深度循环优化器DRO:从视频流估计深度和相机轨迹
阿里云人工智能实验室提出了一个基于神经网络的端对端深度循环优化器,能够实时从视频中计算出视频流中每张图的深度和对应的相机轨迹,效果超越了之前所有的深度SFM方法,也使一些无法计算梯度的优化问题的求解成为可能。

论文链接: https://arxiv.org/abs/2103.13201
代码链接: https://github.com/aliyun/dro-sfm DRO KITTI demo: https://www.zhihu.com/zvideo/1376571242087002113

一、Motivation
Structure from Motion (SfM) 是一个经典的计算机三维视觉问题,有着广泛的应用。它的任务是从一系列不同位置拍摄的图片,估计出每张图片的深度信息和对应的摄像机位姿,恢复出一个场景的三维模型。
近年来,基于深度学习的稠密SfM方法兴起,相比于传统的基于优化的SfM方法展现了很多优势。早期的基于学习的方法是使用一个神经网络直接回归每张图片的深度和摄像机位姿,简单暴力,取得了一些成果,但是这类方法最明显的问题就是忽略了任务中的有用信息,如多视角几何约束。所以现在越来越多的方法开始尝试将神经网络与传统优化理论结合起来,利用几何约束构建优化目标函数cost,然后结合优化理论、利用神经网络来优化这个cost。
我们的方法就是后面一种——利用神经网络求解优化问题。之前的这类方法主要有两个问题,第一个是,很多方法需要显式地计算梯度,然后利用 Levenberg-Marquardt或者Gauss-Newton法来最小化目标函数。这样就需要面对很多任务中梯度计算很困难、甚至根本无法计算梯度的问题,就算可以近似求解出梯度,在高维优化问题中也可能会有很多噪声,近似梯度的下降方向并不一定能将变量优化到全局最小值。第二个问题是很多方法都需要构建cost volume,cost volume可以在所有变量的邻域内评估cost,能够充分地考虑所有空间维度上的信息,已经被证明是很有效的手段。但是与它的有效性对应的,是它高昂的计算开销和空间占用。
为了解决这两个问题,我们提出了一个新的架构,一个不需要计算梯度也不需要构建cost volume的优化器——deep zeroth-order recurrent optimizer。我们认为,之前的方法之所以受困于以上两个问题,是因为它们只在空间域上求解,忽略了很重要的时间域信息。所以我们尝试在不使用梯度和cost volume的情况下,引入循环神经网络GRU,利用时间维度上的信息、历史优化轨迹来迭代、交替优化深度图和摄像机位姿。实验结果证明,我们的方法是非常有效的,仅仅利用一个feature-metric cost,我们的空域+时域优化器,在室内室外多个数据集上、在有监督和无监督两种设置下都取得了超越之前算法的结果。
三、深度循环优化器算法
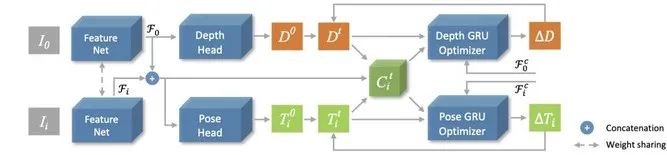
1. 特征提取和目标函数构建
我们基于ResNet-18来提取图像特征 ,然后基于图像特征和当前估计的深度
,然后基于图像特征和当前估计的深度 和摄像机位姿
和摄像机位姿 构建一个feature-metric cost map:
构建一个feature-metric cost map:

公式中的  是3D点到图像平面的投影,所以有了像素点 x 的深度
是3D点到图像平面的投影,所以有了像素点 x 的深度  ,反投影
,反投影  就将 x 反投成3D点,然后坐标转换矩阵
就将 x 反投成3D点,然后坐标转换矩阵  将这个3D点从
将这个3D点从  的相机空间转换到
的相机空间转换到  的相机空间,最后投影
的相机空间,最后投影  将3D点投射到图像
将3D点投射到图像  上。这样就找到了图像
上。这样就找到了图像  和
和  间像素点的位置对应关系,在对应位置的特征图上作差即得到我们的cost map。
间像素点的位置对应关系,在对应位置的特征图上作差即得到我们的cost map。
当有多张相邻帧图片时,我们会计算一个平均cost作为depth的cost:

而post的cost使用的就是 
2. 迭代优化
与传统优化理论类似,我们也是迭代优化cost的,在每一步优化中,优化器都会输出更新增量,基于这增量我们不断更新当前值,这样一点一点地优化估计的深度图和摄像机位姿,直到最优值。
循环优化器我们采用了GRU结构,如图所示:
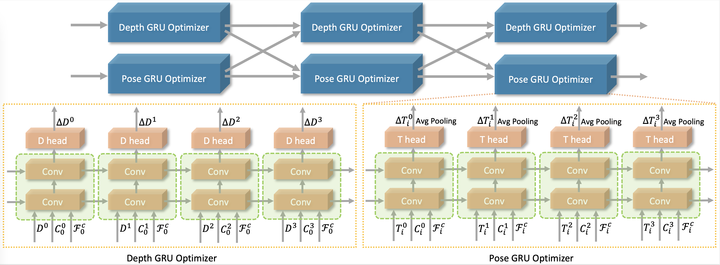
循环迭代优化器结构
在每一步优化中,我们交替优化depth和pose,这样可以减少两个变量之间的相互影响,降低优化难度,提高优化稳定性。整个优化分为m个阶段,在每个优化阶段中我们首先固定住pose更新depth,迭代更新n次,然后固定住depth更新pose,同样迭代更新n次,这样depth和pose总共都是交替更新了m*n次。在所有的实验中,如果不加特殊说明,m设为3,n设为4。
为了看一下整个优化过程中优化器到底做了什么,我们可视化了随着迭代次数增加,cost的变化和depth、pose的估计结果:
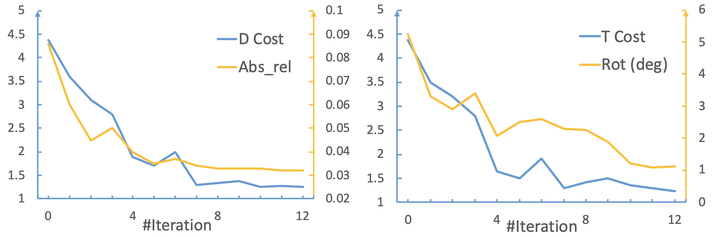
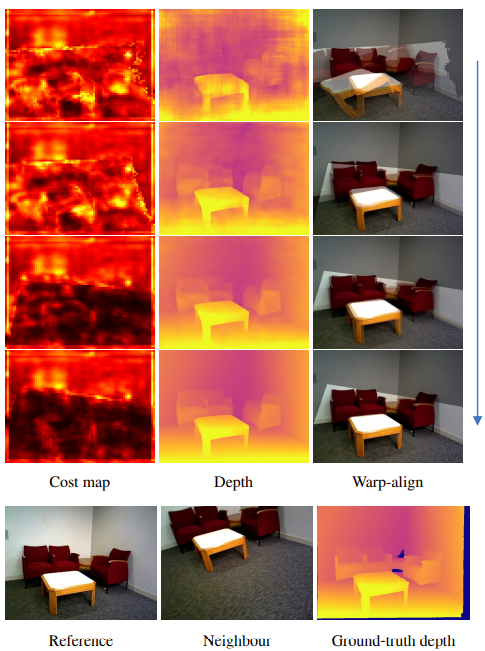
随着迭代次数增加的变化: (1) Cost热力图 (2) 深度图 (3) 利用估计的深度和摄像机位姿将相邻帧投影到当前帧的重叠图
从这几张图像可以看出,随着迭代次数增多,cost不断下降,depth和pose的估计越来越准。
3. 训练设置
a. 有监督
b. 无监督
对于无监督训练,我们使用相邻帧之间的几何约束来构建监督信号,也是无监督算法中通常采用的photometric loss,主要是参考monodepthv2设计的loss。
四、实验
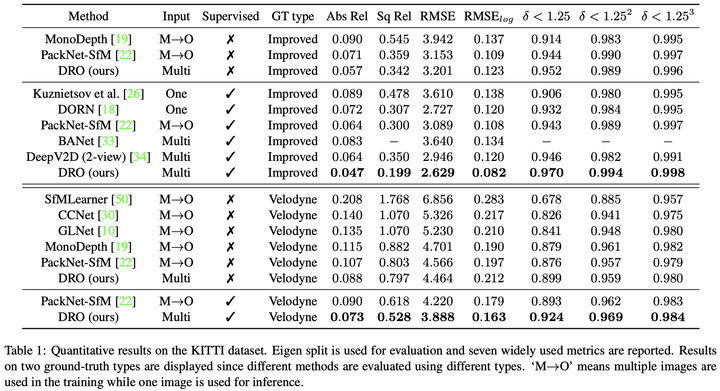
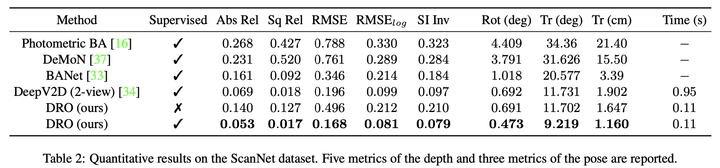
我们在室外数据集KITTI和室内数据集ScanNet上都进行了实验,在有监督和无监督两种设置下,我们都取得了最好的结果:
针对框架中的每个模块的ablation study也证明了每个模块的作用:
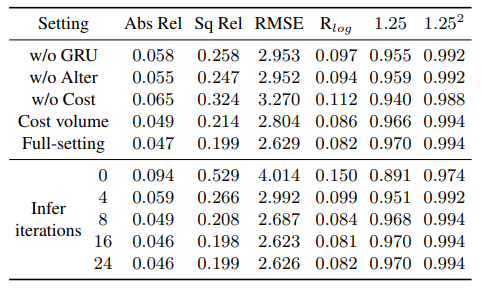
Ablation Study实验
可以看出,虽然我们的优化器在训练过程中一直是更新12次的,但是在实际使用中可以更新任意多次,通过调节迭代次数,可以取得想要的效率和精度之间的平衡。迭代次数越多,精度越高,但是时间消耗越多;迭代次数越少,速度越快,精度会有一定程度的下降。
为了展示我们的算法相对于之前最好算法DeepV2D(使用了cost volume)的效率提升,我们测试了不同迭代次数下的时间开销和显存占用情况:
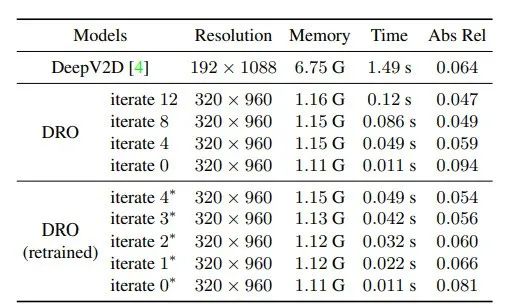
效率实验
可以看到还是有明显优势的。
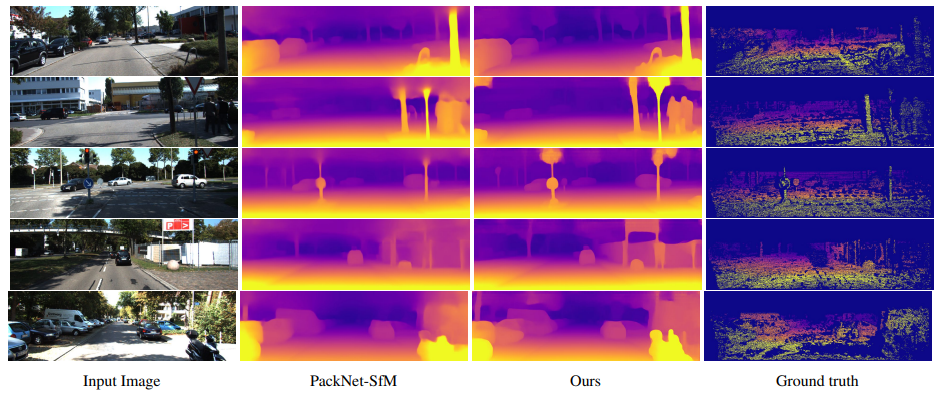
KITTI数据集结果

ScanNet数据集结果
Illustration by Ivan Haidutski from Icons8
本周上新!扫码观看~



