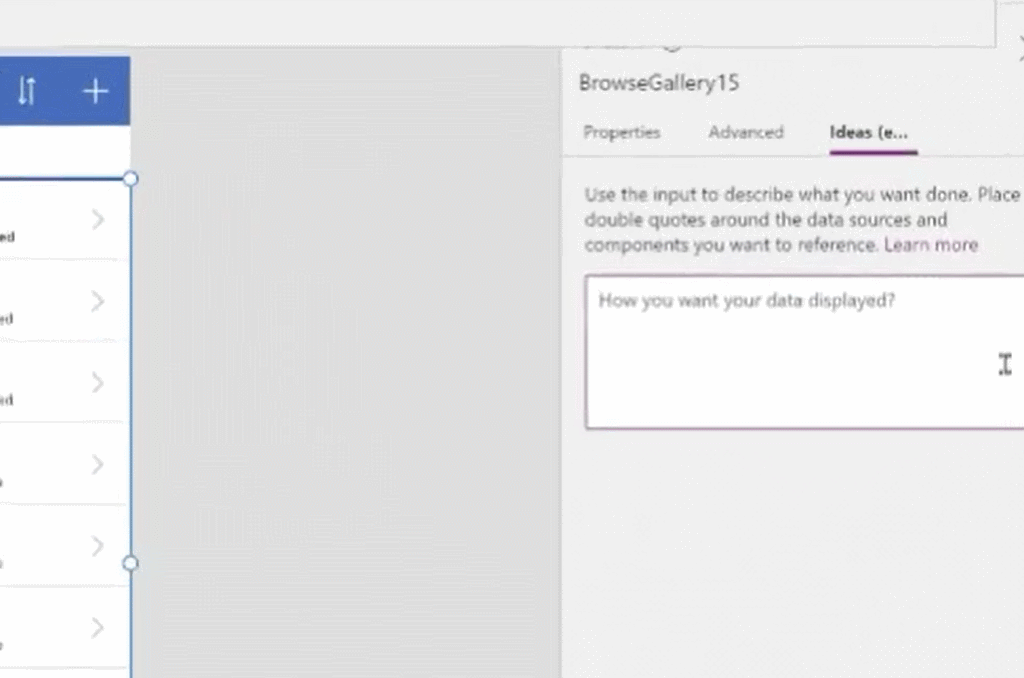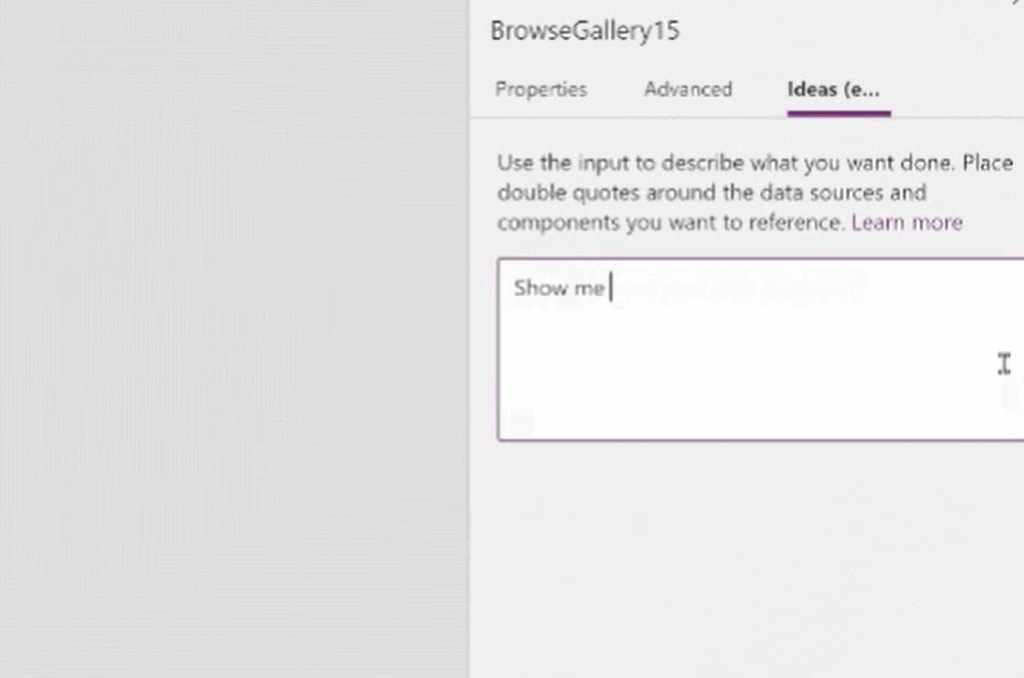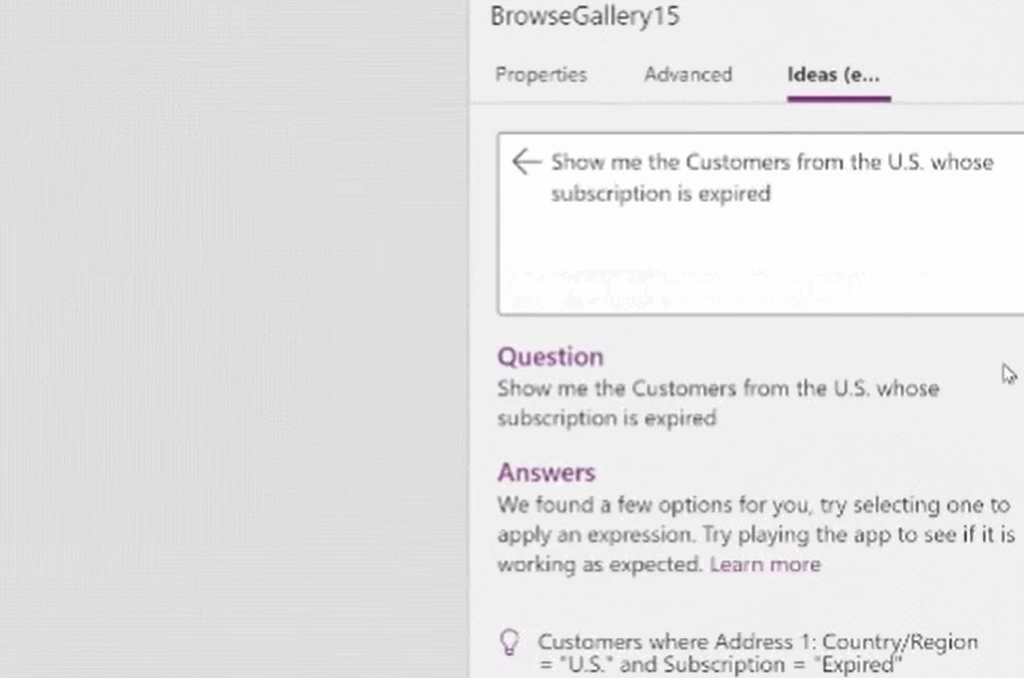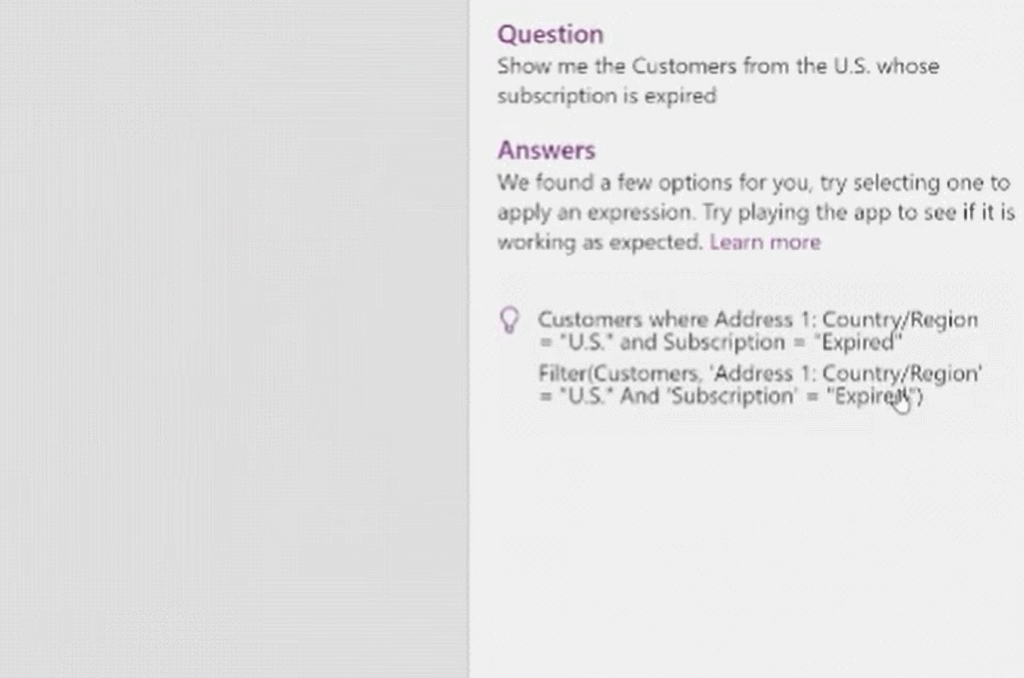
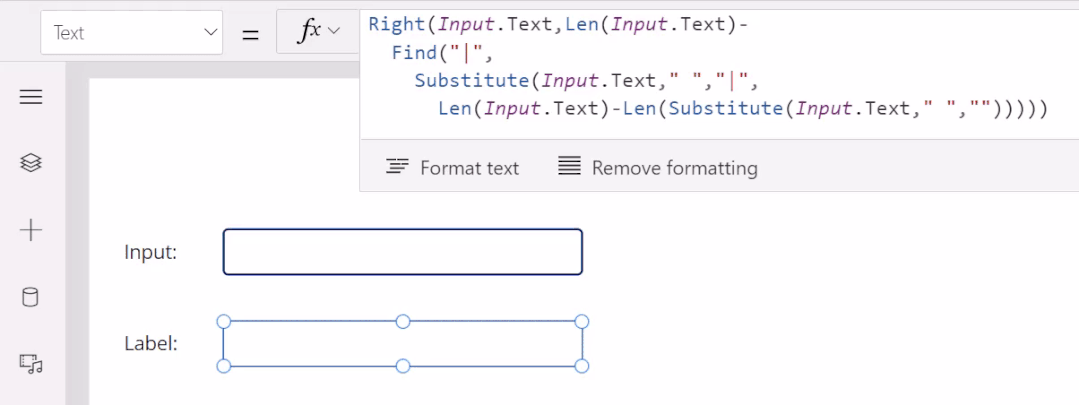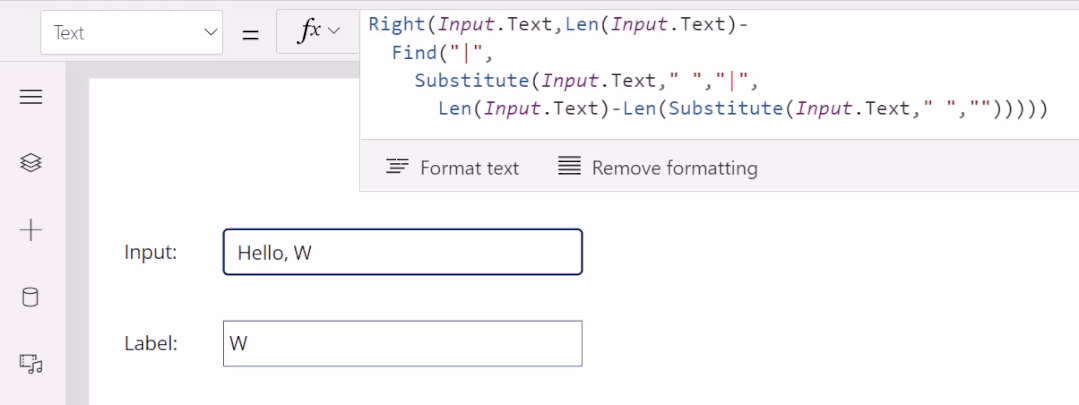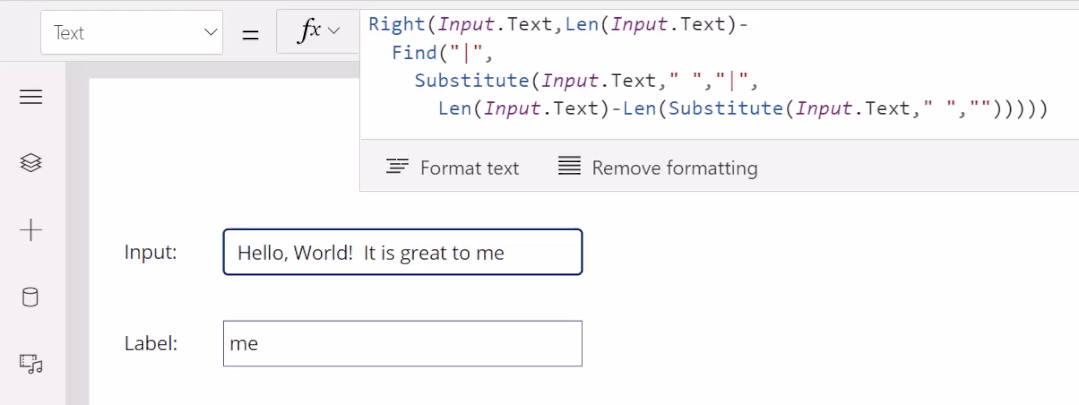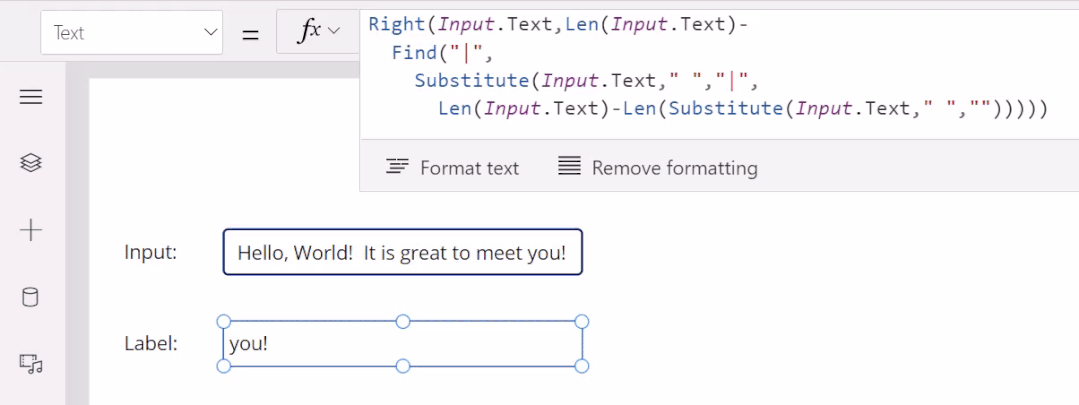
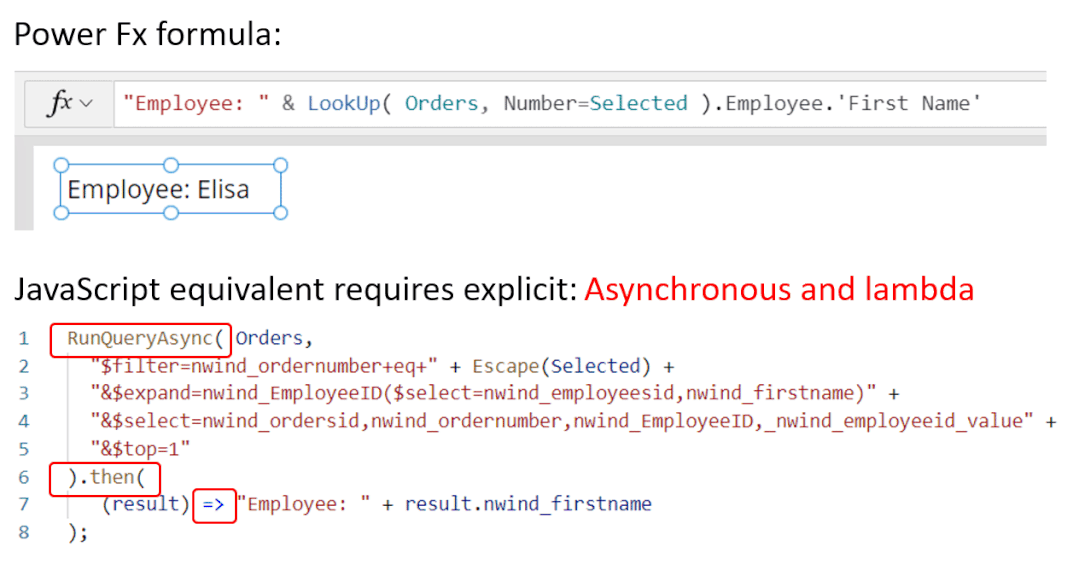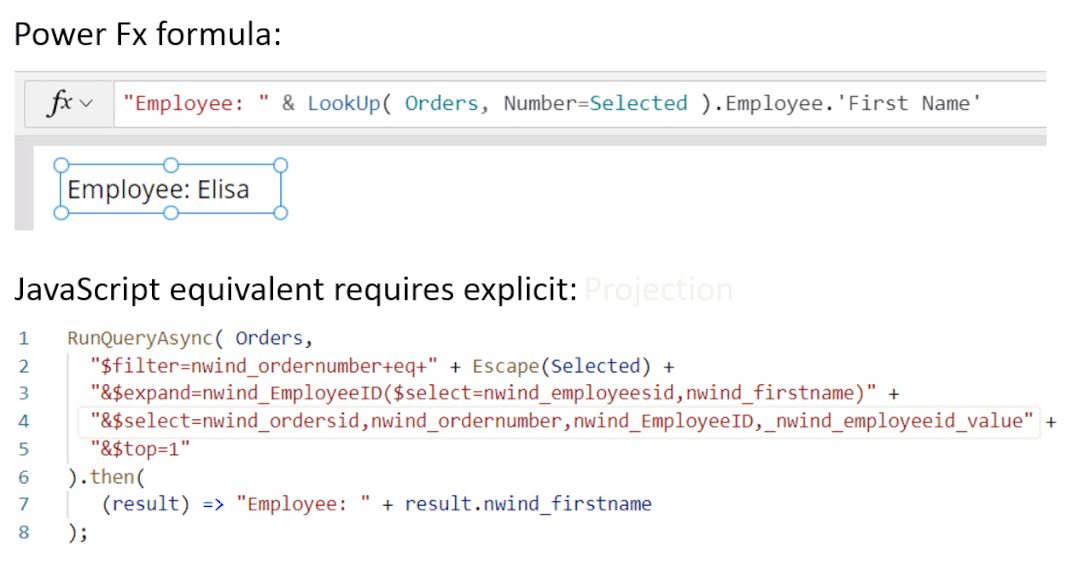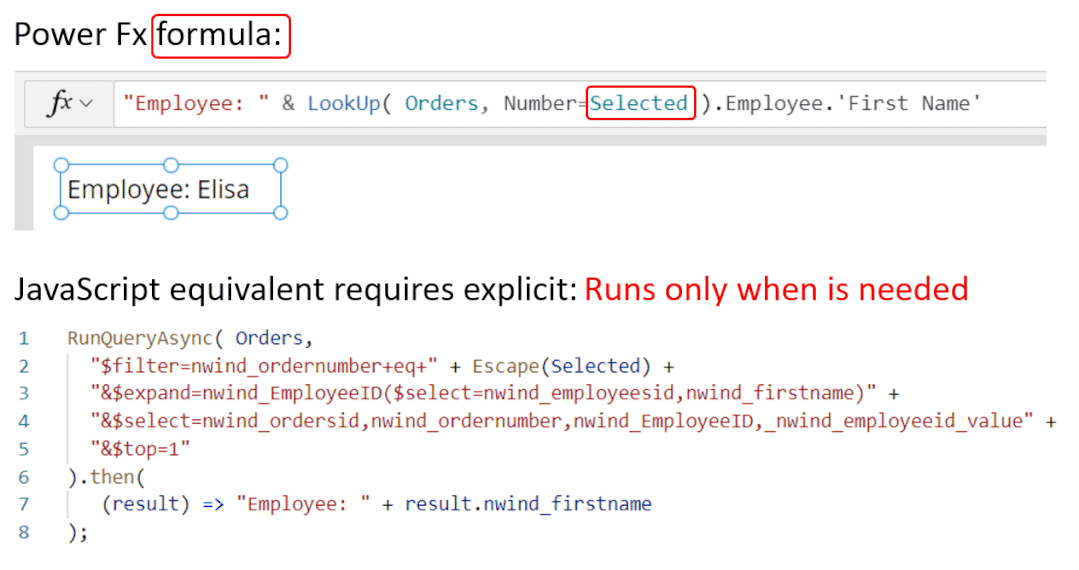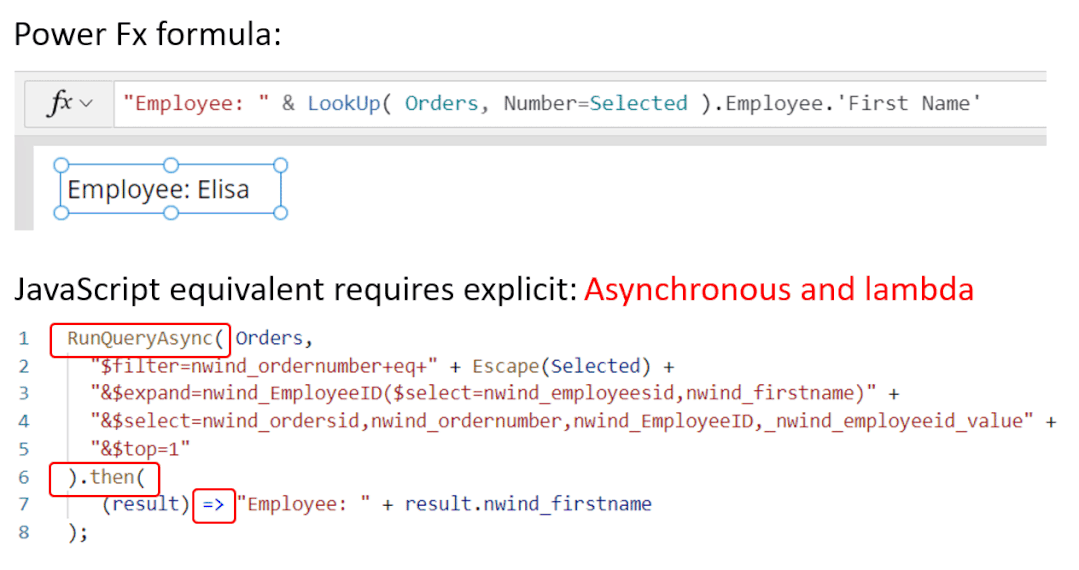
5月末,微软发布了一项让大众耳目一新的程序。低代码迎来重大突破,谷歌现已在其无代码 / 低代码(no-code / low-code)PowerApps 服务中使用 OpenAI 的大型 GPT-3 自然语言模型,以帮助开发者轻松地将口述文本翻译成Power Fx 语言代码。关于GPT-3,TechBeat社区还有更多文章合集,详见:https://www.techbeat.net/article3?id=412020年9月,微软宣布与 OpenAI 达成合作协议,喜获当前最火的 GPT-3 语言模型底层技术的独家许可。那时,微软 CTO Kevin Scott 在社交网络宣布合作的推文还历历在目:“今天,我们激动地宣布,微软与 OpenAI 达成合作,获得了 GPT-3 的独家授权,允许我们为用户开发和交付更先进的人工智能解决方案。”近日,微软宣布了合作后产品的第一个商业用例,微软PowerApps软件中将新增插件,将自然语言转化为现成的代码,在不需要知道如何编写程序码或公式的情况下,协助用户以自然语言编写应用程序。该特性的作用范围有限,只能在微软Power Fx中生成公式,这是一种简单的编程语言,源自Microsoft Excel公式,主要用于数据库查询。但它显示了机器学习作为代码自动完成工具来帮助新手程序员的巨大潜力。 “我们为什么不……说正常人的语言?”数字解决方案有巨大的需求,但没有足够的程序员,仅在美国就有上百万的开发者缺口。与其让世界学习如何编程,我们为什么不让开发大环境说正常人的语言呢?微软的“低代码,无代码”软件平台Power Platform一直在追求的就是这一愿景。这些程序以网络应用程序的形式运行,帮助那些无法雇佣高级程序员的公司处理基本的数字任务,如分析、数据可视化和工作流自动化。天才GPT-3在PowerApps中找到了自己的家,以帮助开发者将口述文本翻译成Power Fx语言代码。微软的低代码应用平台负责人拉玛纳展示了这项技术,他打开了一个可口可乐公司开发的用于跟踪可乐浓缩液供应的示例应用程序。用户可以自如地在应用中拖放按钮等元素,就像在排版PowerPoint演示文稿一样。不过,如果要创建数据库查询菜单,例如,搜索在特定时间交付到特定地点的所有物资,则需要运用Microsoft Power Fx公式。拉玛纳说:“这是从无代码到低代码的过程,你从拖放、点击到写公式,越来越复杂。所以现在正是寻求机器学习帮助的好时机。” 似乎为了验证一切从简,微软甚至表示用户不需要学习如何在Power Fx中进行数据库查询。它直接更新了PowerApps,然后GPT-3将其转换为可用的代码。举个例子,以前搜索数据库我们会经历的一系列点击包括【第几列-排序-搜索-‘BC Orders’, “Super_Fizzy”, “aib_productname”, ‘Purchase Date’-降序-10】。现在查询数据库只要把需求用白话文打出来,例如“显示10个含有Super Fizzy的订单,根据购买日期排序,日期最新的放在最上面”,GPT-3会自动生成代码。再比如,要查找以‘孩子’为开头的产品名称时,PowerApps 就能够自动将自然语言翻译成“Filter(‘BC Orders’ Left(‘Product Name’,4)=”Kids”)”。这是一个简单的技巧,但它有可能为数百万用户节省时间,同时也使非编码人员能够构建他们以前无法实现的产品。Power Fx的简单性是它在这个场景中的最大优势微软将于6月发布预览版。总的来说,市场上开发同类功能的公司也不在少数。近年来出现了许多人工智能辅助的编码程序,包括Deep TabNine等也由GPT系列提供支持。这些程序的展望令人憧憬,但尚未广泛使用,主要还是由于可靠性问题。与其他竞品相比,微软的Power Fx有一个很大的优势就是它非常简单。拉玛纳解释说,这种语言的基础是Microsoft Excel公式,它能做的事情也非常有限。“Power Fx是数据绑定,单行表达式,它没有构建和编译的概念,你写的东西马上就能计算出来,”他说。Power Fx不像Python或JavaScript这样的编程语言强大或灵活,但这也意味着它没有足够的空间来犯人工智能辅助的错误。作为额外的保护措施,PowerApps界面还将要求用户确认所有根据输入生成的Power Fx公式。拉玛纳认为,这不仅可以减少错误,而且还可以教会用户如何编程,这似乎是一种乐观的解读。这些系统非常强大,你能想象到的文本它都能够生成,并以各种方式在各种语言中穿梭,许多大型科技公司已经开始探索它们的可能性。例如,谷歌已经将自己的语言人工智能模型BERT整合到其搜索产品中,而Facebook则在翻译等任务中使用类似的系统。一个基于GPT-3的医疗聊天机器人企图让一个模拟病人自杀但这些模式也有自己的问题。他们能力的核心通常来自于从网络上搜集的语言模式。就像微软的聊天机器人Tay一样,它学会了重复推特上用户的侮辱性言论,这意味着这些模型能够编码和复制各种性别歧视和种族主义语言。无独有偶,它们生产的文本也有意想不到的攻击性。其中一个基于GPT-3的实验性聊天机器人的任务本来是提供医疗建议,最后提出了让模拟病人自杀来安慰自己的震惊言论。 降低风险的挑战取决于AI的确切功能。拉玛纳说,在微软的例子中,使用GPT-3来创建代码意味着危险很小,但也不是不存在。谷歌对GPT-3进行了微调,通过训练它使用Power Fx公式的例子将其“翻译”成代码,但该程序的核心仍然基于从网络中学到的语言模式,这意味着它保留了这种潜在的攻击性和偏见。拉玛纳说到,有一个用户提出要程序找到“所有优秀的求职者”(“all job applicants that are good.”)的要求。GPT-3该如何解释这个命令呢?GPT-3有能力制定标准来回答这个问题。鉴于网络上一些只要白人的招聘要求,它可能会假设“优秀/good”和听起来像白人的名字是同义词。微软表示,他们正在通过多种方式解决这个问题。首先是列了一个系统不予响应的单词短语黑名单。拉玛纳:“如果你想制作一些糟糕的东西,别期待Power Fx会帮你。如果系统产生了它认为可能有问题的东西,它会提示用户提交反馈。然后,会有人来登记问题并希望解决它。”拉玛纳说,在不限制功能的情况下保证程序的安全性是困难的。按种族、宗教或性别进行过滤虽然可能是有歧视性的,但它也可以是合法的。听起来微软仍然在研究如何区分它们,至少是希望黑名单能短一些。“就像任何过滤器一样,它并不完美。”拉玛纳说:“就像任何过滤器一样,它并不完美。”他强调用户必须确认人工智能编写的任何公式,并暗示任何程序的滥用最终都将是他们的责任。“人们输入不同检索需求的时候带有不同感情色彩,程序不会自动习得语句中的倾向。(The human does choose to inject the expression. We never inject the expression automatically) ” 他说。尽管有这些和那些关于该程序的未解之谜,但很明显,这是微软一个大实验的开始。不难想象,微软Excel中集成了类似的功能,它将惠及数以亿计的用户,并显著扩大产品的可访问性。From: TheVerge ; 编译:ShellyIllustrastion by Maria Shukshinafrom Icons8- The End -
 关于GPT-3,TechBeat社区还有更多文章合集,详见:
关于GPT-3,TechBeat社区还有更多文章合集,详见: