一文了解预训练语言模型| 文末赠书
近年来,在深度学习和大数据的支撑下,自然语言处理技术迅猛发展。
而预训练语言模型把自然语言处理带入了一个新的阶段,也得到了工业界的广泛关注。
通过大数据预训练加小数据微调,自然语言处理任务的解决,无须再依赖大量的人工调参。
借助预训练语言模型,自然语言处理模型进入了可以大规模复制的工业化时代。
那到底什么是预训练?为什么需要预训练呢?
以下内容节选自《预训练语言模型》一书!

--正文--
预训练属于迁移学习的范畴。
现有的神经网络在进行训练时,一般基于后向传播(Back Propagation,BP)算法,先对网络中的参数进行随机初始化,再利用随机梯度下降(Stochastic Gradient Descent,SGD)等优化算法不断优化模型参数。
而预训练的思想是,模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
在正式探讨自然语言处理的预训练之前,回顾一下计算机视觉领域的预训练过程。
在图片分类任务中,常用的深度学习模型是卷积神经网络(Convolutional Neural Network,CNN)。对于由多个层级结构组成的CNN来说,不同层学到的图像特征是不一样的,越浅的层学到的特征越通用,越深的层学到的特征和具体任务的关联性越强。
在图1中[6],对基于人脸(Faces)、汽车(Cars)、大象(Elephants)和椅子(Chairs)的任务而言,最浅层的通用特征“线条”都是一样的。
因此,在大规模图片数据上预先获取“通用特征”,会对下游任务有非常大的帮助。

图1 图像预训练示例
再举个简单的例子,假设一个《怪物猎人:世界》的游戏玩家想给游戏中的怪物(如飞雷龙、浮空龙、风漂龙、骨锤龙等)做一个多分类系统,而有标注的数据只有游戏中的若干图片,重新训练一个神经网络模型显然不太可能。
幸运的是,现有的大规模图片数据库ImageNet 中一共有20000多类标注好的数据集,包含超过1400 万张图片。
通过ImageNet 训练出来的CNN 网络参数,可以迁移至怪物猎人的训练任务中。
在比较浅层的CNN网络初始化时,可以使用已经训练好的参数,而在模型的高层,其参数可以随机初始化。
在训练怪物猎人的特定任务时,既可以采用冻结(Frozen)参数的方式,也就是浅层参数一直保持不变;也可以采用微调的方式,也就是浅层参数仍然随着任务的训练不断发生改变,从而更加适应怪物的分类。
将图片转换为计算机可以处理的表示形式(如像素点的RGB 值),就可以输入至神经网络进行后续处理。
对自然语言来说,如何进行表示是首先要考虑的问题。
语言是离散的符号,自然语言的表示学习,就是将人类的语言表示成更易于计算机理解的方式。
尤其是在深度神经网络技术兴起之后,如何在网络的输入层使用更好的自然语言表示,成了值得关注的问题。
举例来说,每个人的名字就是我们作为自然人的一个“表示”,名字可以是若干个汉字,也可以是英文或法文单词。
当然,也可以通过一些方法表示成由0 和1 组成的字符串,或者转换为一定长度的向量,让计算机更容易处理。
自然语言的表示有很多方式,图2 给出了自然语言表示学习的发展路径。
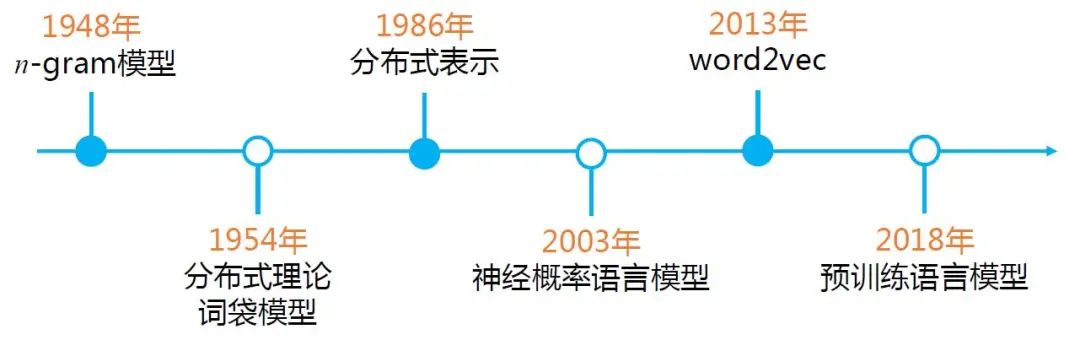
图2 自然语言表示学习的发展路径
最早期的n-gram 模型,是基于统计的语言模型,通过前n个词来预测第n+1个词。
分布式理论(Distributional Hypothesis)在20世纪50年代被提出,这也是近10年,从word2vec到BERT 等一系列预训练语言模型的自然语言表示的基础思想。
早期的词袋模型,虽然能够方便计算机快速处理,却无法衡量单词间的语义相似度。
到了1986 年,分布式表示(Distributed Representation)被提出。虽然分布式理论和分布式表示同样都有“分布式”这个词,但其英文表述是不一样的,含义也不尽相同。
分布式理论的核心思想是:上下文相似的词,其语义也相似,是一种统计意义上的分布;而在分布式表示中,并没有统计意义上的分布。
分布式表示是指文本的一种表示方式。相比于独热表示,分布式表示将文本在更低的维度进行表示。
随着word2vec和GloVe等基于分布式表示的方法被提出,判断语义的相似度成为可能。图3给出了GloVe 词向量的可视化结果。
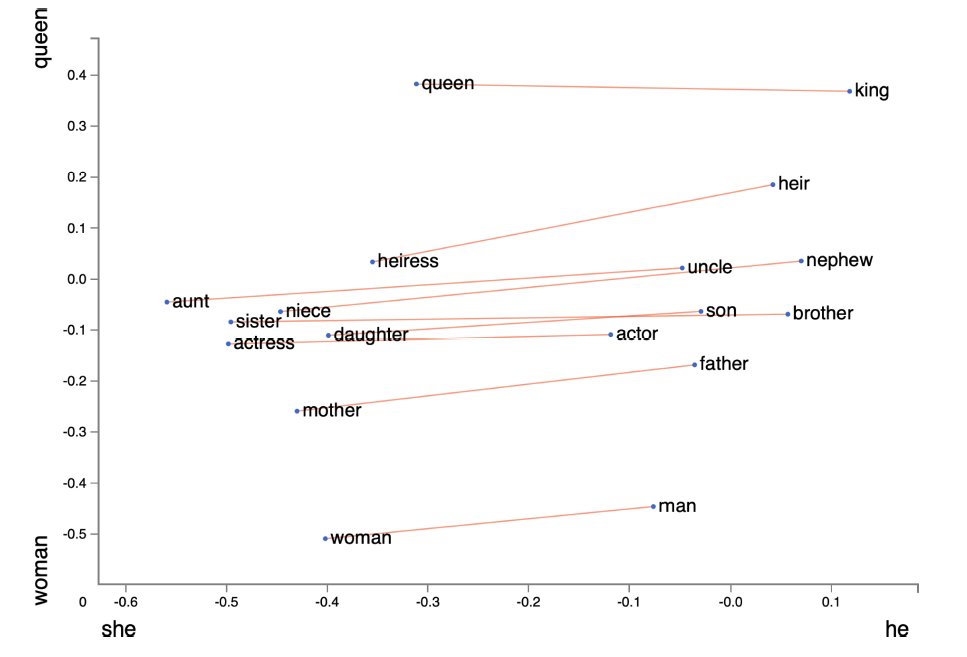
图3 Glove 词向量的可视化结果
2013 年之后,基于大规模的文本数据训练得到的分布式表示,逐渐成了自然语言表示的主流方法。
在这种方式下,每个单词都有了一个固定的词向量表示,语义相近的单词,其向量也是相似的。
从图3中可以看出,queen 和king,以及woman 和man 就是以“性别”为基准来对应的单词。
有了自然语言的表示,就可以将表示后的词向量送入神经网络进行训练。这就是第一代预训练语言模型。
一些读者可能已经注意到,word2vec 的提出时间是2013 年,那么为何在2018 年ELMo出现之后,预训练语言模型才有了突飞猛进的发展呢?
最重要的原因就是,之前的词向量表示无法很好地解决一词多义的问题。
我们都知道,多义词是自然语言中的常见现象,也体现了语言的灵活性和高效性。
例如,单词play 可以表示玩游戏,可以表示播放,可以表示做某项运动,还可以表示演奏某个乐器。但在以word2vec 为代表的第一代预训练语言模型中,一个单词的词向量是固定不变的,也就是说,在对单词play 进行向量表示的过程中,不会区分单词的不同含义,这就导致无法区分多义词的不同语义。
美国语言学家Zellig S. Harris 在1954 年的一篇文章[10] 中提到:“在相近上下文中出现的单词是相似的”(words are similar if they appear in similar contexts)。
英国语言学家John Rupert Firth 在1957 年的A synopsis of linguistic theory 中提到:“你可以通过单词的上下文知道其含义”(You shall know a word by the company it keeps)。
EMLo 论文的原始标题是Deep contextualized word representation,从“contextualized”一词可以看出,ELMo 考虑了上下文的词向量表示方法,以双向LSTM 作为特征提取器,同时考虑了上下文的信息,从而较好地解决了多义词的表示问题,后续章节会详细介绍。
ELMo 开启了第二代预训练语言模型的时代,即“预训练+ 微调”的范式。
自ELMo 后,Transformer[11] 作为更强大的特征提取器,被应用到后续的各种预训练语言模型中(如GPT、BERT 等),不断刷新自然语言处理领域任务的SOTA(State Of The Art,当前最优结果)表现。
Transformer 是由谷歌在2017 年提出的,其创新性地使用了Self-Attention(自注意力),更善于捕捉长距离的特征,同时其并行能力也非常强大,逐步取代了RNN,成了最主要的自然语言处理特征提取工具。
图4 给出了预训练语言模型的发展史。

图4 预训练语言模型的发展史
可以看到,2013 年,word2vec 开启了自然语言预训练的序章。
随后,Attention的出现使得模型可以关注更重要的信息,之后的几年,基于上下文的动态词向量表示ELMo,以及使用Self-Attention 机制的特征提取器Transformer的提出,将预训练语言模型的效果提升到了新的高度。
随后,BERT、RoBERTa、XLNet、T5、ALBERT、GPT-3 等模型,从自然语言理解及自然语言生成等角度,不断刷新自然语言处理领域任务的SOTA 表现。
《预训练语言模型》一书的后面章节会详细介绍典型的预训练语言模型。这里,我们简单区分自回归(Autoregressive)和自编码(Autoencoder)两种不同的模型。
简单来讲,自回归模型可以类比为早期的统计语言模型(Statistical Language Model),也就是根据上文预测下一个单词,或者根据下文预测前面的单词。例如,ELMo 是将两个方向(从左至右和从右至左)的自回归模型进行了拼接,实现了双向语言模型,但本质上仍然属于自回归模型。
自编码模型(如BERT),通常被称为是降噪自编码(Denosing Autoencoder)模型,可以在输入中随机掩盖一个单词(相当于加入噪声),在预训练过程中,根据上下文预测被掩码词,因此可以认为是一个降噪(denosing)的过程。
这种模型的好处是可以同时利用被预测单词的上下文信息,劣势是在下游的微调阶段不会出现掩码词,因此[MASK] 标记会导致预训练和微调阶段不一致的问题。
BERT 的应对策略是针对掩码词,以80% 的概率对这个单词进行掩码操作,10% 的概率使用一个随机单词,而10% 的概率使用原始单词(即不进行任何操作),这样就可以增强对上下文的依赖,进而提升纠错能力。
XLNet 改进了预训练阶段的掩码模式,使用了自回归的模式,因此XLNet 被看作广义的自回归模型。
国际计算语言学协会(The Association for Computational Linguistics)主席、微软亚洲研究院前副院长周明曾给出了一个关于自回归和自编码模型的示例,如图5所示。

图5 自回归模型和自编码模型的示例
自回归模型,就是根据句子中前面的单词,预测下一个单词。
例如,通过“LM is a typical task in natural language ____”预测单词“processing”;而自编码模型,则是通过覆盖句中的单词,或者对句子做结构调整,让模型复原单词和词序,从而调节网络参数。
在图5 (a) 所示的单词级别的例子中,句子中的“natural”被覆盖,而在图5 (b) 所示的句子级别的例子中,不仅有单词的覆盖,还有词序的改变。
可以看出,ELMo、GPT 系列和XLNet 属于自回归模型,而BERT、ERINE、RoBERTa 等属于自编码模型。
前文提到,在利用CNN 进行图像的预训练时,浅层特征更加通用,深层特征更加具体。通过对BERT 的观察,研究人员发现预训练语言模型也有相同的表现,随着模型由浅至深,特征也更具体。
图6 给出了针对BERTLARGE提取语义和语法信息的结果,其中,语法信息(Syntactic Information),如词性(Part-Of-Speech,POS)、成分(Constituents)、依存(Dependencies)更早出现在BERTLARGE 的浅层,而语义信息(Semantic Information),如共指消解(Coreference)、语义原型角色(Sementic Proto-Roles,SPR)等则出现在BERTLARGE 的深层。
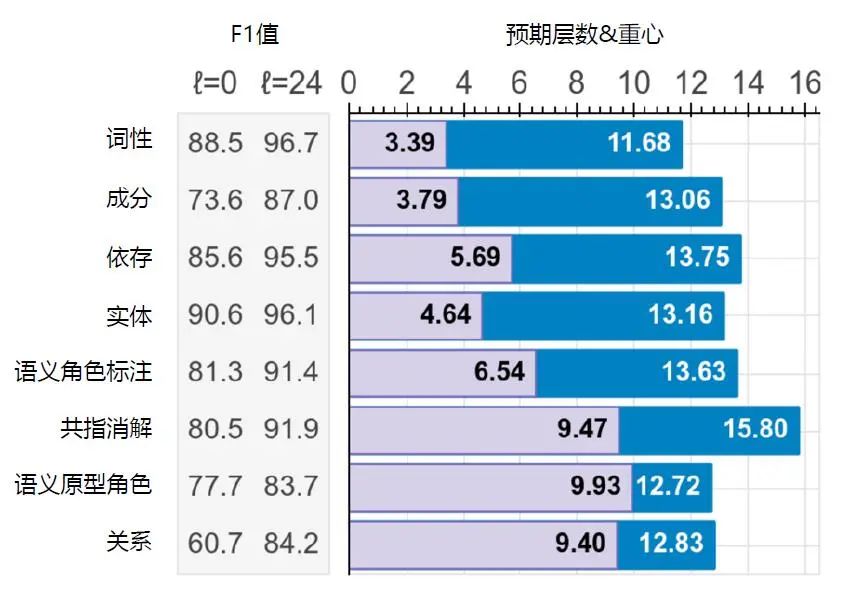
图6 BERTLARGE 提取语义和语法信息的结果
目前,预训练语言模型的通用范式是:
(1)基于大规模文本,预训练得出通用的语言表示。
(2)通过微调的方式,将学习到的知识传递到不同的下游任务中。
在微调的过程中,每种预训练语言模型的用法不尽相同,《预训练语言模型》一书的后面章节将对典型的模型进行详细阐述。
这里以GPT为例,简单介绍在预训练之后,在下游,不同的自然语言处理任务的具体用法如图7所示。
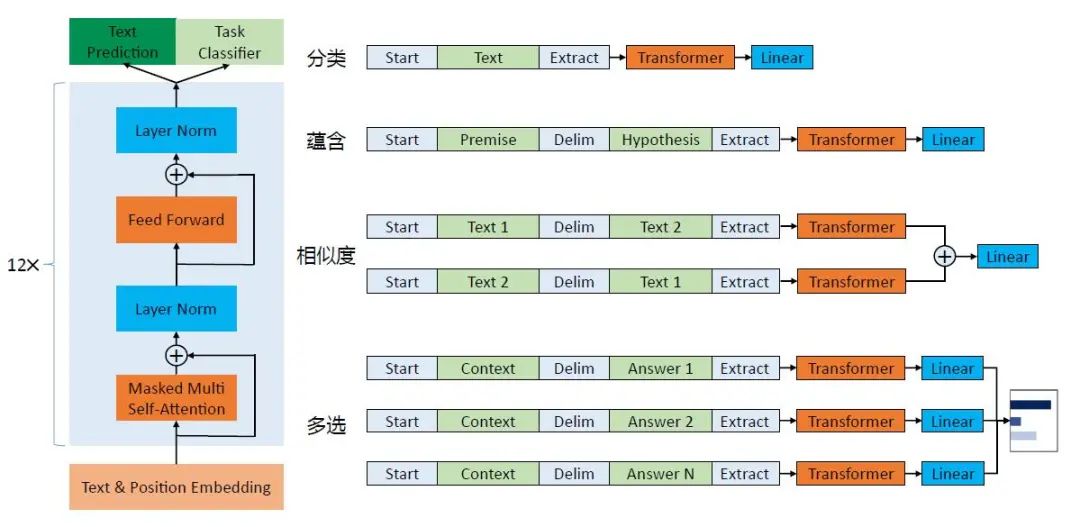
图7 GPT 架构图及下游任务
图7的左边,是基于Transformer 的GPT 的基本框架,而图7的右边则展示了如何将不同的自然语言处理任务调整至适应GPT 框架的形式。
以分类任务为例,在一段文本的开头和结尾分别加上“Start”和“Extract”标示符对其进行改造,然后使用Transformer 进行处理,最后通过线性层(Linear)完成监督学习任务,并输出分类结果。
类似地,对于多选(Multiple Choice)任务,需要根据上下文(Context)选择正确答案(Answer)。
具体来说,如图7所示,将答案“Answer”,与其上下文“Context”通过添加首尾标示符及中间分隔符的方式进行改造,对其他答案进行相同的操作,然后分别经过Transformer,再经过线性层,得到每一个选项的可能性概率值。
由于不同的预训练语言模型的结构不同、优势不同,在实际应用中,需要根据具体的任务选择不同的模型。例如,BERT 系列模型更适用于理解任务,而GPT 系列模型更适用于生成任务。
预训练语言模型在近两年得到了蓬勃发展,复旦大学的邱锡鹏教授在Pretrained models for natural language processing: A survey这篇综述论文中整理了一张预训练语言模型分类体系图,图8为笔者翻译后的版本。
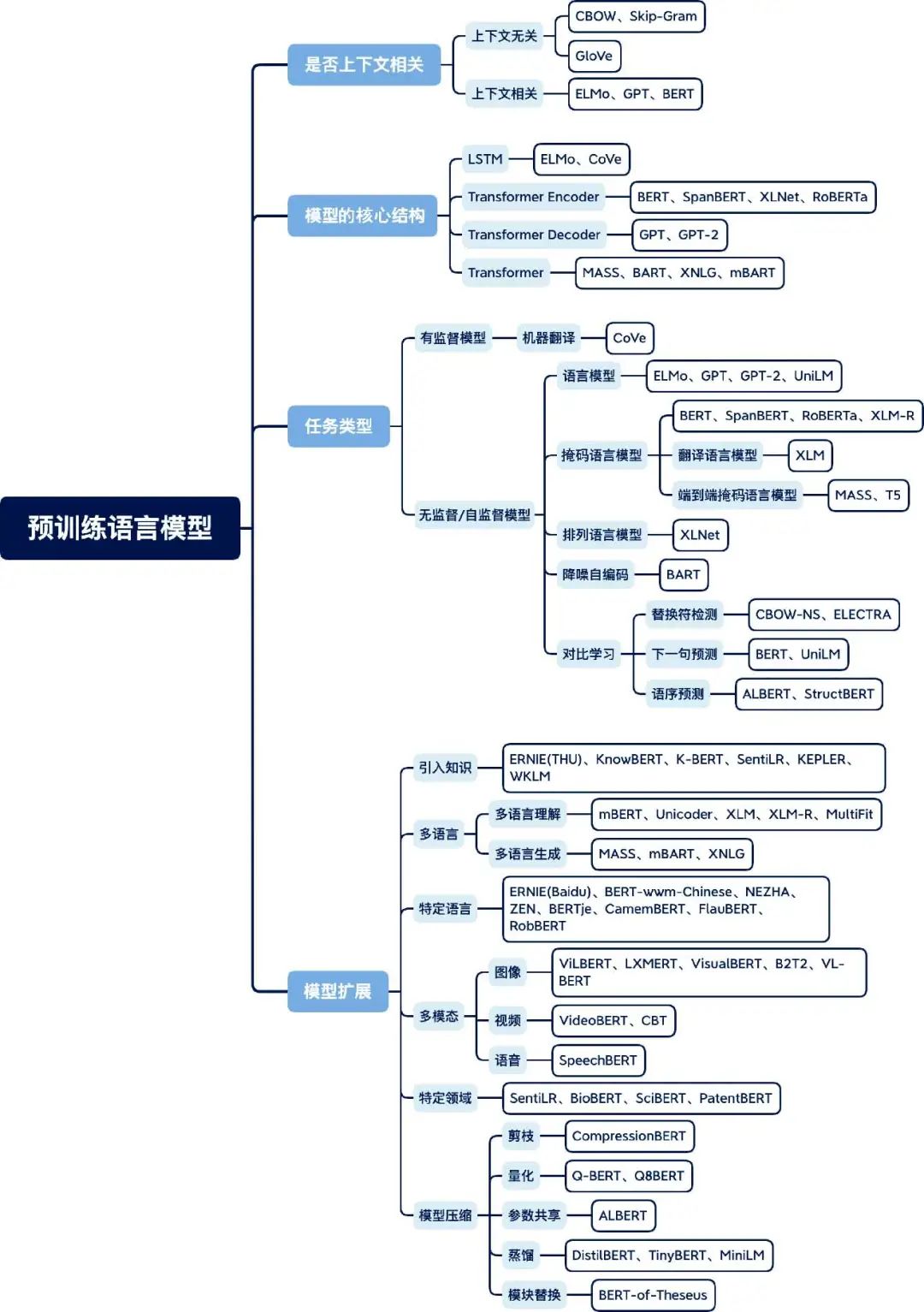
图8 预训练语言模型分类体系图
依据四种不同的分类标准,对主流预训练语言模型进行了分类整理。
第一个标准是语言表示是否上下文相关。正如前文提到的,早期的预训练语言模型(如word2vec、GloVe)都是上下文无关的,而ELMo 之后的大多数预训练语言模型都是上下文相关的。
第二个标准是模型的核心结构。例如,ELMo 使用的是双向LSTM 结构,而BERT 的核心结构是Transformer Encoder,GPT 的核心结构是Transformer Decoder。
第三个标准是任务类型,可以分为有监督模型和无监督/自监督模型两类。例如,机器翻译模型(训练数据通常是句对)属于有监督模型,如CoVe等,而大多数预训练语言模型都属于无监督/自监督模型,如ELMo、BERT等。
第四个标准是模型扩展。随着预训练语言模型的发展,出现了不同的扩展方向,如模型结构的扩展、领域的扩展、任务的扩展和模态的扩展等。
每个模型的细节,在《预训练语言模型》一书的后面章节会有更详细的介绍。

预训练语言模型为自然语言处理开启了新的篇章,模型结构和训练方法不断创新,从单语言到多语言,再到多模态,几乎支持了所有自然语言处理任务,并可扩展到视觉、语音等领域,大大降低了自然语言处理研究和应用的门槛。
周明曾提到:“大数据预训练+ 小数据微调,标志着自然语言处理进入了大工业化的时代。”但GPT-3 的“大力出奇迹”(有1750 亿参数量)是否真正标志着人工智能从感知智能到认知智能的跨越?预训练语言模型的缺陷在哪里?未来的发展趋势如何?《预训练语言模型》一书的第8章对这些问题进行了探讨,感兴趣的同学可以阅读《预训练语言模型》一书!
▼
参考文献:
[1] MIKOLOV T, CHEN K, CORRADO G S, et al. Efficient estimation of word representations in vector space[C]//ICLR. 2013.
[2] PENNINGTON J, SOCHER R, MANNING C D. Glove: Global vectors for word representation[C]//EMNLP. 2014.
[3] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]//NAACL-HLT. 2018.
[4] TENNEY I, DAS D, PAVLICK E. Bert rediscovers the classical nlp pipeline [C]//ACL.
AI 前线为粉丝准备了《预训练语言模型》纸质书籍 5 本!长按识别下图小程序,参与抽奖活动,由小程序随机抽出 5 位,每人赠送一本书。开奖时间:6 月 16 日(下周三) 18:00,获奖者每人获得一本。(点击阅读原文可获取购买链接,现京东限时活动,快来参加)


👇购买请戳