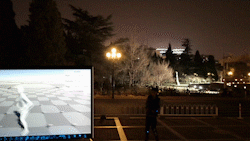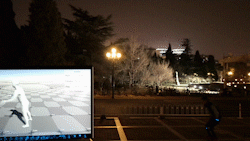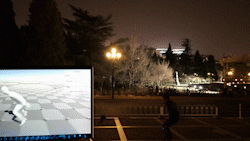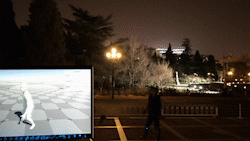
该系统使得普通消费者只需要穿戴少数量的IMU,就可以进行大范围、长时间的动作捕捉,不受到多人环境、光线、遮挡等限制。

论文链接:https://arxiv.org/abs/2105.04605
1
研究背景
人体动作捕捉在很多领域(如游戏、体育、电影等)都有着重要的应用。目前商业的动捕系统(如Vicon、Xsens)通常需要昂贵的基础设施或侵入性的设备,并不适合日常的使用。最近大量的研究工作使用更加轻量、便宜的彩色或深度相机进行人体动作捕捉,但这些方法严重依赖于外部相机的摆放,受照明条件、遮挡、环境影响,而且大部分系统将人的运动限制在一个能被相机捕获到的固定空间中,一些日常活动如户外散步或坐在桌子后办公不能被这样的系统捕获。这些缺点大大降低了基于视觉的动捕系统的可用性。
为了使普通消费者也可以随时随地进行动作捕捉,本文提出了一个基于6个惯性测量单元的实时动捕系统。
惯性测量单元(Inertial Measurement Unit,IMU)存在于可穿戴智能设备(如智能手表、手环、眼镜、耳机)中,手机等电子设备也都内置了 IMU,而且随着智能可穿戴设备的发展IMU将会非常普及。
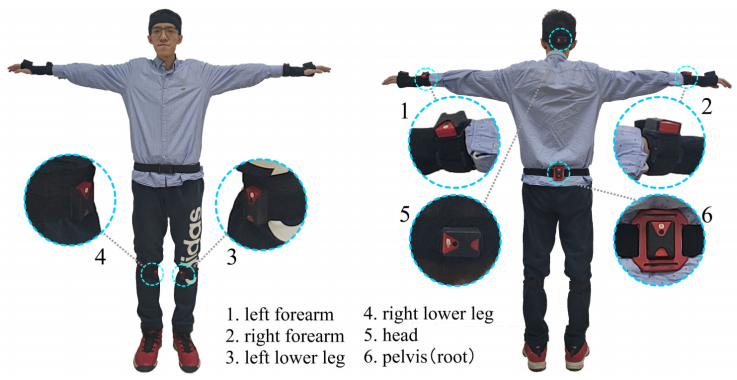
本文将6个IMU设备穿戴在人体的手腕、小腿、头部和后背处,实时捕捉人体姿态和全局运动。该系统可以在强遮挡、广范围、暗环境和多人交互场景中进行鲁棒的、准确的动作捕捉。



2
方法简介
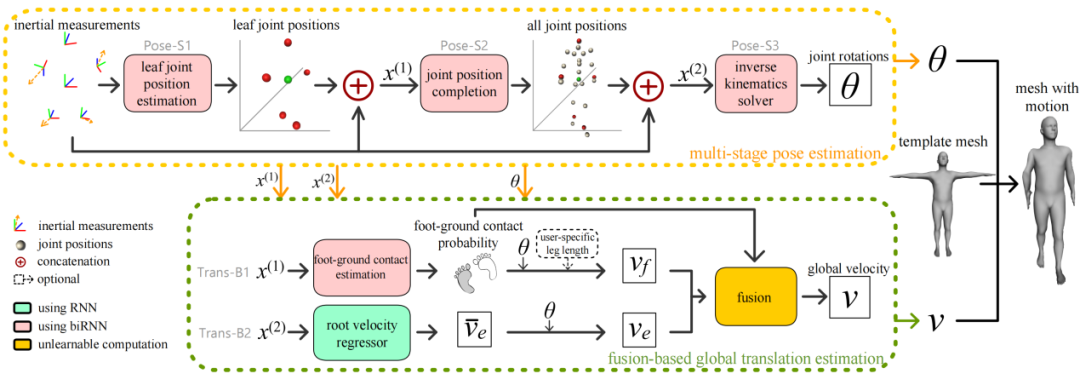
整体结构
系统的输入是6个IMU测量的(校准后的)加速度和角度值,系统的输出是人体姿态(即每个关节的旋转)和全局运动(即人体根节点的位移)。
从稀疏的惯性测量值估计出人体全身的运动是一件非常困难的事,比如当人保持坐着和站着时,这些惯性传感器的测量值可以是相同的,但人体姿态却是完全不同的。为了解决这个歧义就必须要充分利用运动的时序信息和人体姿态先验。本文将动作捕捉任务分解为人体姿态估计和全局运动估计两部分,估计的结果可以直接驱动三维模型运动,无需做任何平滑处理。
对于人体姿态估计,本文提出一个三阶段的方法:
在第一阶段,本文使用一个双向循环神经网络(bidirectional Recurrent Neural Network, biRNN)从6个IMU测量得到的加速度和角度值估计人体末端关节(手腕、脚踝和头顶)相对于根节点的位置;
在第二阶段,本文使用一个biRNN网络以上一阶段估计的末端关节位置结合输入的IMU信息来推断人体全部关节相对于根关节的位置;
在第三阶段,本文使用biRNN网络从全部关节位置和IMU测量值估计人体姿态参数,即所有关节相对于根关节的旋转。对于输入中IMU测得的旋转,本文使用三维旋转矩阵表示;对于姿态估计第三阶段的输出,本文使用6维旋转表示[1],因为该旋转表示具有很好的连续性。对于根节点的全局旋转,本文直接使用位于根节点处的IMU测量得到的旋转值。
对于全局运动估计,本文提出一个物理约束——网络求解的融合方法:
在基于物理约束的分支中,本文用一个biRNN网络以末端关节坐标(姿态估计的中间结果)和IMU测量值作为输入,估计出双脚分别和地面接触的概率值。该分支假设接触概率较大的脚为支撑身体的脚,该脚在相邻两帧中不会发生滑动,因此该分支利用相邻两帧估计出的姿态,通过固定支撑脚的位置使用正向动力学计算出根节点的位移。
在基于网络求解的分支中,本文使用一个单向循环神经网络直接从估计出的全身关节坐标和惯性测量值预测出根节点在相邻两帧之间的本地(根节点坐标系中的)位移,并利用根节点的旋转变换到世界坐标系中。这里使用单向RNN的原因是本文发现运动估计需要更长的历史信息,而使用双向RNN处理足够长的历史信息时不能满足实时的运行速度需求。
最后,本文使用第一个分支中预测的支撑脚概率值对两个分支的运动预测结果作插值。
具体而言,当脚与地面接触的概率较大时,本文选择基于物理约束的分支预测的运动结果;当双脚与地面接触的概率较小时,本文选择基于网络估计的分支预测的运动结果;当支撑脚的概率位于中间值时,本文使用该概率值进行两个预测的线性插值,从而得到两个分支平滑的融合和过渡。实验证明,该方法可以很好的处理绝大部分运动,结果自然合理。
3
实现细节

循环神经网络结构图
对于每个循环神经网络(RNN),本文都使用相同的结构(见上图),其中每个RNN包括对输入的Dropout,一个输入线性变换层(使用ReLU激活函数),两个长短时记忆网络层(Long Short-Term Memory,LSTM),和一个输出线性变换层。
对于全局运动预测的分支一,该网络的输出层使用 Sigmoid 激活函数来输出概率值,其余情况均使用线性激活函数。
在训练时,姿态估计的三个RNN网络均使用L2损失函数进行训练,运动估计的分支一使用交叉熵损失函数进行训练,分支二同时考虑连续1, 3, 9, 27帧中的累计位移并使用L2损失函数进行训练:
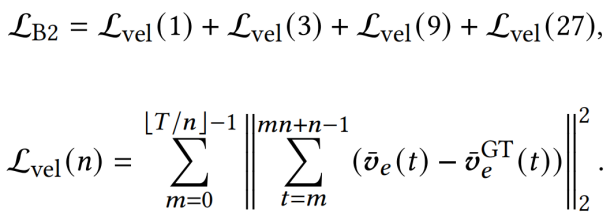
运动估计分支二的损失函数:T 为训练序列的总帧数,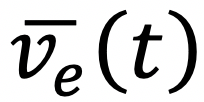 为第t帧中根节点的位移。上标
为第t帧中根节点的位移。上标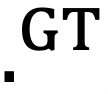 表示真值。
表示真值。
对于数据集,本文使用AMASS[2]和DIP-IMU[3]作为训练集,使用DIP-IMU和TotalCapture[4]作为测试集,其中AMASS数据集不包括IMU信息,DIP-IMU数据集不包括全局运动信息。
因此我们在AMASS数据集中放置虚拟的惯性传感器,人工生成惯性测量值(加速度和旋转),并对AMASS和TotalCapture数据集生成支撑脚的标注,其中我们假定相邻两帧中脚的位移小于一个确定阈值则标记为支撑脚。每个数据集都以60帧/秒进行采样。
特别的,由于运动估计的两个分支是互补的,我们使用训练好的分支一网络筛选出存在双脚离开地面的序列作为分支二的训练数据,从而减轻分支二的学习任务来获得更好的效果。数据集的信息如下
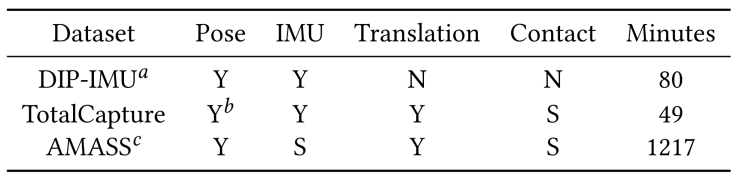
数据集信息。Y/N表示数据集存在/不存在该项信息,S表示使用其他信息人工综合得到
由于实际在线使用时我们无法获知无限多未来的惯性信息,本文使用一个滑动窗口策略,将最近20个历史帧、1个当前帧和5个未来帧(通过83毫秒的延迟获取)作为系统输入,预测出当前的姿态和全局运动信息。
本文也可以选择将惯性信息完整的录制下来,并使用系统离线的进行处理,此时系统可以获取到完整的序列信息,预测出更好的结果。
4
实验结果
本文在两个应用场景中进行测试:离线场景,即完整的序列信息是已知的;在线场景,即每个时刻只能获取到5个未来帧。本文在DIP-IMU[3]测试集和TotalCapture[4]数据集上进行姿态的测试,与基于优化的方法SIP/SOP[5]和前人工作中最好的基于学习的方法DIP[3]进行了详细的对比。
本文测试了SIP Error(大臂、大腿的旋转误差),Angular Error(所有关节旋转误差),Positional Error(所有关节位置误差),Mesh Error(模型顶点位置误差)以及Jitter(抖动程度),定性和定量结果如下图表。
本文的方法在所有的测试指标上均超过前人工作,并且达到了最快的运行速度(90帧/秒)。

离线场景的姿态定量测试

在线场景的姿态定量测试
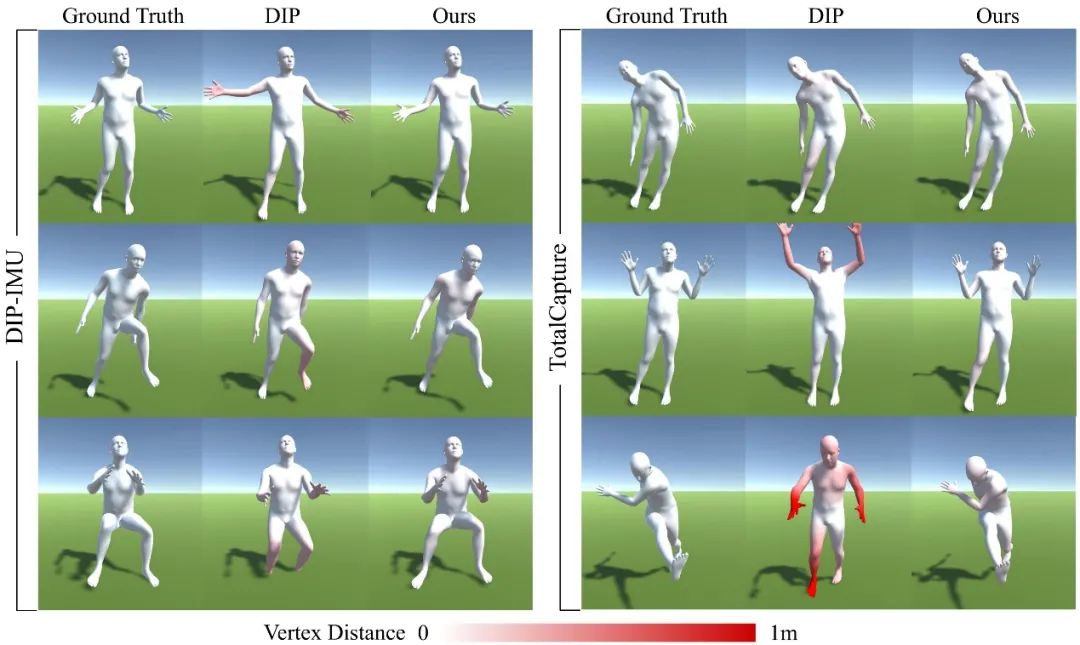
在线场景与DIP[3]的定性对比:红色深度表示顶点的误差。
本文还进行了消融实验证明了三阶段姿态预测的有效性、IMU跨层连接的作用、基于融合方法的运动求解的有效性,以及运动估计分支二使用单向RNN相比于双向RNN的优势。对于全局运动的测试,本文在TotalCapture数据集上对比了t秒内累计位移误差随t变化的曲线,证明了融合方法的有效性。
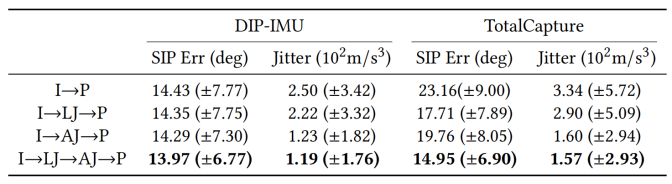
三阶段姿态预测有效性的证明。I表示IMU,LJ表示末端关节坐标,AJ表示全部关节坐标,P表示姿态参数。
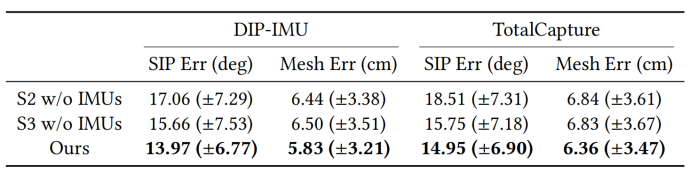
IMU跨层连接的作用:S2/S3表示姿态估计第二/三阶段。
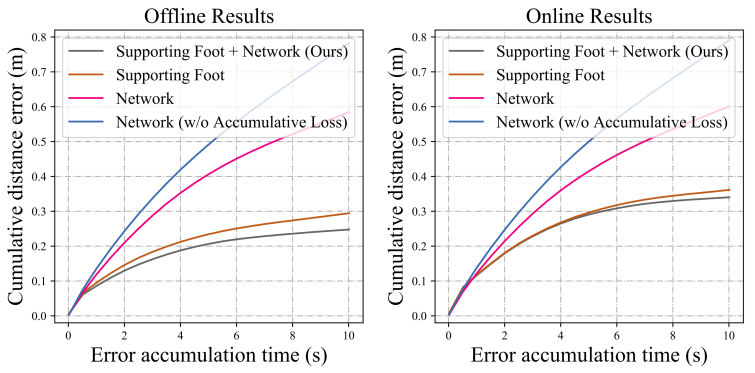
基于融合方法的运动求解的有效性
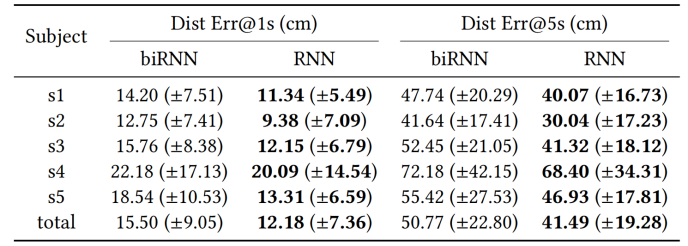
运动估计分支二单/双向RNN的对比
5
总结
本文提出了一种基于6个惯性传感器的90帧/秒的运动捕捉技术,该技术可以重建包括身体姿态和全局平移在内的完整人体运动。
本文使用多阶段姿态预测和物理——网络融合方法求解全局运动,使得系统在现有工作中具有最高的准确性、时间一致性和运行时性能,并首次实时解决了基于稀疏惯性传感器的全局运动估计问题。
大量实验与实际效果证明了本文技术的鲁棒性和准确性。
参考文献:
[1] Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. 2018. On the Continuity of Rotation Representations in Neural Networks. CoRR abs/1812.07035 (2018).
[2] Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. 2019. AMASS: Archive of Motion Capture as Surface Shapes. In The IEEE International Conference on Computer Vision (ICCV).
[3] Yinghao Huang, Manuel Kaufmann, Emre Aksan, Michael Black, Otmar Hilliges, and Gerard Pons-Moll. 2018. Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time. ACM Transactions on Graphics 37,1–15.
[4] Matthew Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton, and John Collomosse. 2017. Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors.
[5] Timo Marcard, Bodo Rosenhahn, Michael Black, and Gerard Pons-Moll. 2017. Sparse Inertial Poser: Automatic 3D Human Pose Estimation from Sparse IMUs. Computer Graphics Forum 36(2), Proceedings of the 38th Annual Conference of the European Association for Computer Graphics (Eurographics), 2017 36 (02 2017).
