Uber开源Orbit 项目介绍:用于时间序列推断与预测

Orbit 是一种通用的贝叶斯时间序列建模接口。Orbit 开发团队的目标是创建一种易于使用、灵活、可互操作、高性能(快速计算)的工具。Orbit 在底层使用概率编程语言(probabilistic programming languages ,PPL),其中包括 Stan 和 Pyro 的后验逼近(即 MCMC 采样,SVI),但并不局限于此。以下是一个象限图,用于在我们的评估中定位一些时序相关软件包的灵活性和完整性。Orbit 是唯一一个允许简单模型规范和分析的工具,同时不局限于模型的一个小子集。举例来说, Prophet 提供了完整的端到端解决方案,但是只提供了一种模型类型,而 Pyro 提供了充分的规范模型灵活性,但是没有提供端到端解决方案。结果,Orbit 填补了业务问题与统计解决方案之间的空白。
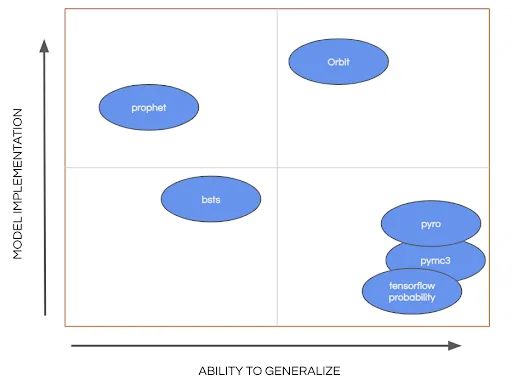 图 1:一些时间序列相关包的象限图。X 轴代表泛化和工具化的能力,而 Y 轴代表具体模型实现的完整性。
图 1:一些时间序列相关包的象限图。X 轴代表泛化和工具化的能力,而 Y 轴代表具体模型实现的完整性。
Uber 有许多不同的时间序列预测用例,包括战略用例(长期)和战术用例(短期)。这些用例有很多不仅需要端到端预测,而且需要因果推理结构来提供可解释性、量化不确定性和假设情景分析,Orbit 可以改进流程质量和效率。
在 Uber 的市场数据科学团队中,Orbit 被广泛用于度量、计划和预测。该方法主要用来测量各种营销杠杆在子渠道和每日粒度的表现。
Orbit 可以很容易地把 KPI 时序分解成趋势、季节和营销渠道效应。该方法可以实现无偏差预测和动态洞察,包括营销渠道的成本曲线和 ROAS。在计划未来营销预算和优化不同渠道和区域的开支时,预测是一个重要部分。
Orbit 可以同时使用多种格式的真实世界数据;也就是将先前的实验结果与多通道的同期数据结合起来。
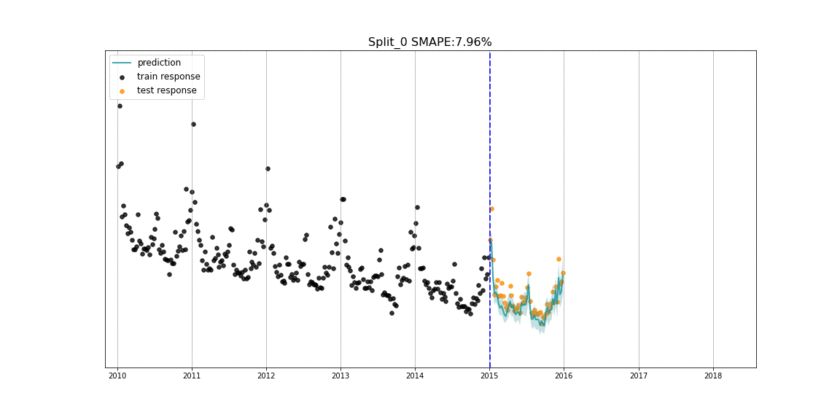 图 2:用扩展窗口方案动态显示 Orbit 回测过程的动画
图 2:用扩展窗口方案动态显示 Orbit 回测过程的动画
Orbit 是 Object-ORiented BayesIan Time Series 的简称(意为“面向对象的贝叶斯时间序列)。Orbit 利用结构贝叶斯时间序列模型进行时间序列推断和预测,并将其应用于实际案例分析中。与其他很多机器学习用例一样,最佳的模型结构主要依赖于特定用例和可用数据。识别合适模型的常用方法是尝试不同的模型类型,进行回溯测试,并判断其性能。具有一致的接口来完成所有这些任务,这大大简化了我们为特定用例确定最佳模型的能力。
尽管 Python 生态系统中有许多时序模型实现,但是 Orbit 的目标是提供一个一致的 Python 接口,通过将一个命令与下图中每一步连接起来,从而简化贝叶斯时序建模工作流程。请查看《如何使用 Orbit?》(How to Use Orbit?) 部分,了解命令的例子。
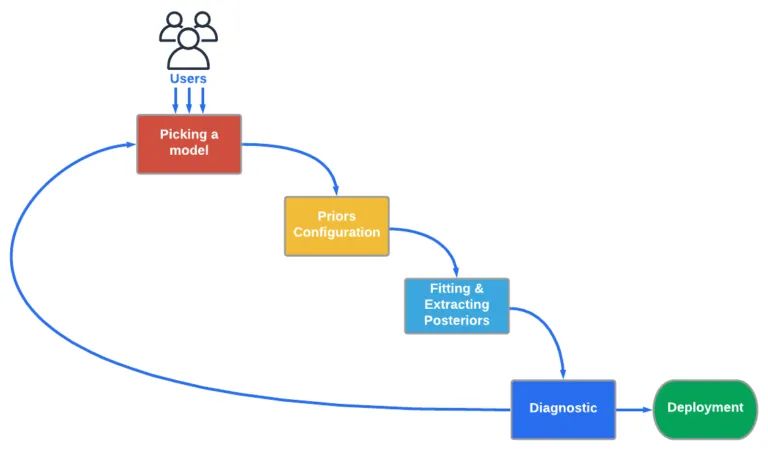 图 3:贝叶斯时间序列建模的工作流概览
图 3:贝叶斯时间序列建模的工作流概览
为了保持评估程序与模型的独立性,我们采用了面向对象的设计模式。对于最终用户而言,这意味着包的使用将保持一致,以完成预期的用例。对模型开发人员而言,这意味着他们的注意力可以集中在模型的结构,而非 Orbit 接口或者与底层 PPL 的交互。
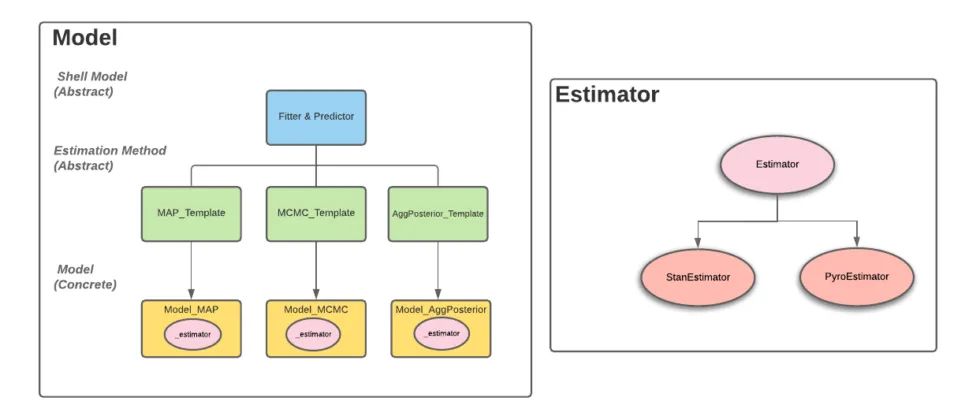 图 4:更深入地研究 Orbit 类关系
图 4:更深入地研究 Orbit 类关系
估计器是指处理与 PPL(如 Stan 或 Pyro)交互的类。如果我们使用底层 PPL,那么似乎就不需要实现此类,但是,除了每个 PPL 的细微差异外,用户还必须确定:
是否进行点估计或完全分布的采样?
采用何种算法对分布进行采样?
点估计采用什么聚合方法?
以及微调配置各种算法
我们抽象出一些决策,并允许一个模型在其中组成指定的估计器。该模型是对模型结构的具体实现,以及如何进行参数估计后的推理。现在实现的主要有两类模型,即局部全局趋势(Local Global Trend,LGT)和阻尼局部趋势(Damped Local Trend,DLT),下面我们将进一步详细讨论。对于用例,我们发现,与其他解决方案相比,当前的两个模型实现表现良好。Orbit 的一个重要目标是在保持接口一致的情况下,快速整合新模型。另外,我们还可以用来追溯那些可以在任何 Orbit 模型对象上开箱运行的测试、诊断和可视化模块。具体地说,我们的包提供:
一个通用接口,可以训练和预测时间序列的模型,具有极大扩展性。
贝叶斯指数平滑模型的一个子类。
数据加载器,用于快速访问不同粒度的时间序列数据集。
丰富的诊断绘图工具。
通用的回溯测试实用程序。
超参数调优工具。
Orbit 的 API 被降级为与 Scikit-learn 有相似的接口(用于通用统计和机器学习模型构建的事实上的标准 Python 库)。下面是 Orbit API 中使用局部趋势模型的 一个示例工作流:

经过模型训练后,可以方便地将预测结果可视化。

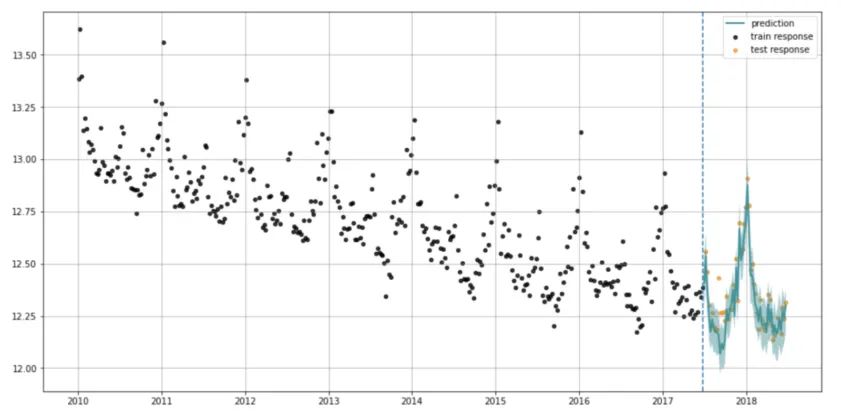 图 5: 由 Orbit 生成的实际与拟合图。黑色的点代表实际训练数据点,橙色的点代表实际测试数据点。青色线条代表预测结果和置信区间。
图 5: 由 Orbit 生成的实际与拟合图。黑色的点代表实际训练数据点,橙色的点代表实际测试数据点。青色线条代表预测结果和置信区间。
Orbit 还提供了一套丰富的绘图工具,用于可视化和诊断采样参数的后验分布和后验痕迹。

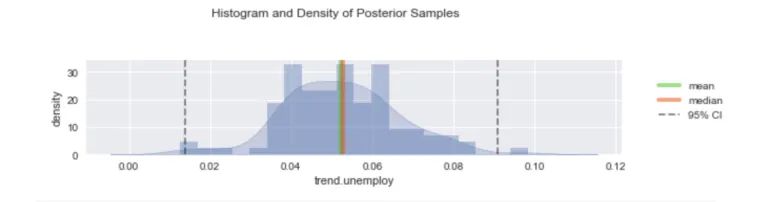

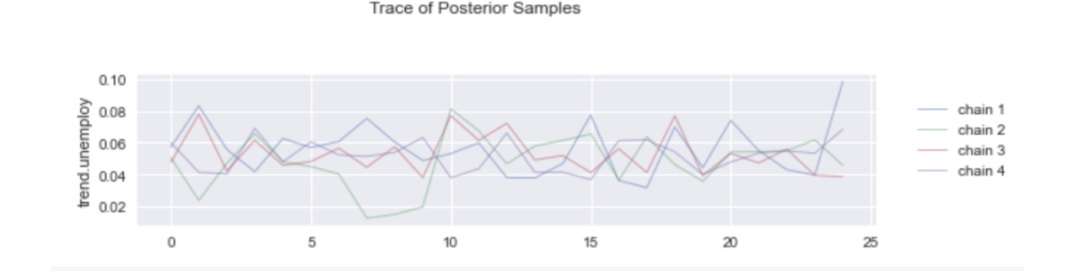

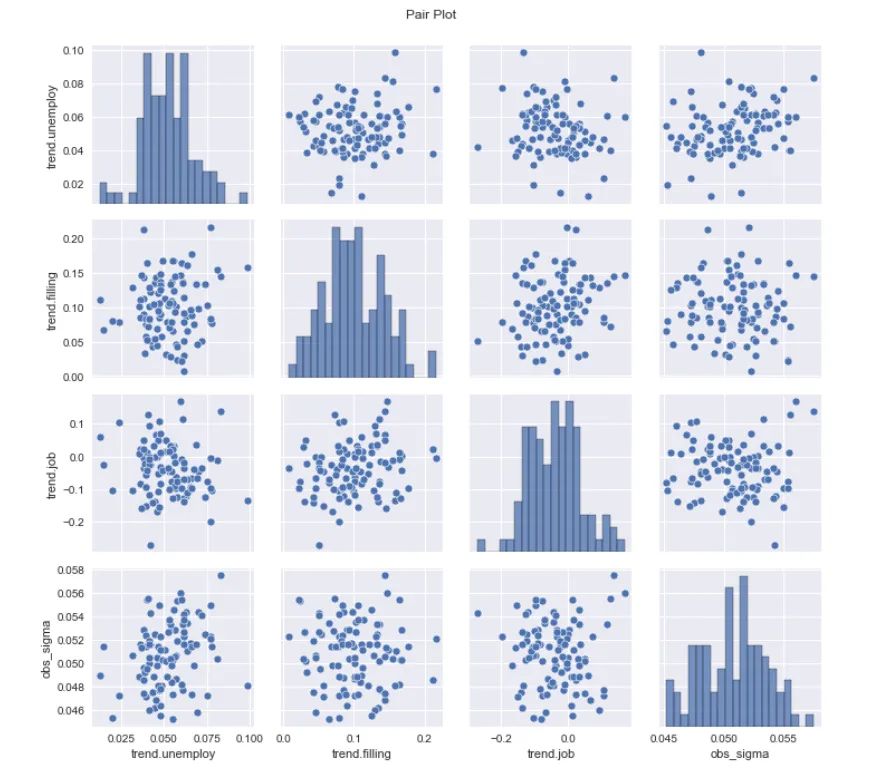 图 6:一组拟合的 Orbit 模型诊断图
图 6:一组拟合的 Orbit 模型诊断图
Orbit 包还提供了一个通用的回测工具,来评估时间序列预测的效果。支持两种回测方案:扩展窗口和滚动窗口。前面介绍的图 2 是一个动画,通过使用具有 6 个分割的扩展窗口方案实现了预测结果的可视化。
现在,我们实现了 Orbit 上的两种主要贝叶斯结构时间序列模型:
季节性局部 / 全局趋势模型
阻尼局部趋势模型
(在 Orbit 中使用面向对象的设计,开发人员可以创建自己的问题特定的模型)
LGT模型是一个加性模型,其预测方程如下:
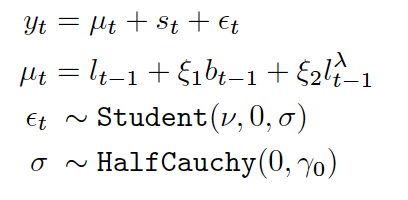

更新过程遵循三重指数平滑形式:
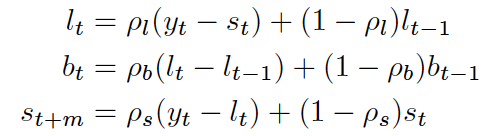

我们提出的季节性局部 / 全局趋势模型,是基于 Smyl 在 Rlgt 中提出的积性模型的一个变体。相对于原始的 Rlgt 模型,该模型具有以下两个优点:第一,使用加性形式计算效率更高;第二,Rlgt 采用参数化方法,在噪声生成中引入依赖性,而在 LGT 中被细化为独立噪声。有了这一变化,它通过对噪声生成过程进行向量化,降低了计算成本。
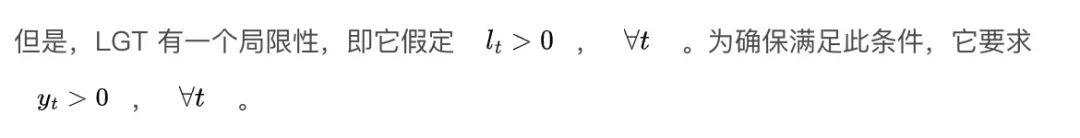

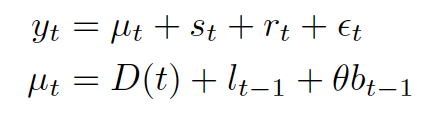
同样,更新过程也遵循指数平滑形式:
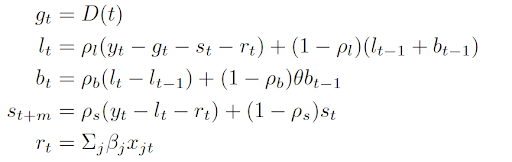
对于确定的全局趋势 D(t) ,我们提供了一个灵活的选择:可以选择平面,线性,对数,线性或者对数。另一个重要的 DLT 特性是引入了回归成分Tt。当外生回归因子 (例如事件和假期) 已知时,这有助于进行当前的预测或预测。如果能保持一般性,我们可以假定:
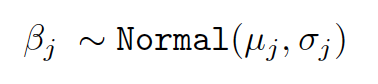
在 Orbit 软件包中,除了实现正态分布外,还实现了丰富的回归成分预设,包括 Lasso、Ridge 和 Horseshoe。就我们所知,Orbit 是少数几个针对结构性贝叶斯时序模型系统地实现这些先验知识的包之一。
为了评估 Orbit 与其他时间序列预测软件包的比较,我们对丰富的数据集进行了全面的基准研究:
Uber 的乘客首次出行系列(按城市划分的 20 个每周系列)。
Uber 的司机首次出行系列(按城市划分的 20 个每周系列)。
Uber Eats 的首单系列(按国家划分的 15 个每日系列)。
M3 竞赛系列(1428 月度系列)。
M4 竞赛系列(359 个周度系列)。
对称平均绝对百分比误差(Symmetric Mean Absolute Percentage Error,SMAPE)作为我们的性能指标。按照竞赛的建议,我们对 M4 周度和 M3 月度系列分别使用了 13 个预测范围和 18 个预测范围,并进行了 1 次拆分;对于 Uber 的数据集,我们对周度行程系列使用了 13 个预测范围,3 次拆分,26 个增量步骤,对每日 Eats 订单系列使用了 28 个预测范围,4 次拆分,14 个增量步骤。
我们将 Orbit 模型、季节性局部 / 全局趋势模型和阻尼局部趋势模型与其他流行的时间序列模型进行了比较,包括 SARIMA 和 Facebook Prophet。Prophet 和 Orbit 模型都使用了最大后验(Maximum A Posteriori,MAP)估计,并且它们在优化和季节性设置方面的配置尽可能相似。值得指出的是,Uber 的数据集涵盖了各城市的新冠肺炎疫情封锁期。这对于测试模型在存在这种极端事件的情况下的表现是很有用的。基准性能表如下所示。Orbit 模型与其他模型相比具有竞争性,其改进指标在 12% 至 60% 之间。
 表 1:模型平均 SMAPE 比较。请注意,对于每个数据集具有最佳 SMAPE 度量的一个以粗体突出显示,括号内的值为标准差
表 1:模型平均 SMAPE 比较。请注意,对于每个数据集具有最佳 SMAPE 度量的一个以粗体突出显示,括号内的值为标准差
在第 40 届国际预测研讨会(International Symposium on Forecasting)和 StanCon 2020 大会上,我们向与会者介绍了 Orbit 的相关工作,并得到了宝贵的反馈。Orbit 项目的下一个里程碑是引入更多的贝叶斯时间序列专用模型。在此过程中,我们将集中精力关注以下几个方面:
实现基于核的时变系数贝叶斯时间序列模型。
能够处理多变量时间序列。
集成 Uber 的机器学习平台 Michelangelo。
结合 Arviz 对贝叶斯模型的探索性分析。
要了解更多关于 Orbit 的信息,请务必查看GitHub上的仓库(https://github.com/uber/orbit) 和 Uber 在 Arxiv (https://arxiv.org/abs/2004.08492)上发布的白皮书。通过开源包,我们期待着其他 Uber 数据科学团队和广大数据科学社区更多的合作和采用。
作者介绍:
Edwin Ng,Uber 高级数据科学家,领导团队建立统计和机器学习模型,以支持营销中的度量和战略决策。
Zhishi Wang,Uber 营销数据科学团队数据科学家。主要从事时间序列研发、包开发和模型平台化。
YiFengWu,Uber 营销数据科学团队数据科学家。致力于构建创新优化平台。
Jing Pan,女,Uber 营销数据科学团队数据科学家,专注于营销的目标定位、个性化、优化和因果推理。
Ariel Jiang,女,Uber 营销数据科学团队数据科学家,致力于计划和预测、边际效益和实验。、
Steve Yang,Uber 前数据科学家。目前在 Facebook Reality 实验室研究因果推理和优化问题。作为全栈数据科学家,他的工作包括将业务问题转化为统计和机器学习任务、设计数据管道、部署 Python 统计包,以及生产模型。
原文链接:
https://eng.uber.com/orbit/

你也「在看」吗?👇