管中窥“视频”,“理解”一斑 —— 视频理解概览
以下文章来源于PaperWeekly ,作者Lingyun Zeng
PaperWeekly是一个推荐、解读、讨论和报道人工智能前沿论文成果的学术平台,致力于让国内外优秀科研工作得到更为广泛的传播和认可。社区:http://paperweek.ly | 微博:@PaperWeekly
本文通过对视频理解/分类(Video Understanding / Classification)的基础和经典论文进行梳理,帮助把握整体发展走向。
1. 背景
3D 卷积和 2D 卷积的区别:3D 卷积核多了一层深度的维度,用以提取时间序列信息(包含光流变化等) 2D 卷积核 shape:(channels,k_height,k_width) 3D 卷积核 shape:(channels,k_depth,k_height,k_width) ,与 2D 卷积核的本质区别在于是否在 depth 维度进行滑动(可以把 2D 卷积看作 3D 卷积的特殊形式)

流程:密集采样特征点,特征点轨迹跟踪,轨迹特征提取。
在 DT 算法上进行改进:光流图像优化,特征归一化方式改进,特征编码方式改进(目前一些深度学习方法 ensamble iDT 后会有提升)。
1. 光流图像优化:由于相机运动,背景也存在很多轨迹信息,会对前景的特征采样造成影响。因此 iDT 专门去除了背景上的特征点。(通过估计相机运动,来消除背景区域的光流);
2. 特征归一化方式改进:使用 L1 正则后再开方,提升约0.5%。(DT 算法使用 L2 范式进行归一化);
3. 特征编码方式改进:使用 Fisher Vector 方式编码(DT 算法使用 Bag of Features)。

论文标题: Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks 论文来源: ICCV 2017 论文链接: https://arxiv.org/abs/1711.10305 代码链接: https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
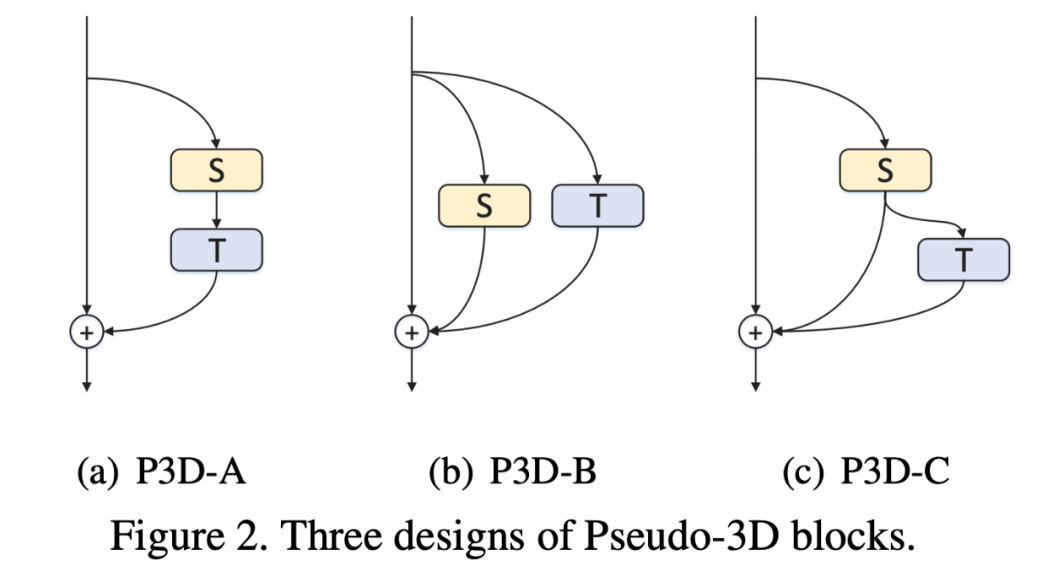
2.4.3 R(2+1)D模型

论文标题: A Closer Look at Spatiotemporal Convolutions for Action Recognition 论文来源: CVPR 2018 论文链接: https://arxiv.org/abs/1711.11248 代码链接: https://github.com/facebookresearch/VMZ
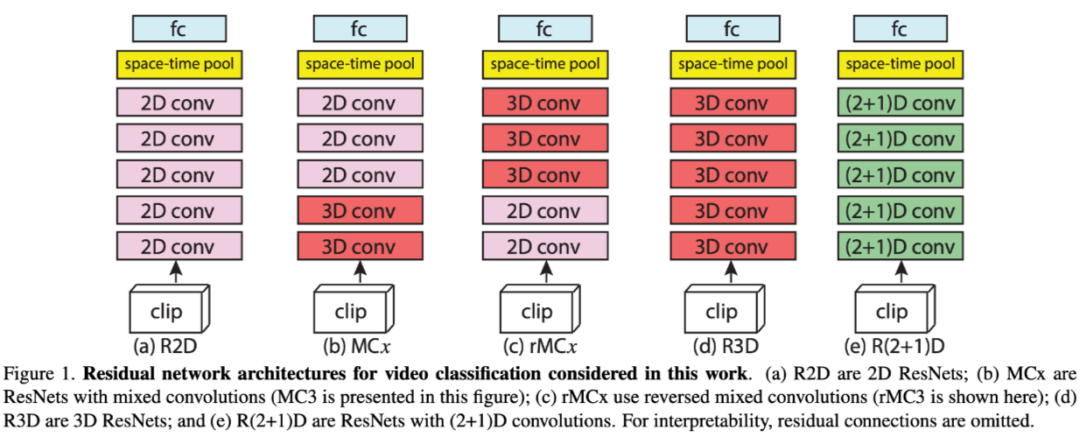
R2D:4 维张量 reshape 成 3 维张量处理;
MCx:认为动作建模在浅层更必要;
rMCx:认为动作建模在深层更必要;
R3D:在所有层都使用 3D conv 进行动作建模;
R(2+1)D:3D conv 解耦为 2D conv 和 1D conv。
好处:(a) 解耦后增加 relu 层,增加了非线性操作,提升网络表达能力 (b)解耦之后更容易优化,loss 更低。
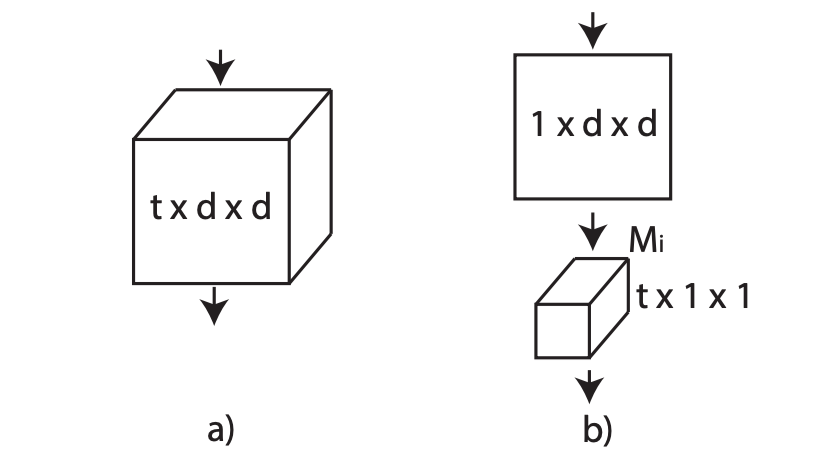
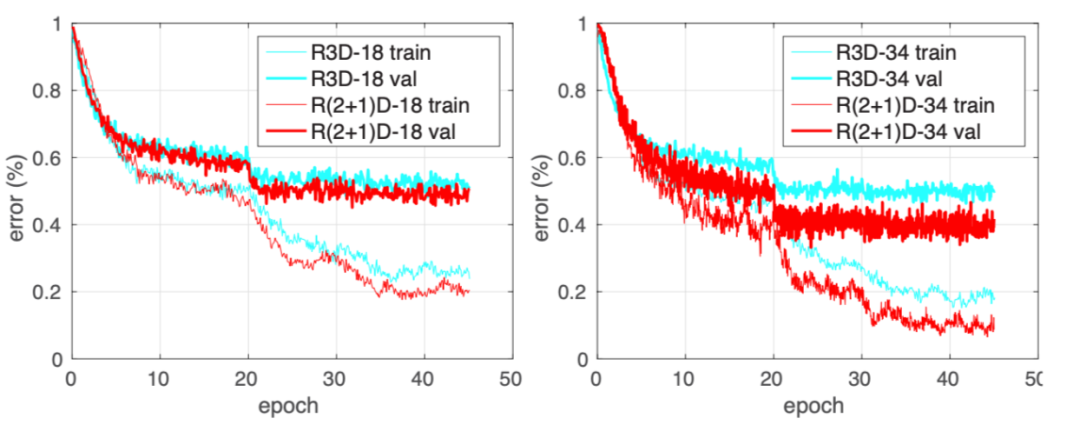
3. 视频理解-经典论文梳理
3.1 ICCV 2015

论文标题:
Unsupervised Learning of Visual Representations using Videos 所属领域:
无监督学习(利用视频数据,ICCV 2015) 论文链接:
https://xiaolonw.github.io/papers/unsupervised_video 代码链接: https://github.com/xiaolonw/caffe-video_triplet
Background
大量视觉任务使用监督学习或者半监督的方法来提取特征,并且大部分基于 image。
Motivation
Method
提出了 siamese network,三个子网络共享权重,和 AlexNet 结构类似,在 pool5 后面接了 4096 和 1024 维的全连接层,即每个视频 patch 最终被映射为 1024 维的向量。
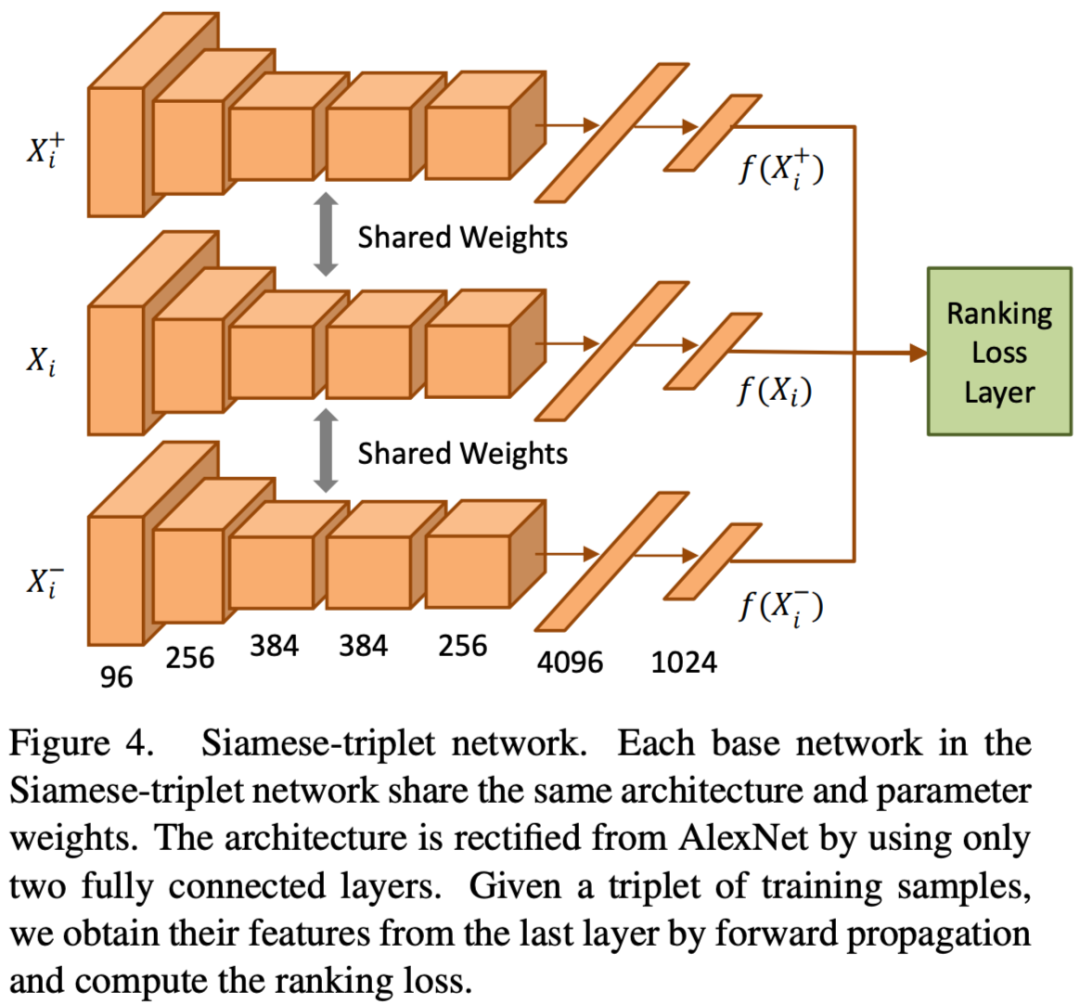
Input:pair of patches(size:227x227,从视频帧中提取)
Output:3 个 1024 维向量
Loss Function:正则化项 +cos 距离项
1. 提取感兴趣的 patch(即包含我们想要的 motion 的部分),并跟踪这些patches,以此来创建 train instances。
● 提取 patch:采用 two-step approach:
(1) 获取 SURF 特征点,然后使用 IDT [1] 中单应性估计方法获取每个 SURF 特征点的轨迹。
说明:之所以使用这个方法,是因为 youtube 视频包含很多相机移动的噪声。IDT 这一步专门去除了相机运动信息。
(2) 获取了 SURF 点的轨迹后,将移动幅度大于 0.5 像素的点归类为 “moving” 。
(3) 帧过滤:过滤掉(a)包含 moving 类的 SURF 点低于 25%(可能这些是噪声点) 和(b)包含 moving 类的 SURF 点高于 75% 的帧(可能都是相机的运动)。
(4) 用 227x227 的 bbox 做 sliding window,提取包含最多 moving 点的 bbox 作为该帧的 patch。
● tracking:
使用 KDF tracker [2] 对前面获得的 patch 进行跟踪,track 的第一帧和最后一帧会作为 pair of patches 进行训练。
2. 如何选择 negative 样本
(1) 先随机选择:对每个 pair of patches,在同一个 batch 中随机选择 K 个 patch 作为 negative patch,得到 K 个 triplet。每个 epoch 都进行 shuffle,确保每 个pair of patches 都能和不同的 negative patch 组合。
(2) 训练大概 10 个 epoch 后,进行 hard negative mining。对每个 pair of patches,将它们和同一个 batch 中其他的 patches 过网络前向计算,根据 loss (下图 loss)的大小进行排序,选取 loss 最大的前 K 个(此处 K=4)patch 作为 negative patch。使用这 K 个 patches 进行后续的训练。
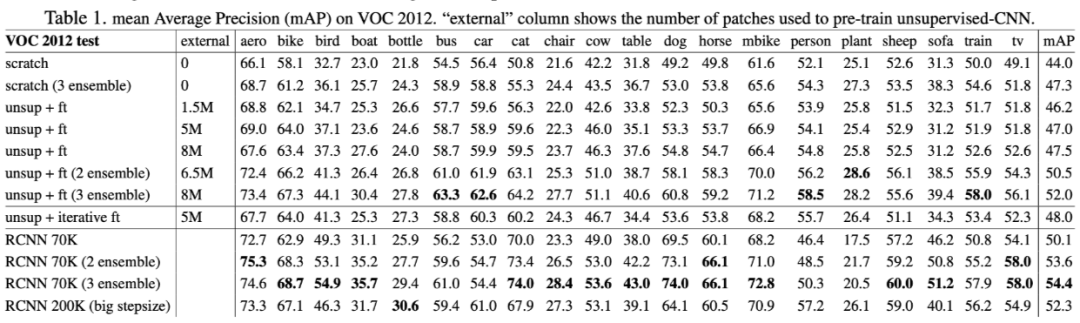
1. 直接使用 VOC 训练,mAP 44.0%;ensemble 3 个模型后,mAP 47.3%(+3.3)。
2. 无监督方法的预训练模型 +VOC finetune, mAP 46.2%;增加无监督训练数据后,mAP 47.0%(+0.8)以及 47.5%(+1.3),证明无监督模型对特征提取有益。
3. 在 VOC 上 retrieval rate 40%(ImageNet 预训练模型:62%,但是它已经学习过 semantics 了)。


论文标题:
TSN-Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
所属领域:
动作/行为识别(基于视频,ECCV 2016) 论文链接:
abs/1608.00859
代码链接:
https://github.com/ZJCV/TSN
Background
基于图片的动作识别已经取得了良好效果,但基于视频的研究并没有太大突破。作者认为主要瓶颈在于以下三个方面:
1. 长时间段的视频结构包含了丰富的动态行为信息,但目前的主流研究方法,在实际应用中,受限于计算资源的限制,只能基于短时间段的序列,会丢失一些长时间段中的信息。 大部分在这个方面进行的研究,基于密集的时间间隔采样:会带来巨大的计算开销,在实际应用场景中不适合。
2. 好的网络模型需要大量的训练数据,目前(论文发表时)只有 UCF101, HMDB51 数据集,数据量和类别种类都不够。
3. 视频的动作分类模型还没有深层网络(相比于图像分类模型来说),训练深层网络容易造成过拟合。
1. 设计一种高效的,适用于长时间段视频的模型;
2. 在有限的训练数据下实现卷积网络的学习。
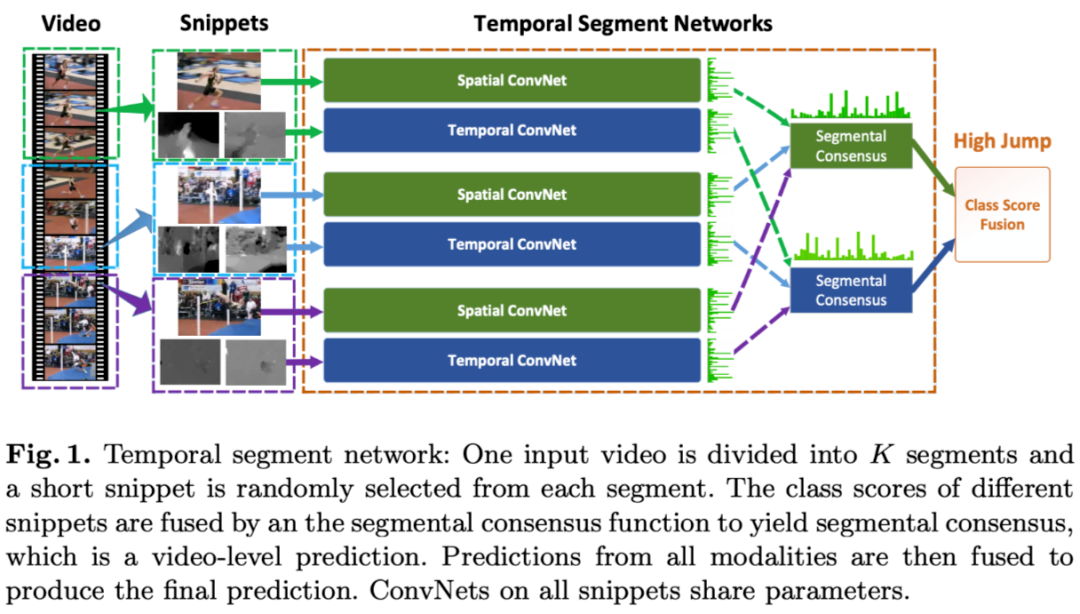
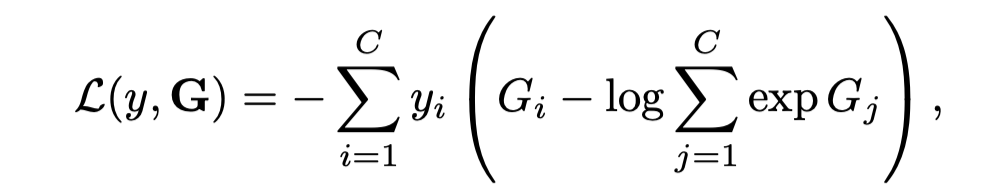
视频的光流特征使用 OpenCV TVL1 optical flow algorithm 进行提取。
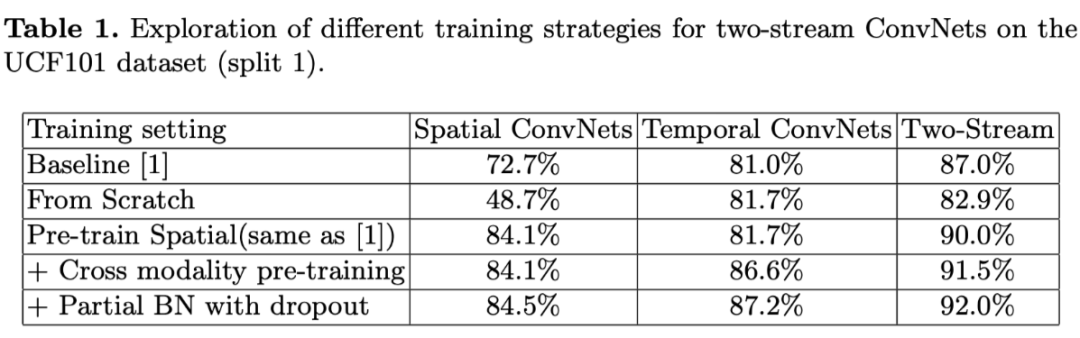
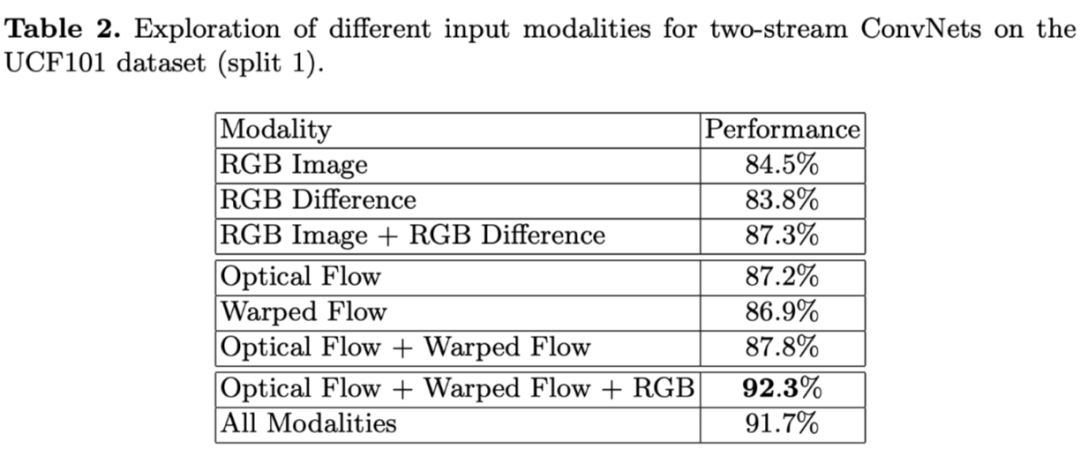
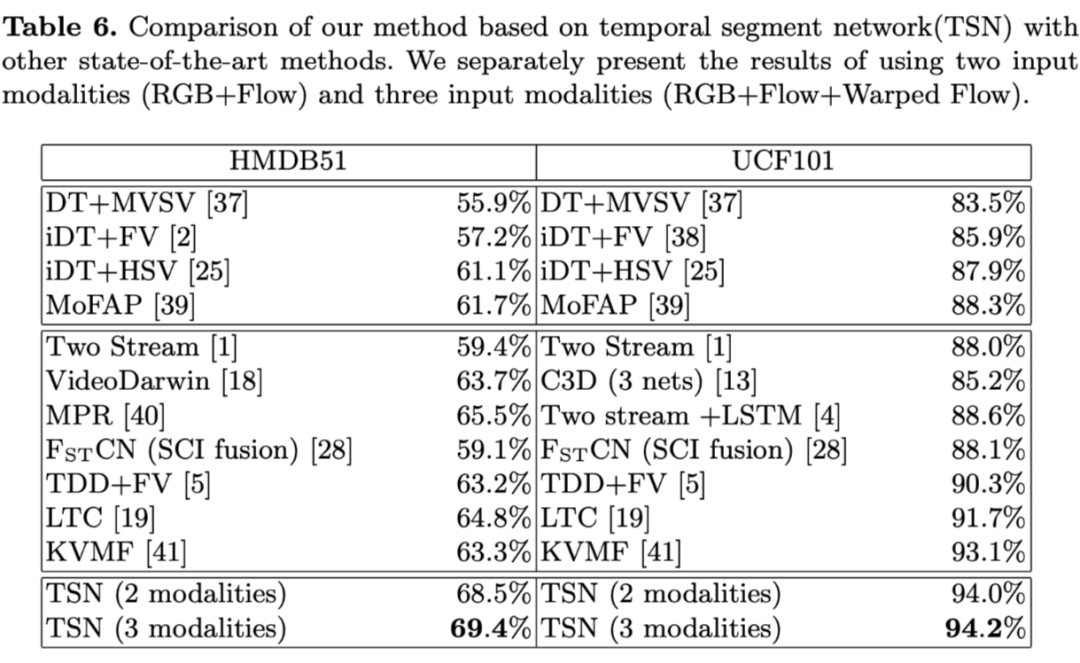
1. 对输入模式和训练策略进行实验,结论
(1)使用 Cross modality 和 partial BN with dropout 的方案可以提升精度
(2)融合光流、wrap 光流、RGB 输入的结果精度最高,92.3%(加 RGB difference 会掉点,如果对计算资源有严格要求的时候可以考虑使用) 。
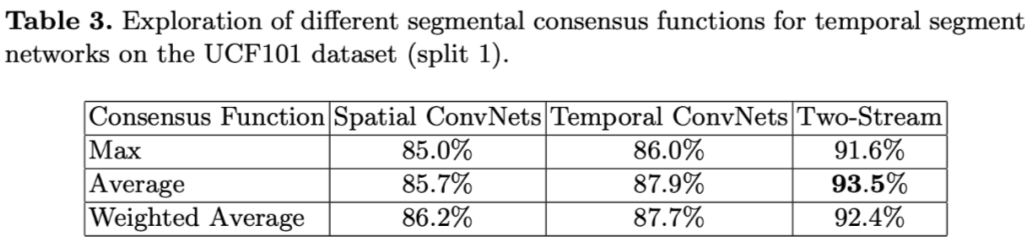
2. 聚合函数探索,结论:average 最好。
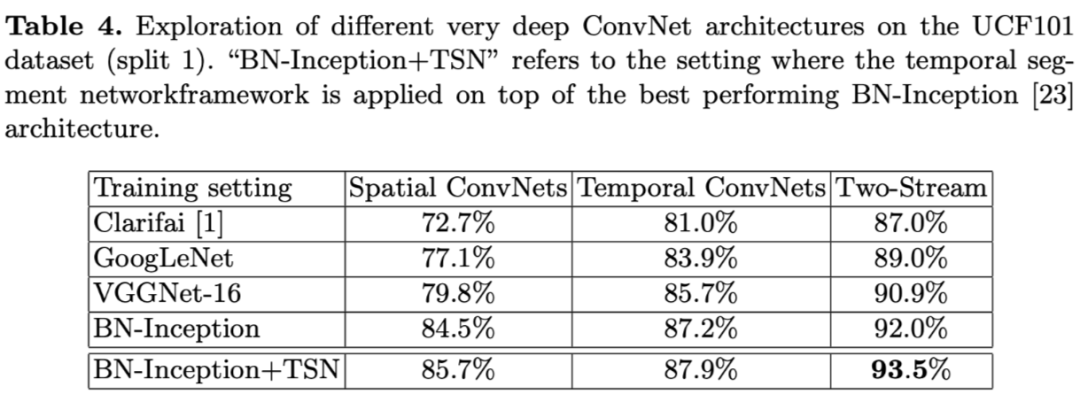
3. 在 UCF101 上精度 94.2%,HMDB51 69.4%。

论文标题:
SlowFast Networks for Video Recognition 所属领域:
视频识别(FAIR,ICCV 2019) 论文链接:
https://arxiv.org/abs/1812.03982
代码链接:
https://github.com/facebookresearch/SlowFast
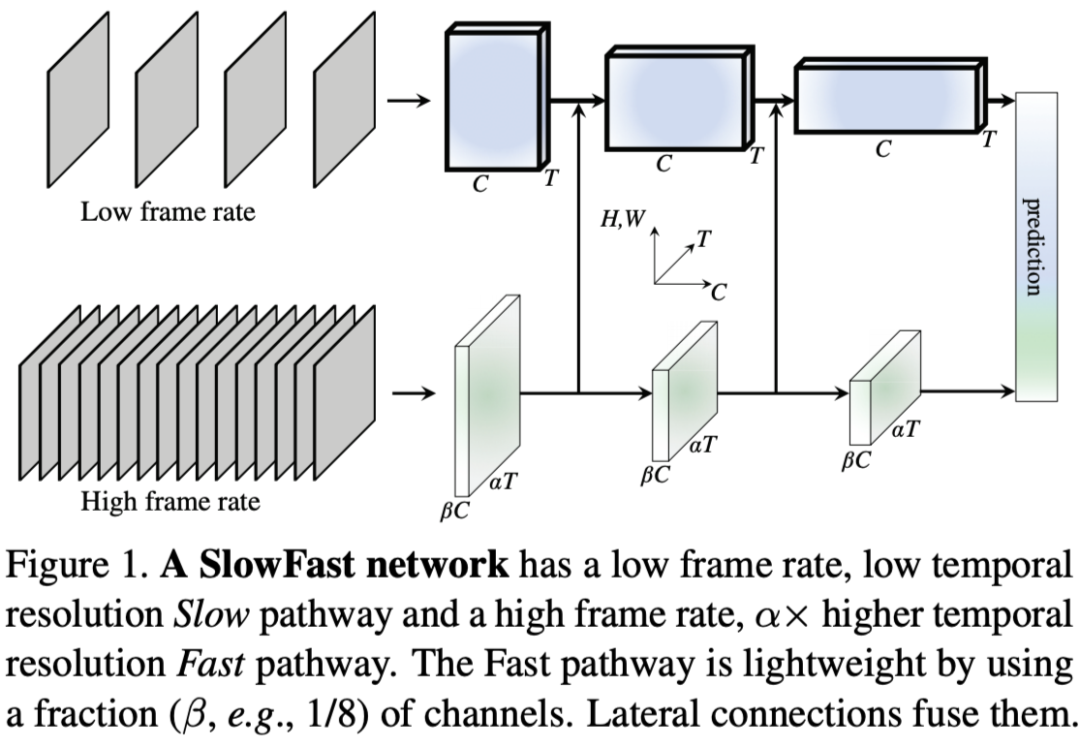
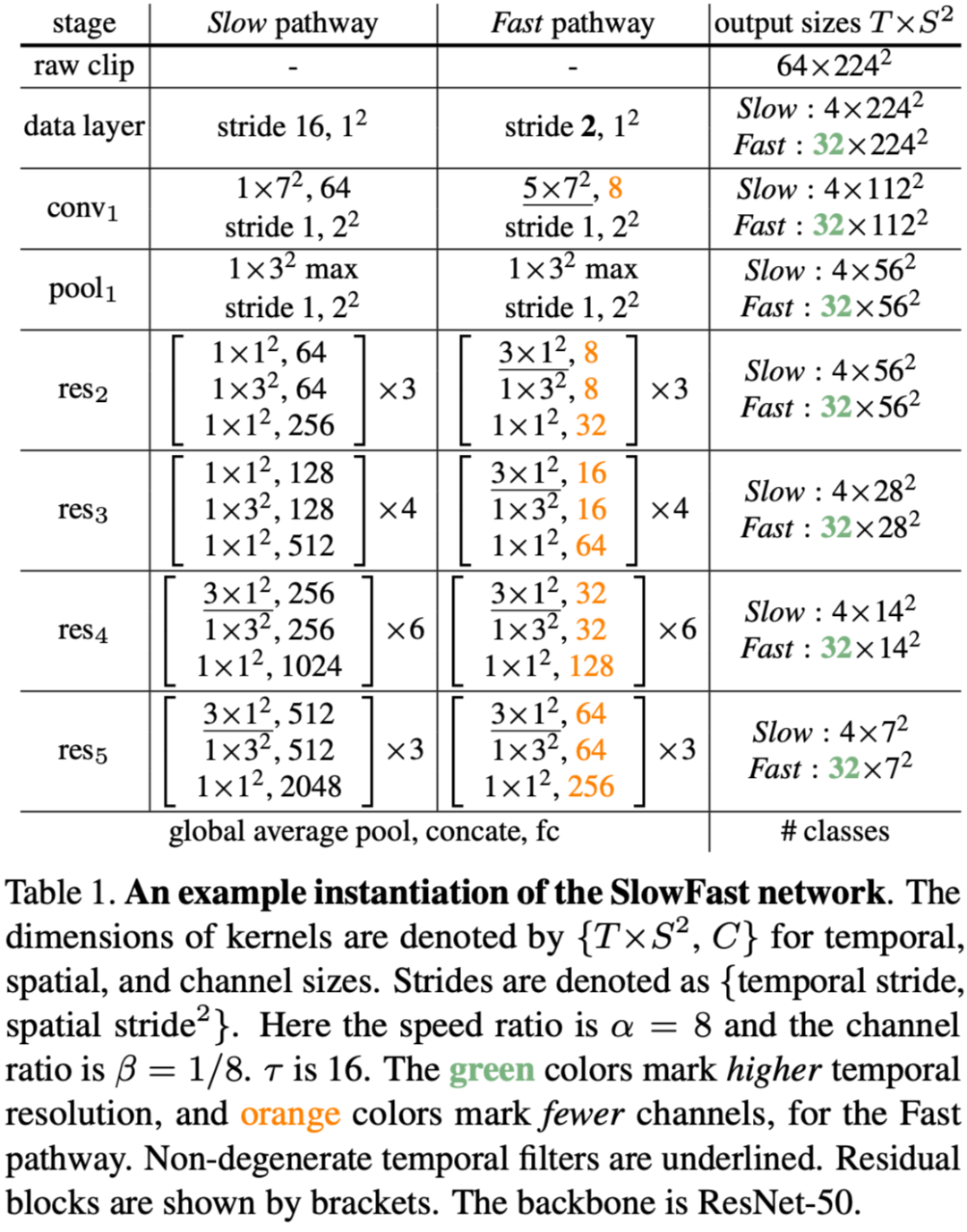
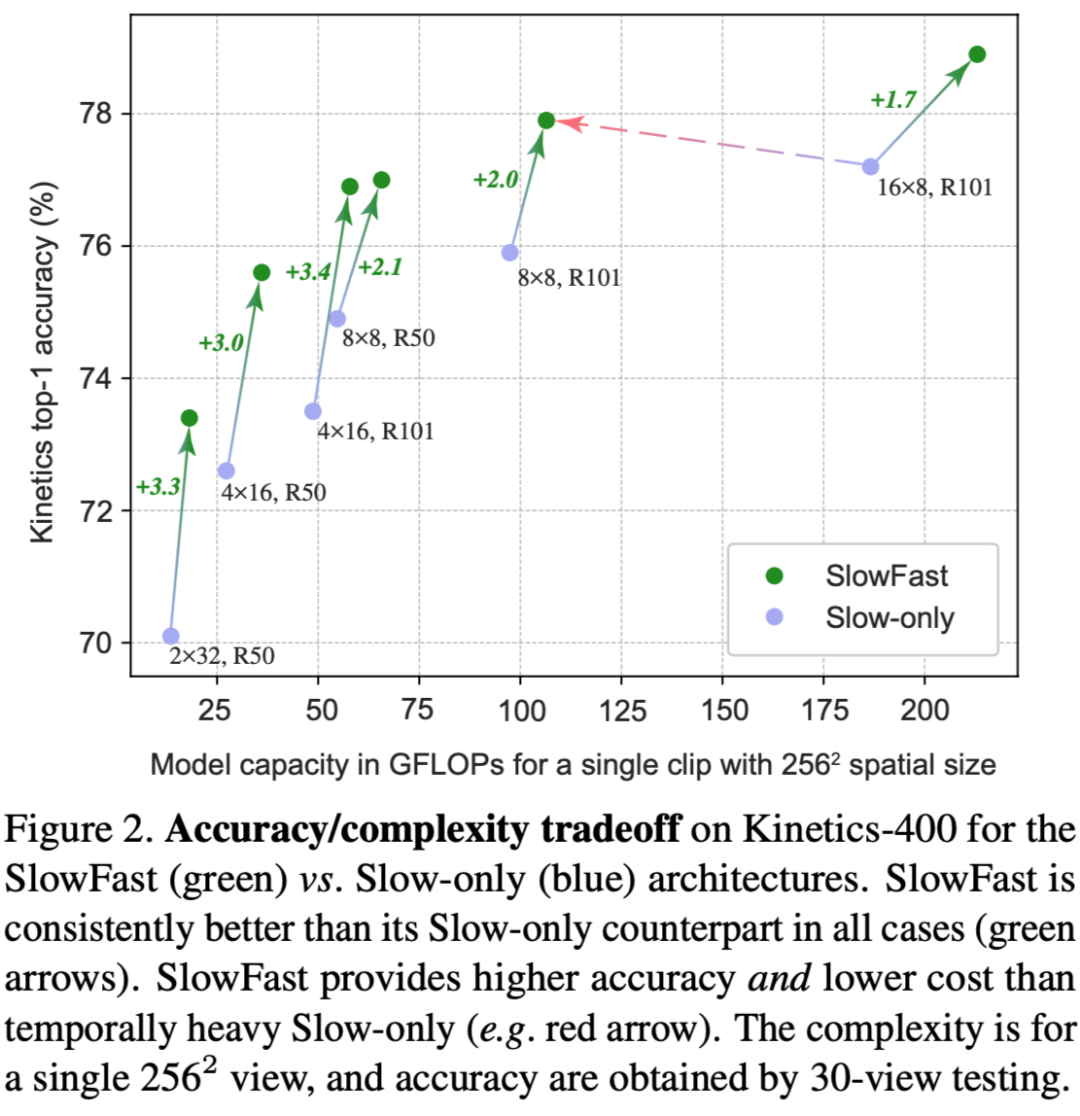
设置 Fast Path 有更高的时间帧率,更小的通道数:

论文标题:
Video Classification with Channel-Separated Convolutional Networks 所属领域:
视频分类(FAIR,CVPR 2019) 论文链接:
https://arxiv.org/abs/1904.02811 代码链接:
https://github.com/facebookresearch/VMZ
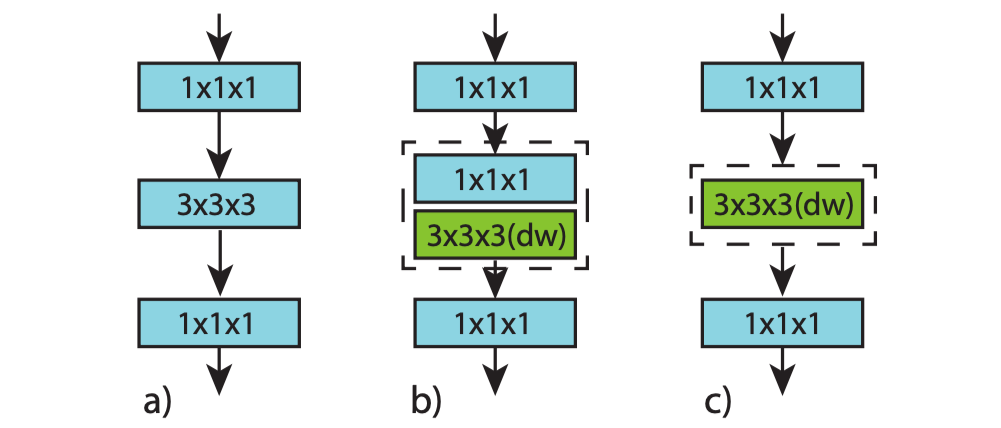
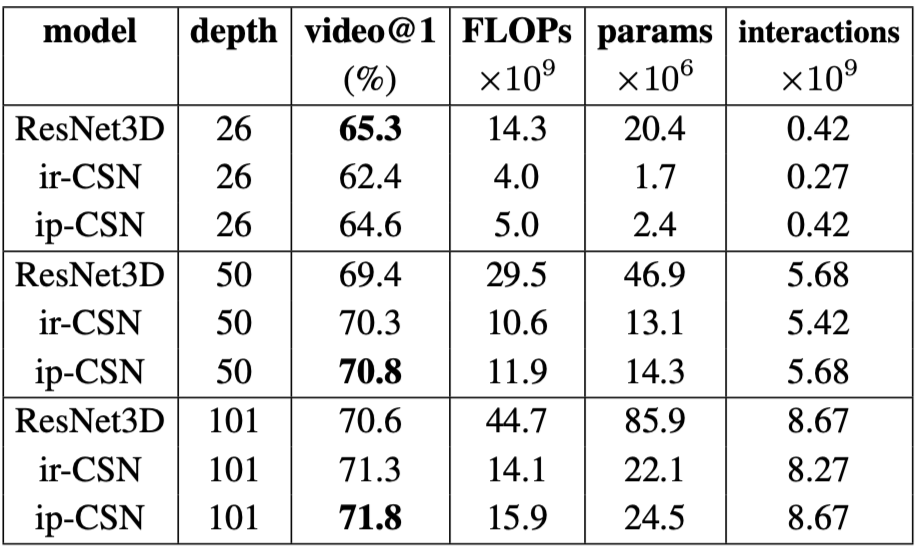
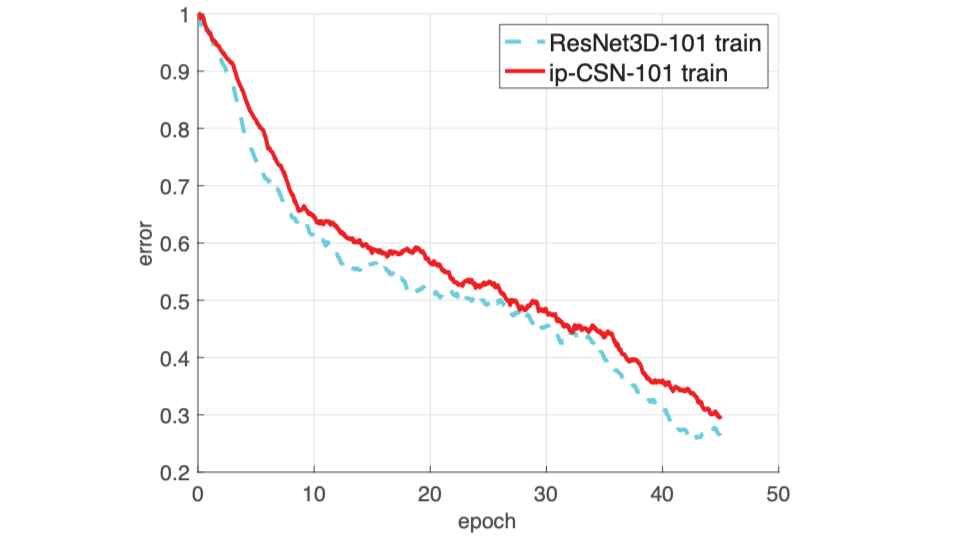
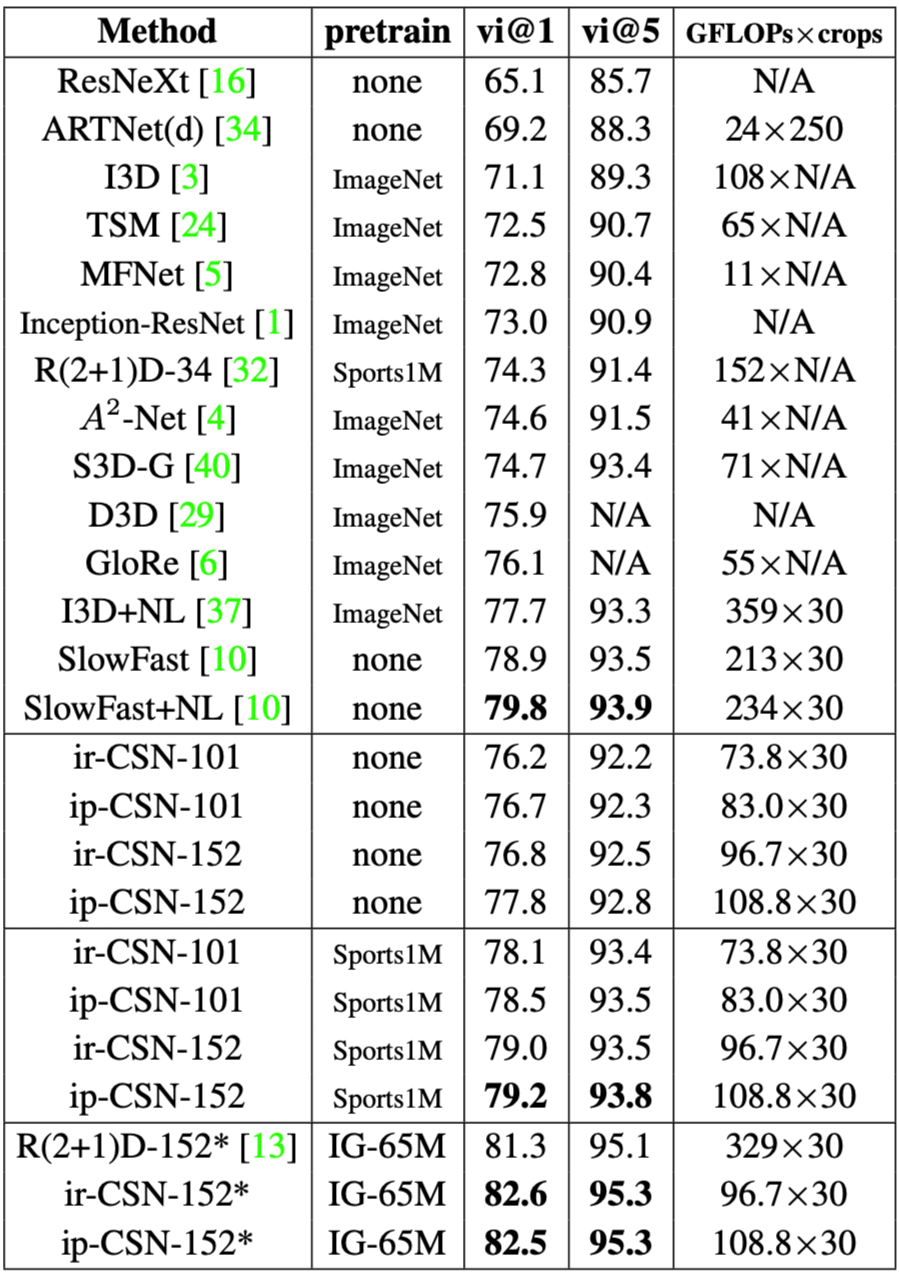
以 SlowFast 为首的 3D conv 结构(i3D, P3D, R(2+1)D, SlowFast等);
以 TSM 为首的 2D conv 结构(TSM,TSN,TIN)等;

扫码观看!
本周上新!

