Uber最佳特征发现:通过信息论建立更好、更精简的机器学习模型

设想一下,你有一个运行良好的生产机器学习模型。在模型中添加相关的不同信号源是提高性能的一种可靠方法,但发现新的、真正能提高性能的特征可能是一个缓慢的试错过程。
从搜索开始,你可能会寻求重用为其他项目开发的特征,或者选择那些你认为对模型有益的新特征原型。不管是哪种情况,都会有数以千计的潜在新特征需要探索,其中很多都是常见主题的细微变化。基本问题在于,不清楚这些特征中的哪一个能够真正提高模型性能。大多数新特征与已有特征重叠,甚至全部重叠。
你可以尝试将它们一次添加一个或者成组添加,以评估个别影响,但是这需要时间,而且很难找到不同特征之间的协同作用。
要想使效率最大化,可以一次包含所有可能的特征,这样做也很有吸引力。假定有可能训练一个庞大的模型,那么具有太多特征的模型将会因为维度太多而降低吞吐量,增加服务成本,降低可解释性,并降低对特征漂移的抵抗力。然而,试图从一个大模型中去除不那么重要的特征却会产生反直觉的结果,因为 SHAP 值和其他特征的重要性评分在很大程度上依赖于特定模型训练的具体情况,并且没有考虑到特征的冗余性。
最后,并非每一个用例都能接受所有特征:在许多应用中,新的特征必须经过商业和法律利害关系方的审查,然后才能纳入生产模型。
当模型拥有者重新考虑特征时遇到的实际挑战和摩擦导致了一些常见的反模式:
特征扩展:一旦特征被添加到模型中,它们很少会被重新检查或删除,因此模型倾向于随着时间累积更多特征。
特征冗余:由于在模型中加入新特征的“厨房水槽”更简单,因此与现有特征相比,许多新创建的特征都是多余的。
在训练时,特征扩展和冗余可能不会明显影响单个模型的准确性,但是,在一个大型组织中,许多团队都有多个模型,这将带来巨大的直接和间接成本:
软中断:具有大量特征的模型更容易受到特征漂移和上游数据管道中断的影响,而这些代价高昂的中断需要更长的时间才能诊断和解决。
增加成本:由于特征的扩展和冗余,维护、计算和服务特征的成本在一段时间内会不必要地增加;在服务延迟与商业价值密切相关的应用中,特征数量的增加会导致尾部延迟增加,从而影响利润。
若存在一个可扩展的自动化过程,以解决优化模型特征所固有的阻力和实际困难,则可以控制特征扩展、冗余及相关成本。在 Uber AI,我们开发了一种被称为“最佳特征发现”的方法,该方法在 Uber 所有可用特征中搜索给定模型的最紧凑特征集,同时提高精确度和减少特征数量。
在详细讨论最佳特征发现之前,我们先来介绍一下它所基于的数学和软件技术背景。我们将从信息论的简要概述和关联性、冗余性等关键概念开始,然后把这些概念与机器学习的子领域联系起来,即信息论特征选择。
1948 年,克劳德·香农(Claude Shannon)提出了信息论,它将信息与不确定性(或概率)的联系正式化为数学形式。在这一理论中,一个核心量叫做熵:
H(X)=-\sum_{i=1}^{n} p\left(x_{i}\right) \log_{2} p\left(x_{i}\right)
熵是一种对随机变量结果的不确定性进行量化的方法,它依赖于传递每个结果所需要的期望比特数。在上面的公式中,p(x_i) 是 x中 n个可能结果中单个结果 x_i的概率。量 log2p(x_i) 是来自单个可能结果的信息,而熵 h(x) 则是所有来自 x的期望结果的信息量。
通过观察另一个随机变量 Y 获得的关于一个随机变量 X 的信息量称为互信息。
I(X ; Y)=H(X)-H(X \mid Y)
互信息只是熵的不同:H(X) 是在观察 Y 之前关于 X 的不确定性量,而 H(X|Y) 是在 Y 观测时关于 X 的不确定性量。
从信息论的角度来看,预测目标和模型中的特征都是随机变量,可以用比特来量化一个或多个特征所提供的关于目标的信息量。
相关性是一种重要的概念,它衡量了通过观察特征值,我们希望得到关于目标的多少信息。冗余性是另一个重要概念,它是衡量一个特征与另一个特征之间共享多少信息的标准。
回到抛硬币的例子,有很多不同的方式来获得硬币偏差的信息。我们可以获得一个特征,告诉我们基于硬币设计的正面率,或者我们可以建立一个档案特征,跟踪历史上正面和反面的数量。这两个特征的相关性是一样的,因为它们提供了同等数量的信息,但是观察这两个特征并不比观察任何一个特征给我们提供更多的信息,因此它们是相互冗余的。
在信息论的背景下,相关性是由特征 X 和目标 Y 之间的相互信息来表示的,也就是说,观察到这个特征后,目标的不确定性会减少多少?
I(x;y)
直观地说,在为模型选择特征时,我们希望优先考虑相关性最强的特征,但是在一个大多数特征都是部分或完全冗余的世界里,仅仅根据相关性来对特征进行排序并不能得到最紧凑的特征子集。
在两个特征 X_j 和 X_k 之间的冗余性也可以通过互信息进行量化。
I(X_j;X_k)
若 X_j 和 X_k 完全独立且完全不重叠,则互信息就等于 0。互信息也会随着 X_j 和 X_k 之间的冗余性的增加而增加,直到通过观察 X_j 可以准确预测 X_k 的值。
信息论的特征选择是一系列方法,这些方法利用信息论来对所有可能的特征集进行排序,从而为预测模型选择一个小的 top-k 子集。这些方法很有用,因为搜索所有可能的特征组合是非常昂贵的。信息论的特征选择方法产生了逐步的、贪婪的排序,这些排序近似于相关性和冗余性,与之前的步骤中已经选择的标签和特征相关。我们推荐对文献中的不同方法进行详细调查,但最知名的方法是 MRMR(Maximum Relevance, Minimum Redundance,最大相关性,最小冗余性)。MRMR 的排序函数如下所示:
J_{m r m r}\left(X_{k}\right)=I\left(X_{k} ; Y\right)-\frac{1}{|S|} \sum_{j \in S} I\left(X_{k} ; X_{j}\right)
MRMR 在特征选择的每一阶段,都会根据特征的相关性对剩余的特征进行排序,并对其与已选特征的冗余性作近似度量的惩罚。这个近似值用已考虑的特征 X_k 和已选择的特征集 S 之间的成对冗余项的总和取代联合冗余。
MRMR 及相关技术使我们可以利用贪婪的、逐步的特征选择来发现紧凑的、多样化的相关特征子集。要了解它是如何工作的,我们假设最相关的特征有两个副本。当一个副本被选中后,其余的副本会在下一阶段被放在其他特征下面,因为它会完全覆盖已经被选中的副本。如果没有这个惩罚,贪婪选择将选最相关的两个副本,然后再考虑其他特征。
Uber 的 Palette 特征商店(Feature Store)是一个集中的特征数据库,由整个公司的不同团队众包而成;是用于搜索和管理 Uber 特征的一站式商店。
Palette 托管着数百个表,每个表都具有多达一千个不同的特征。这使得工程师和数据科学家可以访问到丰富的特征池,从而可以更轻松地在团队之间创建和共享特征,并将这些特征纳入生产规模的实时管道。
X-Ray 是 Uber AI 开发的一种信息论数据挖掘工具。X-Ray 旨在实现横向扩展,能够快速发现并量化数据集中的信号,从而提供关于感兴趣结果的信息,例如机器学习标签或业务关键性能指标。其基础是 Apache Spark,以便利用 Spark 的分布式计算框架以及与 Hive 等数据仓库技术的无缝集成。
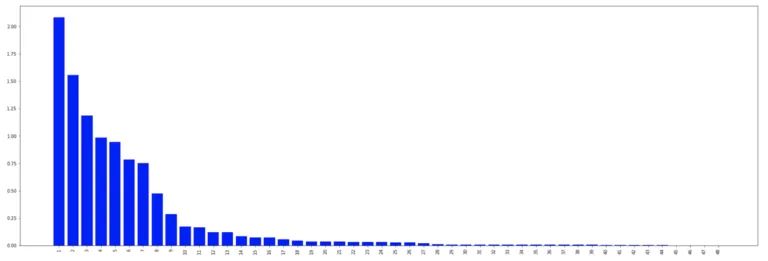 X-Ray 推荐的前 50 个特征,按与目标变量相关的互信息进行排序
X-Ray 推荐的前 50 个特征,按与目标变量相关的互信息进行排序
最初,X-Ray 被用于数据探索应用,比如在服务器日志中找到软件失败的根源,但是今年,X-Ray 团队通过增加了一个信息特征选择 API 来扩展它的能力。这一新的 API 的设计目的是为 Uber 提供灵活和可扩展的特征选择功能,使其与 Palette 特征存储的增长保持同步,并将内部特征选择工具集成到一个通用平台解决方案中。
在 Palette 特征库中,机器学习建模人员可以使用 X-Ray 自动识别与其模型相关的已有特征,从而避免创建新特征。反过来,X-Ray 可以帮助整合模型中使用的任何与 Palette 中已有的特征重叠(冗余)。
最佳特征发现是一个自动化的过程,帮助客户团队找到一个紧凑的、性能良好的特征点来解决监督学习问题。该方法已应用于多个项目,取得了良好的效果:在保持甚至提高模型准确性的同时,减少了 50% 的特征数。
最佳的特征发现使用两个独立的自动化工作流:特征排名和特征修剪。将特征发现分成两个工作流,使数据科学家有机会在排序后和修剪前对泄漏或潜在的合规问题进行健全性检查。
特征排序从一个基准数据集开始,其中包含模型的所有现有特征和标签。
在 Palette 存储中,基线数据集与所有其他适用的特征连接起来,这通常使特征的总数增加到成千上万。还可以根据需要配置此步骤,以便从 Palette 中排除某些特征或表。
最后,我们运行 X-Ray 特征选择引擎,生成一个大型的候选特征排序集。
在数据科学家对特征进行排序和验证后,用不同数量的前 k 个候选特征来训练竞争模型,并在验证准确率方面选择表现最好的模型。
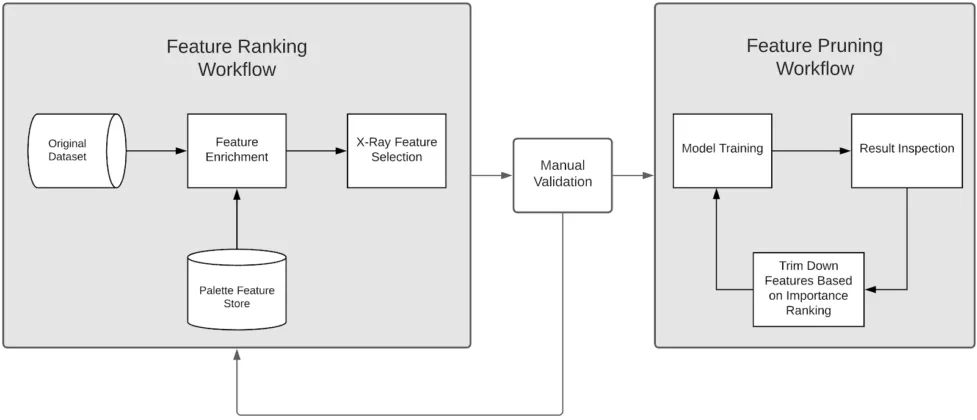
最佳特征发现的高级工作流
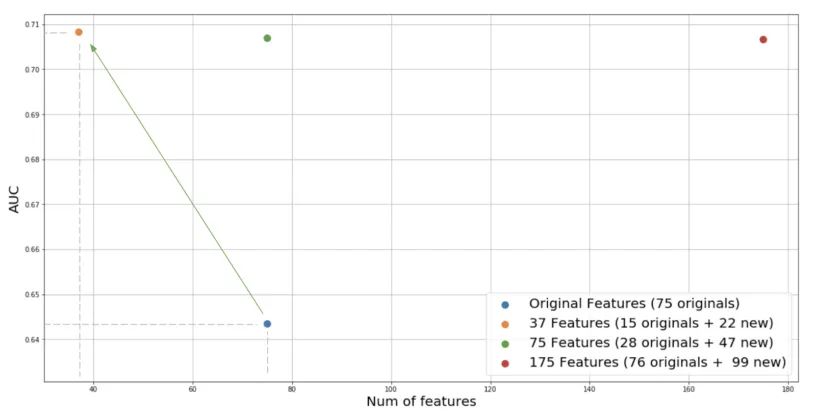
下面是最近在我们的一个关键业务模型上进行的一个实验。该问题是一个二元分类问题,基线模型是一个具有 75 个特征的随机森林。应用最佳特征发现过程,我们首先将原始数据集与特征存储中发现的另外 2k 多个特征加入,采用最小冗余性最大相关性(MRMR)算法,对给定的预测目标下的前 100 个特征进行排序。得到与模型无关的特征排序结果后,我们对模型进行训练,并对所选择的特征的数量进行反复修剪。
有趣的是,如图所示,我们能够达到明显更高的性能,但也将特征的数量减少了一半。新的 37 个特征,包括原来的 15 个特征和 X-Ray 从 Palette 特征库中新引入的 22 个特征。较小的特征集有一些优点,如较低的工程复杂性,较少的依赖性,较低的存储成本和服务延迟等。
这一增长背后的原因是多方面的。第一,X-Ray 能够从大量的候选特征中识别出预测能力更强的特征。二是由于 MRMR 能够惩罚特征之间的冗余,消除了整个过程中的虚假特征,避免了模型的过拟合。
这项工作的未来扩展包括:将 Palette 特征库中的冗余特征整合为一个共同的特征集,自动特征工程和转换,支持嵌入和结构化数据,以及改进的信息论特征选择算法,超越 MRMR 中使用的成对近似。
作者介绍:
Adam Wang,Uber AI 机器学习平台(Michelangelo)软件工程师。
Olcay Cirit,Uber AI 研究科学家,专注于机器学习系统和大规模深度学习问题,曾在谷歌从事广告定位工作。
Amit Nene,领导 Uber AI 机器学习平台(Michelangelo 的特征工程。曾领导 Uber 风险团队的实时数据工程。
Niel Teng Hu,Uber AI 前软件工程师,从事应用机器学习和机器学习系统。
原文链接:
https://eng.uber.com/optimal-feature-discovery-ml/

你也「在看」吗?👇