100张图训练1小时,照片风格随意变,文末有Demo试玩|SIGGRAPH 2021
以下文章来源于字节跳动技术范儿 ,作者字节跳动技术范儿
字节跳动官方技术分享,你想看的技术实践、招聘资讯、成长生活都在这里。

照片变画像,现在已经有了最新的技术。
正常的人物照片:

可以自动变成卡通电影里的角色,眼睛大大的、皮肤看上去滑滑的,还保留了不少原本的人物特征:

也可以变成武侠游戏风格,女生下巴尖尖,男生头发飘逸,仿佛下一秒就要去修仙了:

或者变成油画里的人物,面部轮廓依旧饱满,但光影线条和质感却传达了一种文艺复兴的气质:

更特别的风格也不成问题,比如先看这两张人物照片:

可以变成手绘,睫毛、嘴唇、头发,每个细节的笔触都异常真实:

变成雕塑,看上去就像在博物馆拍的照片一样:

或者素描,看上去仿佛走进了美术学院的教室,连右图人物的镂空耳坠都可以翔实地刻画出来:

变身人偶娃娃,立体感相当强,简直像网店的精修商品图:

无论男女老幼、肤色发型相貌特征如何,都能实现非常好的效果:




创造这些变化的模型,名叫AgileGAN,字节跳动海外技术团队与新加坡南洋理工大学联合出品,已经中选图形学顶会SIGGRAPH 2021。
让模型生成如此精美、高清的图片,是不是要堆海量的数据和算力?
非也。
训练一个新的风格,仅仅需要男女各100张左右的图片做训练集,在一块英伟达Tesla V100上训练一个小时,就可以获得生成1024×1024高清晰度图片的模型。
甚至借此模型,你可以实现丰富的照片编辑功能。比如这样的原图:

可以修改生成照片的光影效果,拍照时逆光也可以拯救:

甚至修改生成照片的角度:

这项技术的研发团队也正在计划将其应用到抖音、飞书等产品上,或许不久的将来,你就可以在这些App上获得更有趣的互动体验了。
不过一个好消息是,现在,AgileGAN已放出了Demo(链接见文末),你也可以用自己的、亲朋的、idol 的照片来试试啦。
1
怎样的GAN才能画出如此逼真的效果?
生成这些效果的模型由两个部分组成:
前端是分层变分自编码器映射(hVAE)输入图片到StyleGAN2隐空间;后端是解码的风格化生成器。
两部分都基于预训练的StyleGAN2——一种可以生成各种人脸的GAN模型。

StyleGAN2生成的各种人脸
StyleGAN2的图像生成有两个隐空间,一个是具有标准高斯分布的Z空间;另一个是通过一系列非线性映射得到W空间,W空间是解耦的,但是分布非常复杂。通常,业界研发人员在用StyleGAN2重建一张用户输入的图片时,一般会选用W空间。
但这次,研究团队发现如果能让图片影射的隐空间的分布,符合原始的StyleGAN2隐空间的高斯分布,在生成各种风格图片时,就可以减少噪声,生成更好看的图片。
为了到达这样的目的,团队舍弃了常用的W空间,从而选择具有标准高斯分布的Z空间;并且增加了它的分层维度去表达更加复杂的图片。
之后,他们又利用变分表达去模拟分布,然后训练这样的前端分层变分自编码器,这个编码器的后端则是预训练的StyleGAN2的生成器。
为了更好地生成用户属性特征,他们还提出了一种属性感知生成器,在StyleGAN2的预训练模型基础上,微调了生成器,让它能够生成卡通、手绘等各种不同的风格。并采用了一种动态停止策略,以避免过度拟合小型训练数据集。
这两个训练阶段是可以独立执行的,可以并行训练。
这里引入的分层变分自动编码器,结构如图:

最后,如何衡量AgileGAN的生成效果?
从两个角度来评价,一是「美不美」,是否是能满足用户的偏好;二是「像不像」,生成的图片需要像美术风格。
为了判断「美不美」,研究团队找到了100名吃瓜群众,为每人展示随机的10张生成的图片,生成他们的模型包括AgileGAN及此前几个知名模型生成的图片,让他们选出效果最好的图片。
结果,正如下表中间一列所示,57.9%的选票都投给本作AgileGAN。
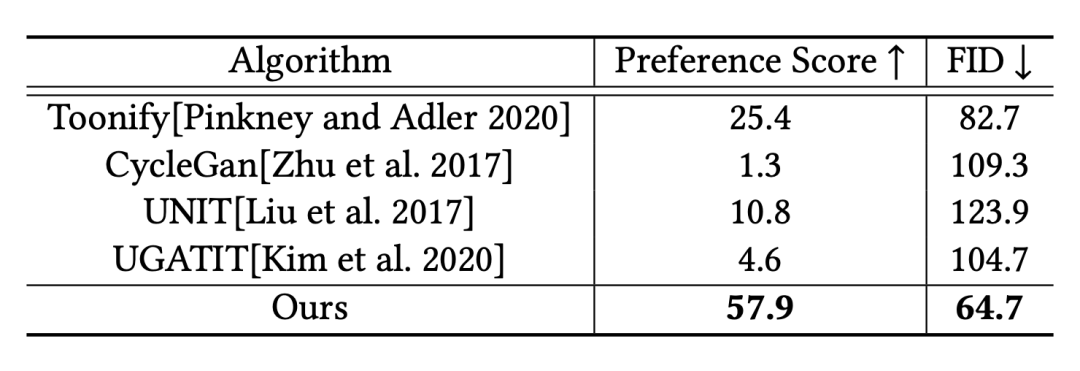
而为了验证「像不像」,他们评估了几个GAN模型的Fréchet Inception Distance(FID)——一种常见的给GAN打分的方法,比较美术风格和生成图像的神经网络特征分布,分数越低,图像越「保真」,AgileGAN仍然是最高保真的模型。
2
字节跳动智能创作北美团队出品
AgileGAN的实现经历了长达8个月的过程,他们最初的灵感来源于在社交网站看到的一组绘画作品,一位艺术家将各种人像画成了卡通画。这些作品不仅具有卡通画的夸张表达,有圆圆的脑袋、大大的眼睛和飘逸的头发,而且恰到好处地保留了原本人像的面部特征,有的鼻梁高挺,有的眼窝深邃。
他们想到,如果让算法来生成类似的效果,就可以为用户提供更好、更有趣的互动体验。
因此,他们尝试了SEAN、CycleGAN、MUNIT以及3D warpping等多种不同的方案,在每种不同思路上做了大量优化和调试,不断寻求业界最先进、最实用的解决方案,在核心的效果问题上攻坚克难,最终选择了Toonify与StyleGAN相结合的思路,并发现了其中的一些核心的局限性,创造性的解决了问题,让模型产出最极致的效果。今年8月,AgileGAN也会在图形学顶会SIGGRAPH 2021上进行展示。
除了AgileGAN之外,base在山景城和洛杉矶两座城市的字节跳动智能创作团队成员们还做过包括3D、虚拟人、图像生成在内的各种与人物形象相关的技术。
比如,变身油画框里的蒙娜丽莎:

或者给人物戴上虚拟的假发,如果你仔细看,会发现这些动态的假发不仅造型逼真,还能契合场景中真实的光线与阴影。

还有「变身美女」特效道具,让用户看到性转的自己长什么样子:

换个造型,「光头挑战」:

「动态老照片」道具,让多年前的你也可以动起来:

让静态的照片动起来,就像霍格沃兹墙上的画像一样,还能随着人的动作一起舞蹈:

这些多种多样的效果都会应用在抖音、TikTok等应用上,为用户带来更丰富与新奇的体验。