CVPR 2021 | 任何人都能“不讲武德”,姿态可控的语音驱动说话人脸


CVPR 2021 文章专题
第·20·期
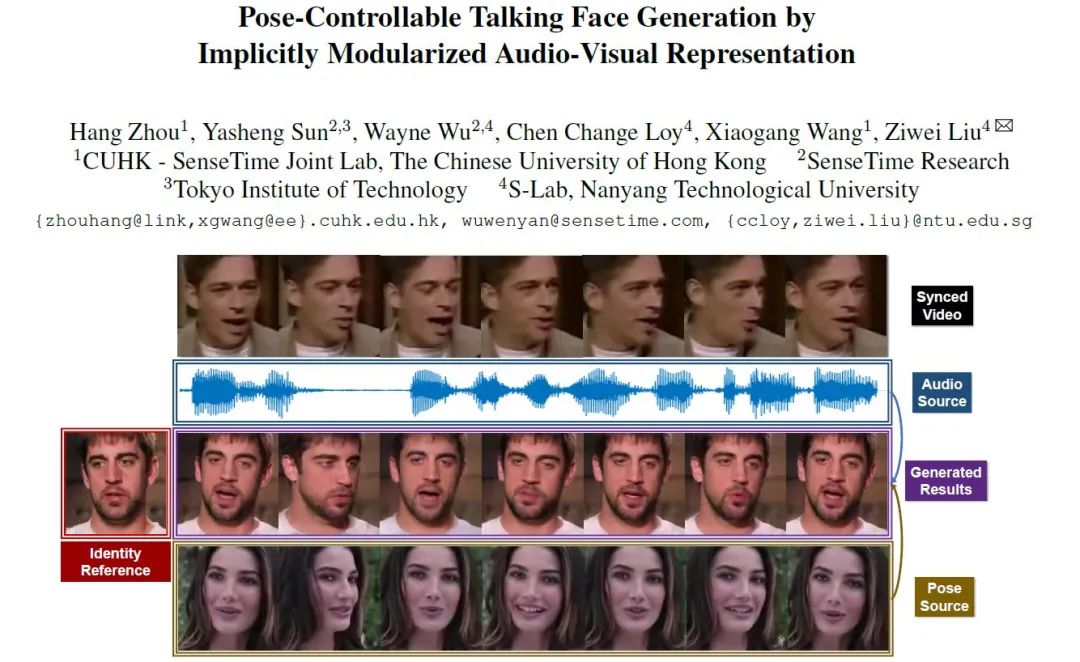
本文不使用任何人为定义的结构信息(人脸关键点或者3D人脸模型),成功实现了人头姿态可控的语音驱动任意说话人脸生成。本文的关键在于,隐式地在潜空间(latent space)中定义了一个12维的姿态编码,用于头部运动控制。本文相比于之前的方法,避免了关键点或者3D模型计算不准确带来的烦恼,又保持了自由度和鲁棒性。实现了在语音控制准确嘴型的同时,用另一段视频控制头部运动。在这一框架下,我们可以让任何人说出马老师经典的“不讲武德”发言,彩蛋在我们demo video的最后!
论文链接: https://arxiv.org/abs/2104.11116.
代码链接: https://github.com/Hangz-nju-cuhk/Talking-Face_PC-AVS. Project Page: https://hangz-nju-cuhk.github.io/projects/PC-AVS. Demo Video:
https://www.zhihu.com/zvideo/1369387261356908544

一、背景介绍

ATVG Paper中的对比图
最近的Makeittalk[5]和乐乐的Rhythmic Head[6] 则关注于和个人ID信息有关的自然头部运动。但是他们的方法都依赖于3D的结构化信息。
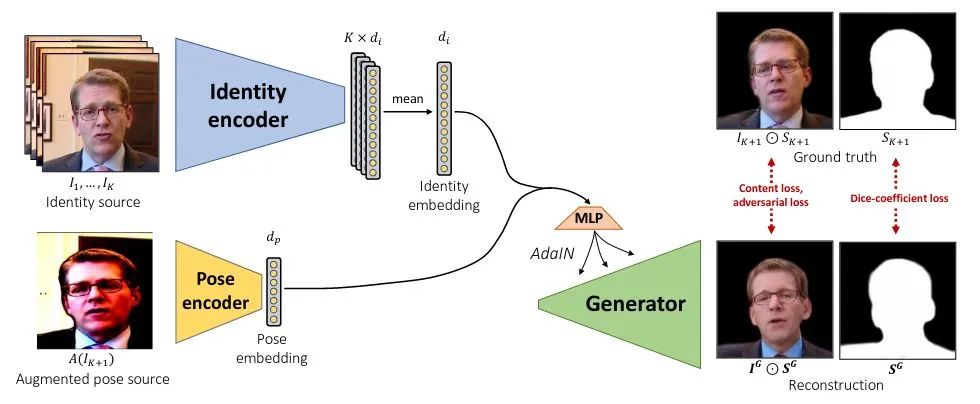
我们的方法Pose-Controllable Audio-Visual System (PC-AVS) 直接在特征学习和图像重建的框架下,实现了对人头pose的自由控制。我们的核心在于隐式地在潜空间(latent space)中定义了一个12维的姿态编码,而这一设计源于对去年CVPR利用styleGAN实现Face Reenactment[7]的工作(如下图)的参考。
但他们工作中只说明了styleGAN可以使用augmented frame进行图像到图像的控制。而在语音驱动的说话人脸问题中,condition实际来自audio的场景下,直接暴力借用这一框架将难以进行训练,因为语音并不能提供人脸姿态信息。
基于对说话人脸的观察,我们在文中把augmented图像的潜空间,定义为无ID空间(Non-Identity Space)。直观上讲,在此空间中,我们可以重新寻找嘴型与语音关联的说话内容空间(Speech Contant Space),和表示头部运动的姿态空间(Pose Space)。
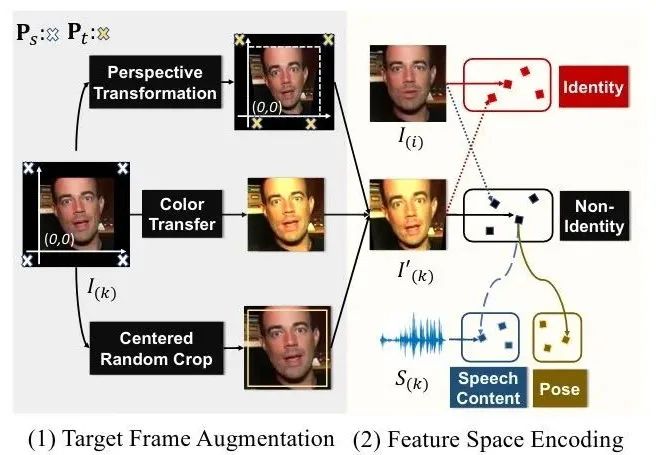
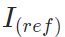 作为ID参考输入,变形另一帧
作为ID参考输入,变形另一帧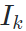 为
为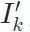 ,并将与
,并将与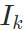 对齐的语音的频谱
对齐的语音的频谱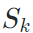 作为condition,试图使用网络恢复
作为condition,试图使用网络恢复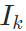 。
。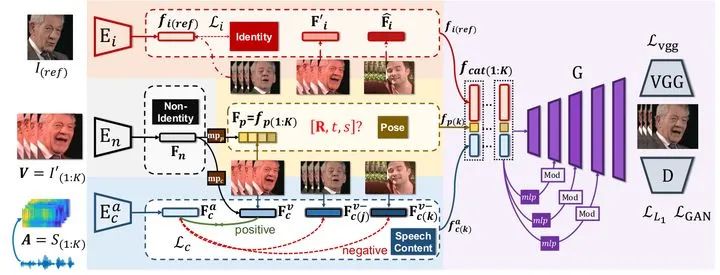
使用数据集的ID约束,我们可以通过ID encoder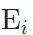 得到Identity Space;借助之前的augmentation,我们通过encder
得到Identity Space;借助之前的augmentation,我们通过encder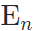 ,得到Non-Identity Space。接下来的问题是如何发挥audio的作用,以及如何让图像只约束Pose而不控制嘴型。
,得到Non-Identity Space。接下来的问题是如何发挥audio的作用,以及如何让图像只约束Pose而不控制嘴型。
Learning Speech Content Space. 我们希望Non-Identity Space的feature经过一个mapping
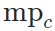 映射至speech content space中。而这一latent space的学习,主要依赖音频和视频之间天然的对齐、同步信息(alignment)。在之前的工作中这已经被证明是audio-visual领域用处最广泛的自监督之一 。在这里我们使用语音与人脸序列之间的对齐构建contrastive loss进行对齐的约束;对齐的人脸序列和语音特征
映射至speech content space中。而这一latent space的学习,主要依赖音频和视频之间天然的对齐、同步信息(alignment)。在之前的工作中这已经被证明是audio-visual领域用处最广泛的自监督之一 。在这里我们使用语音与人脸序列之间的对齐构建contrastive loss进行对齐的约束;对齐的人脸序列和语音特征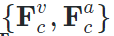 是正样本,非对齐的
是正样本,非对齐的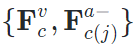 为负样本。定义两个feature之间的cos距离为
为负样本。定义两个feature之间的cos距离为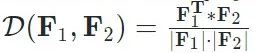 ,这一约束可以表达为:
,这一约束可以表达为:
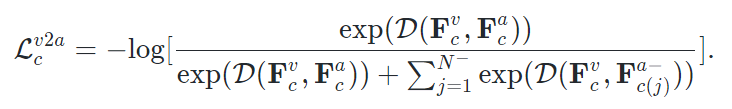
Devising Pose Code. 另一方面,我们借助3D表征中的piror knowledge。一个12维度的向量其实已经足以表达人头的姿态,包括一个9维的旋转矩阵,2维的平移和1维的尺度。所以我们使用一个额外的mapping,从Non-Identity Space中映射一个12维的Pose Code。这个维度上的设计非常重要,如何维度过大,这一latent code所表达的就可能超过pose信息,导致嘴型收到影响。
三、实验结果
我们在数值上和质量上与之前SOTA的任意语音驱动人脸的方法进行了对比。在数值上,我们对比了LRW和VoxCeleb2两个数据集,重点关注于生成图像还原度(SSIM),图像清晰度(CPDB),生成嘴型landmark的准确度(LMD)和生成嘴型与音频的同步性,使用SyncNet 的confidence score评价(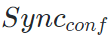 )。
)。
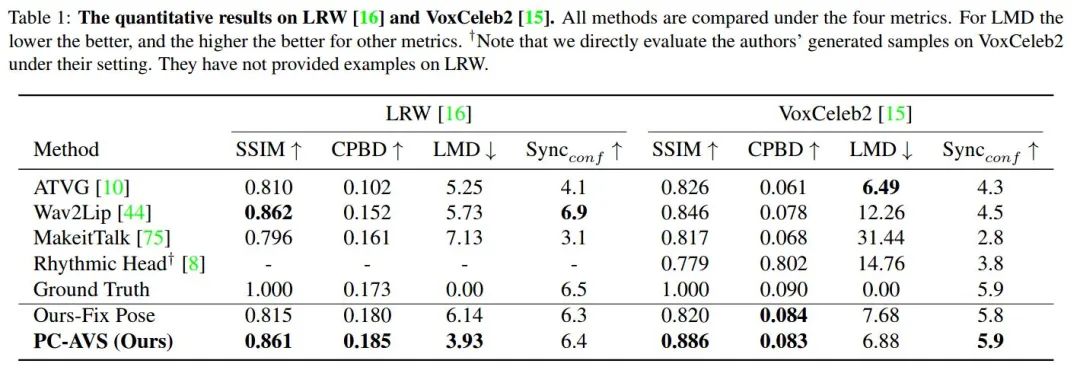
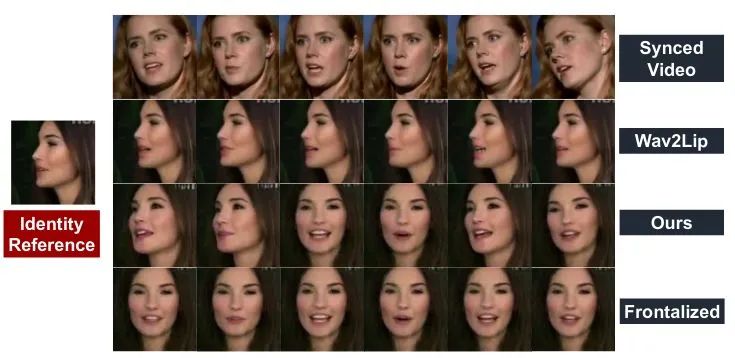
我们与之前方法的对比图如下所示:

参考资料:
1. What comprises a good talking-head video generation?: A Survey and Benchmark
2. Joon Son Chung, Amir Jamaludin, and Andrew Zisserman. You said that? In BMVC, 2017.
3. Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI ConConference on Artificial Intelligence (AAAI), 2019.
https://arxiv.org/abs/1807.07860
4. Lele Chen, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
https://www.cs.rochester.edu/u/lchen63/cvpr2019.pdf
https://arxiv.org/abs/2004.12992
6. Lele Chen, Guofeng Cui, Celong Liu, Zhong Li, Ziyi Kou, Yi Xu, and Chenliang Xu. Talking-head generation with rhythmic head motion. European Conference on Computer Vision (ECCV), 2020.
https://www.cs.rochester.edu/u/lchen63/eccv2020-arxiv.pdf
7. Egor Burkov, Igor Pasechnik, Artur Grigorev, and Victor Lem-pitsky. Neural head reenactment with latent pose descriptors. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2020.
https://openaccess.thecvf.com/content_CVPR_2020/papers/Burkov_Neural_Head_Reenactment_with_Latent_Pose_Descriptors_CVPR_2020_paper.pdf
8. Joon Son Chung and Andrew Zisserman. Out of time: auto-mated lip sync in the wild. In ACCV Workshop,2016.
https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf
9. Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten,Jaakko Lehtinen, and Timo Aila. Analyzing and improv-ing the image quality of stylegan. InProceedings of theIEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR), 2020.
作者介绍
周航,香港中文大学多媒体实验室四年级博士生,师从王晓刚教授。本科毕业于南京大学声学系。目前主要研究方向是音频-视觉的联合学习与人脸生成,曾在ICCV、CVPR、ECCV等会议发表多篇论文。CVPR 2020优秀审稿人,致力于推动视听结合的多模态领域发展。
Illustration by Oleg Shcherba from Icons8
CVPR 2021 论文解读 ●●
// 1
// 2
// 3
// 4
// 5
// 6
// 7
// 8
// 9
// 10
// 11
// 12
// 13
// 14
// 15
// 16
// 17
// 18
// 19
本周上新!扫码观看~



