CVPR 2021 | 无需风格图片的图像风格迁移


CVPR 2021 文章专题
第·19·期
本文从另外一个角度解读,澳洲国立大学郑良老师实验室 CVPR 2021新工作《Visualizing Adapted Knowledge in Domain Transfer》。

论文链接: https://arxiv.org/pdf/2104.10602.pdf 代码链接: https://github.com/hou-yz/DA_visualization

我们首先展示一些示例结果,如下图,在只利用目标(target)图片的情况下,我们可以将其有效迁移至未曾见过的源(source)图片风格。

基于模型的图像风格迁移。在没有利用源图片(c)作为图像风格指导的情况下,我们仅利用目标图片(a),即可将其迁移至源域风格(b)。
一、基于图片的图像风格迁移
不论是风格迁移(style transfer)还是图像变换(image translation)工作,想要在保持图片内容的条件下变换图像的风格,都需要同时利用两张图片:一张图片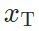 指示内容;一张图片
指示内容;一张图片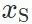 指示风格。此外,它们还需要一个特定的评价网络
指示风格。此外,它们还需要一个特定的评价网络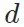 ,来推动图像风格的变换。在风格迁移中(如neural style transfer [1]),
,来推动图像风格的变换。在风格迁移中(如neural style transfer [1]),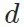 可能是ImageNet预训练VGG的特征分布;在图像变化中(如cyclegan [2]),
可能是ImageNet预训练VGG的特征分布;在图像变化中(如cyclegan [2]),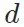 可能是两个域分别对应的判别器网络(discriminator)。
可能是两个域分别对应的判别器网络(discriminator)。
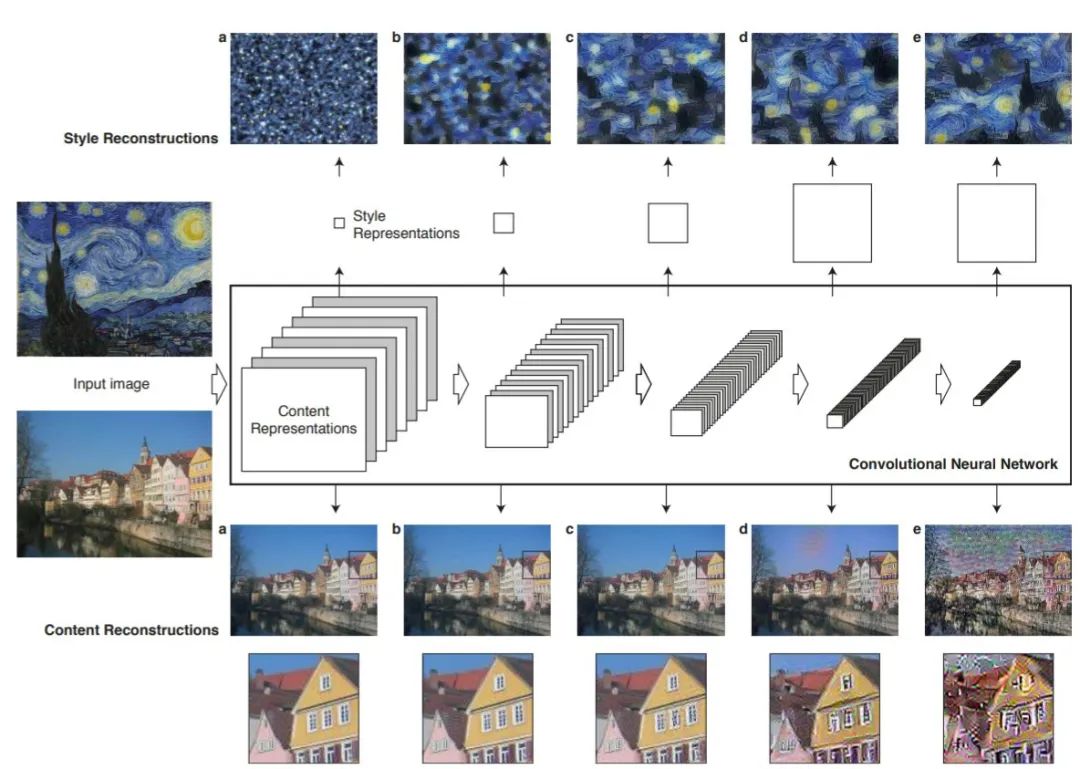 neural style transfer [1] 利用内容图像、风格图像、和基于ImageNet预训练的VGG的评价网络
neural style transfer [1] 利用内容图像、风格图像、和基于ImageNet预训练的VGG的评价网络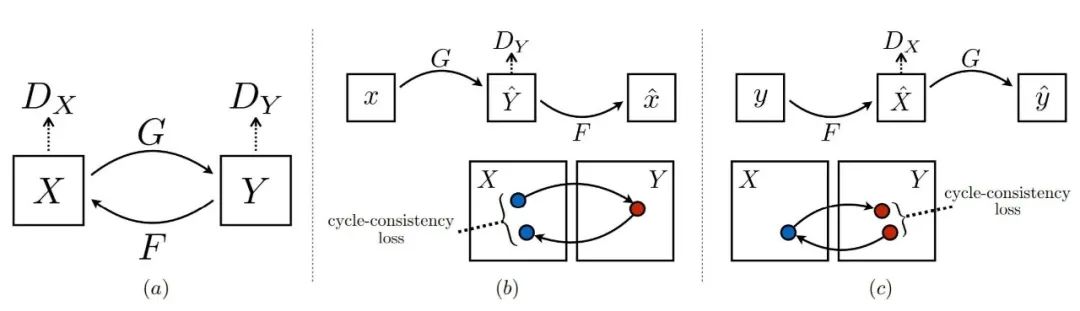 cyclegan [2] 利用内容图像数据集、风格图像数据集(两者互易)、和判别器形式的评价网络
cyclegan [2] 利用内容图像数据集、风格图像数据集(两者互易)、和判别器形式的评价网络 ,其中
,其中 为生成图片
为生成图片 ,
,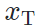 分别代表风格图像和内容图像,
分别代表风格图像和内容图像,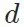 代表某一特定评价网络。
代表某一特定评价网络。二、基于模型的图像风格迁移
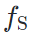 和适用于目标域的网络
和适用于目标域的网络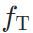 ,且默认这两个网络共享分类层
,且默认这两个网络共享分类层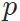 (域迁移中常见设置)。
(域迁移中常见设置)。
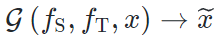 ,其中图片x指导生成图片
,其中图片x指导生成图片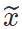 的内容。对比传统的图像风格迁移
的内容。对比传统的图像风格迁移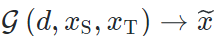 ,基于模型的风格迁移存在以下区别:
,基于模型的风格迁移存在以下区别:不能基于内容-风格图像对 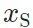 ,
,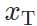 训练,而是凭借源域模型
训练,而是凭借源域模型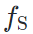 和目标域模型
和目标域模型 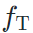 指导图像风格差异;
指导图像风格差异;
风格迁移的标准不依赖于特定的评价网络 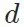 ,而仍是依赖源域模型
,而仍是依赖源域模型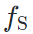 和目标域模型
和目标域模型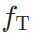 。
。
三、Source-Free Image Translation 方法
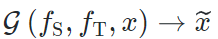 ,我们设计了一套方法,完成基于模型的图像风格迁移任务。特别的,我们只利用目标域图片
,我们设计了一套方法,完成基于模型的图像风格迁移任务。特别的,我们只利用目标域图片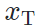 作为内容指导(即作为
作为内容指导(即作为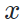 ),而完全避免在图像迁移的过程中利用源域图片
),而完全避免在图像迁移的过程中利用源域图片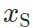 。由此,我们的方法也得名source-free image translation(SFIT),即不依赖源域数据的图像风格迁移。
。由此,我们的方法也得名source-free image translation(SFIT),即不依赖源域数据的图像风格迁移。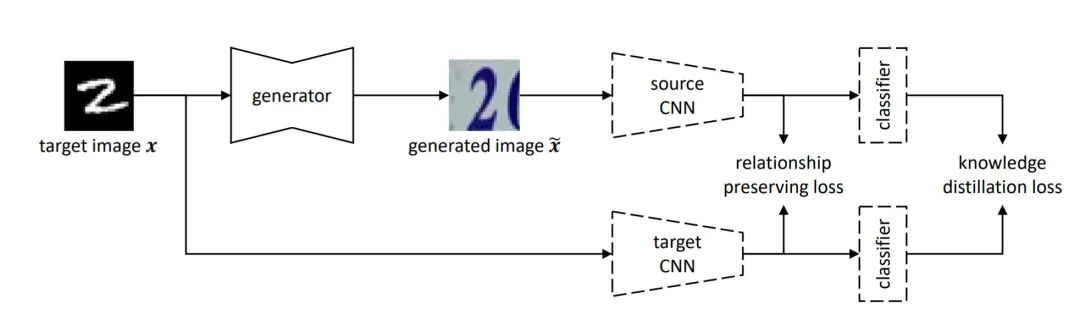
基于模型的风格迁移:不依赖风格图像和评价网络;而是依赖源域模型、目标域模型
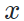 ,我们训练一个生成器
,我们训练一个生成器 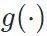 来将其迁移至(源域)风格,生成图片
来将其迁移至(源域)风格,生成图片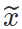 。面对原始的内容图片
。面对原始的内容图片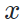 和生成的风格化图片
和生成的风格化图片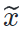 ,传统的基于图像的风格迁移和本文中提出的基于模型的风格迁移存在以下区别:
,传统的基于图像的风格迁移和本文中提出的基于模型的风格迁移存在以下区别:基于图片的风格迁移(neural style transfer)约束生成图片 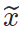 内容上接近
内容上接近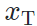 (content loss: 评价网络
(content loss: 评价网络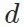 特征图之差),风格上接近
特征图之差),风格上接近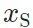 (style loss: 评价网络
(style loss: 评价网络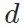 特征图分布的区别)。
特征图分布的区别)。基于模型的风格迁移(SFIT)约束这内容图片 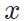 和生成的风格化图片
和生成的风格化图片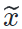 在经过(预训练且固定的)目标域模型
在经过(预训练且固定的)目标域模型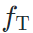 和源域模型
和源域模型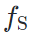 后,能获得相似的输出。我们通过约束最终输出的相似和特征图的分布相似,完成对生成图片内容和风格上的约束。
后,能获得相似的输出。我们通过约束最终输出的相似和特征图的分布相似,完成对生成图片内容和风格上的约束。
四、损失函数设计
知识蒸馏(knowledge distillation):直接约束风格化前后图片在源域和目标域模型上输出相似,
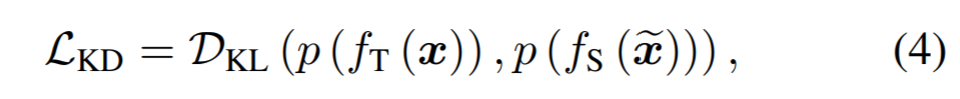
关系保持(relationship preserving):归一化版本的style loss,约束两路特征图输出在特征分布(Gram矩阵,即特征图关于通道的自相关矩阵:抵消HW维度,剩余通道数D维度)上接近。
传统的style loss约束两张图片在同一个评价网络 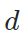 上特征图分布相似;
上特征图分布相似;relationship preserving loss约束两张图片分别经过源域模型 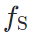 和目标域模型
和目标域模型 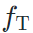 后,得到的特征图归一化分布相似。
后,得到的特征图归一化分布相似。

五、为何约束不同网络的
特征图分布可以迁移风格?
Demystifying neural style transfer [3] 一文证明,传统style loss可以以类似域迁移中Maximum Mean Discrepancy (MMD) loss的方式,通过不同图片在同一网络的Gram矩阵以及二阶统计量,迁移图像的风格。
由于我们假设,源域的网络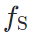 和一个适用于目标域的网络
和一个适用于目标域的网络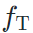 共享分类层
共享分类层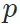 (域迁移中常见设置),我们可以认为这两个网络在通道维度上语义是相对对齐的(共享分类层,需要global average pooling之后的特征向量在通道上对齐,才能在两个不同的域上都获得较好的结果)。鉴于此,我们可以认为,
(域迁移中常见设置),我们可以认为这两个网络在通道维度上语义是相对对齐的(共享分类层,需要global average pooling之后的特征向量在通道上对齐,才能在两个不同的域上都获得较好的结果)。鉴于此,我们可以认为,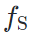 和
和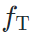 这两个网络以一种松散的方式,保持着类似于同一网络的特性,即通道维度语义对齐。
这两个网络以一种松散的方式,保持着类似于同一网络的特性,即通道维度语义对齐。
但毕竟,两个网络肯定还是存在差别,通道之间的关系也不可能严格维持不变。由此,我们在relationship preserving loss中,使用归一化的Gram矩阵而非原始的Gram矩阵(如传统style loss)。如下图,归一化的Gram矩阵能提供更加均匀的约束,而且能免于对某些维度的过度自信(传统style loss存在过大loss值,在网络不严格一致的情况下,可能过于自信)。
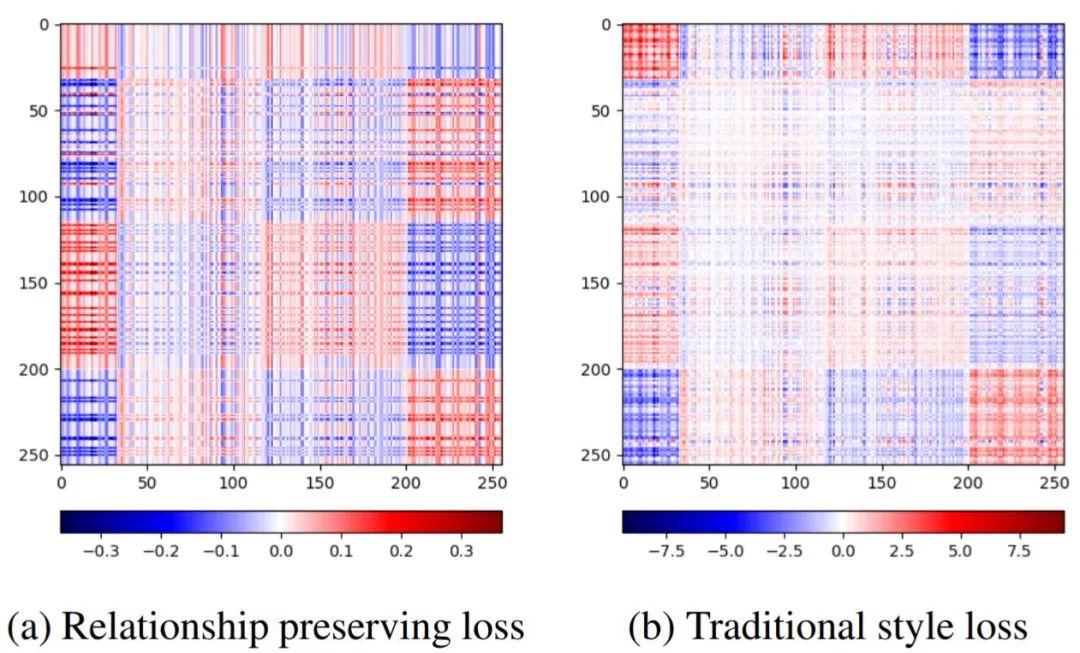
六、实验结果

实验结果表明,仅依赖模型,也可以将目标域图像有效迁移至源域风格。

我们也同时对比了利用不同方式迁移图像风格的效果。如下图,直接对齐Batch Norm层中的统计量可以轻微迁移图像风格 (b);传统的style loss有效迁移风格,但存在边缘和前景的过度白化 ©;文章中提出从relationship preserving loss则是在保持前景的同时(更加锐利的边缘、和背景的区别更明显),有效迁移的图像风格。

Reference
[1]. Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 2414-2423).
作者介绍
侯云钟,2018年获得清华大学电子工程系学士学位。2019年至今,在郑良老师和Stephen Gould老师指导下,在澳洲国立大学(Australian National University)攻读博士学位。目前,他已经在CVPR,ECCV上发表一作文章。研究兴趣包括计算机视觉和深度学习。
Illustration by Oleg Shcherba from Icons8
CVPR 2021 论文解读 ●●
// 1
// 2
// 3
// 4
// 5
// 6
// 7
// 8
// 9
// 10
// 11
// 12
// 13
// 14
// 15
// 16
// 17
// 18
本周上新!扫码观看~



