机器之心 & ArXiv Weekly Radiostation
本周的重要论文包括复旦大学邱锡鹏教授团队发布的关于 Transformer 变体的论文综述以及谷歌用 AI 在六小时内自动完成芯片布局设计的最新方案。
Scaling Local Self-Attention for Parameter Efficient Visual Backbones
X-volution: On the Unification of Convolution and Self-attention
Stochastic Iterative Graph Matching
A graph placement methodology for fast chip design
Reward Is Enough
A Survey of Transformers
Recent Advances and Trends in Multimodal Deep Learning: A Review
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Scaling Local Self-Attention for Parameter Efficient Visual Backbones摘要:与卷积的参数依赖(parameter-dependent)缩放和内容无关(content-independent)交互相比,注意力场具有与参数无关的缩放和与内容有关的交互,因此自注意力机制有望改善计算机视觉系统。近来的研究表明,与 ResNet-50 等基线卷积模型相比,自注意力模型在准确性 - 参数权衡方面有重要改进。在一篇 CVPR 2021 Oral 论文中,来自谷歌研究院和 UC 伯克利的研究者开发了一种新的自注意力模型,该模型不仅可以超越标准的基线模型,而且可以超越高性能的卷积模型。具体而言,该研究提出了自注意力的两个扩展,并与自注意力的更高效实现相结合,提高了这些模型的运行速度、内存使用率和准确率。研究者利用这些改进开发了一种新的自注意力模型——HaloNet,并且在 ImageNet 分类基准的有限参数设置上准确率实现了新 SOTA。在迁移学习实验中,该研究发现 HaloNet 模型的性能优于更大的模型,并且具有更好的推理性能。在目标检测和实例分割等较难的任务上,该研究简单的局部自注意力和卷积混合算法在非常强大的基线上显示出性能提升。这些实验结果标志着在卷积模型主导的传统环境下,自注意力模型又迈出了新的一步。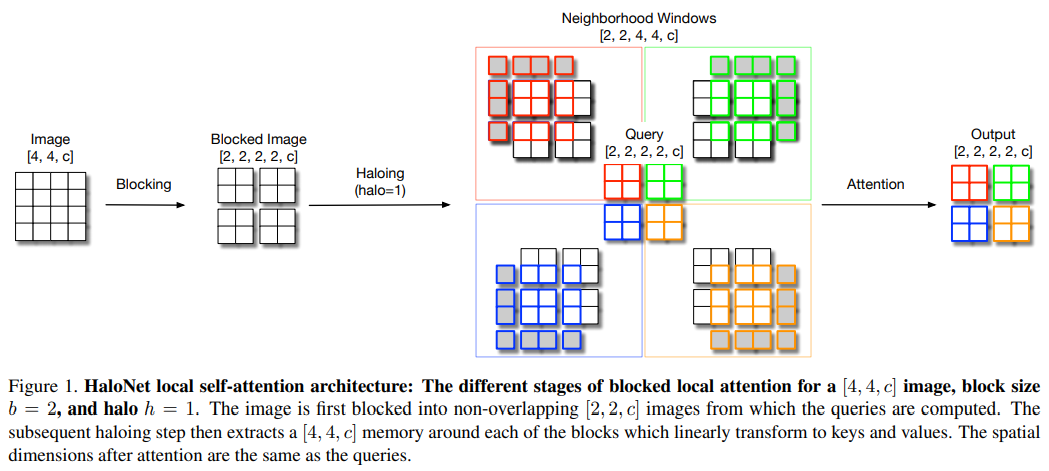
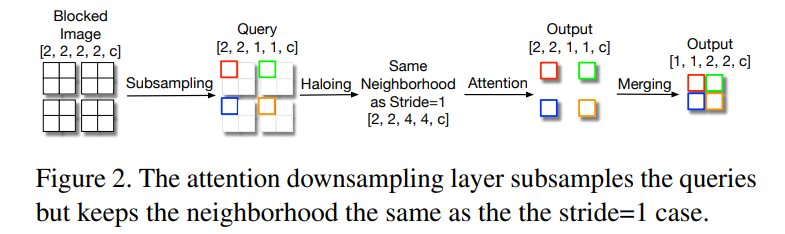
推荐:CVPR 2021,超越标准的基线模型和高性能的卷积模型。论文 2:X-volution: On the Unification of Convolution and Self-attention摘要:卷积操作(convolution)与自注意力操作(self-attention)是深度学习两大核心的基础网络计算单元(或称为模型算子)。然而,由于卷积运算与自注意力运算在计算模式上的异构性,这项任务存在巨大的挑战。目前学界中的一些工作也在努力统一两者,他们主要从拓扑结构组合角度来粗粒度地结合两种算子,例如,发表在 ICCV 2019 上的 AA-Net 采用了一种将卷积中部分通道替换为由 self-attention 来处理,然后将卷积和 self-attention 分别处理的特征连接来达到联合两种算子的目的,这种做法证明了卷积和 self-attention 结合后确实能在分类、检测、分割等基础任务上达到比较可观的性能收益。然而,粗粒度的组合(本质上就是两路计算并联)会导致其组合后网络形态可用性下降。具体来说,卷积和 self-attention 运算模式存在较大差异,两者同时存在会导致网络结构不规则,进而影响网络推理效率,并不为目前一些工业界通用的芯片计算架构所友好支持。同时组合后的算子在算力上也存在巨大的挑战。针对这些挑战,日前,上海交大 - 华为海思联合团队在 arXiv 上发表了「X-volution: On the Unification of Convolution and Self-attention」,首次在计算模式上统一了这两大基础算子,并在推理阶段归并成一个简单的卷积型算子:X-volution。X-volution 兼顾卷积与自注意力操作的互补优势,并且在现有通用网络计算框架上不需要额外算子支持,也不增加除卷积外的额外算力或影响网络的规范性 / 可用性(即插即用)。具体来说,本文作者提出了一种新型的 self-attention 机制——PSSA。PSSA 实际上将 self-attention 巧妙地转化为了一个在简单变换后的特征上的标准的卷积操作,这从形式上实现了 self-attention 向卷积的统一。利用此逼近式的 self-attention 机制,作者建立了一个多分枝的模块将卷积和 self-attention 整合在一起,这个模块从功能上实现了两者的统一,并在分类、检测、分割等主流 SOTA 实验上取得了显著的性能提升。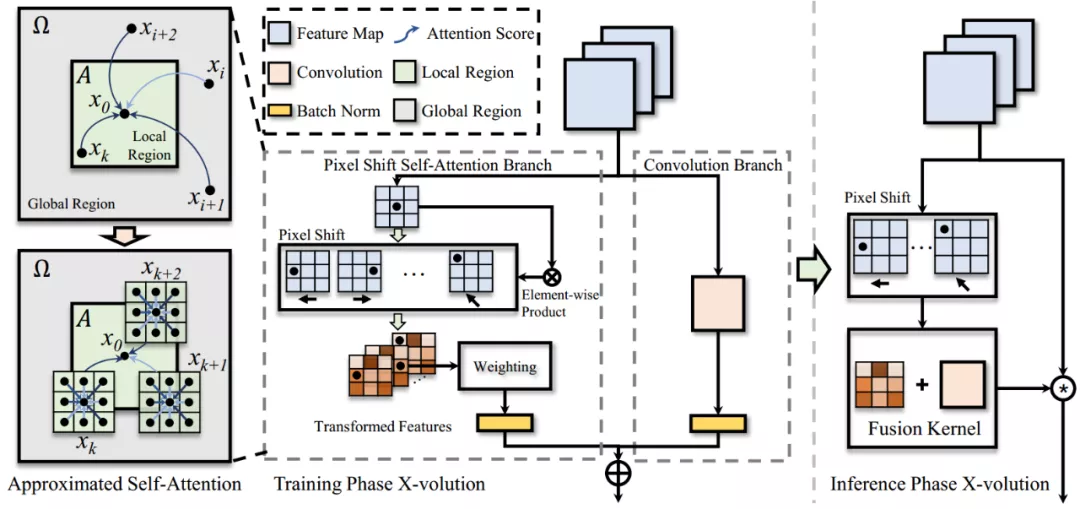
推荐:兼顾卷积与自注意力操作的互补优势,不需要额外算子支持,在分类、检测、分割等主流 SOTA 实验上取得了显著的性能提升。论文 3:Stochastic Iterative Graph Matching摘要:近来,利用图神经网络(GNN)来处理图匹配任务的研究已经展现出了良好的结果。离散分布学习的最新进展则为学习图匹配模型提供了新的机遇。在这篇论文中,来自塔夫茨大学的研究者提出了一个新模型 Stochastic Iterative Graph MAtching (SIGMA),用于解决图匹配问题。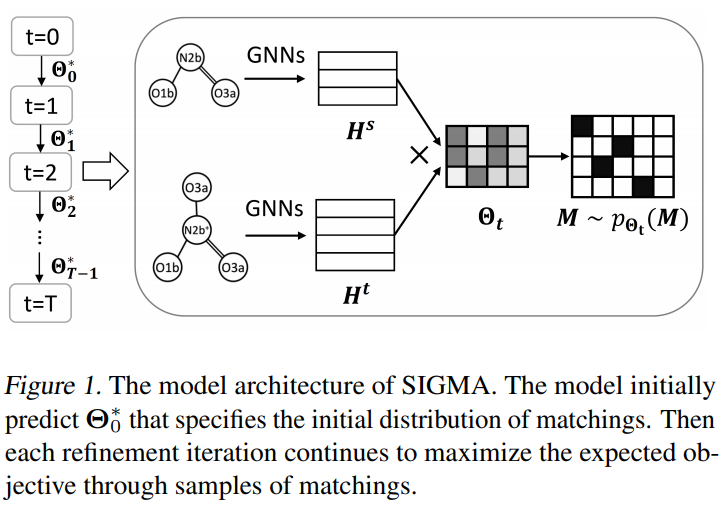
论文 4:A Graph Placement Methodology for Fast Chip Design摘要:2020 年 4 月,包括 Google AI 负责人 Jeff Dean 在内的谷歌大脑研究者描述了一种基于 AI 的芯片设计方法,该方法可以从过往经验中学习并随时间推移不断改进,从而能够更好地生成不可见(unseen)组件的架构。据他们表示,这种基于 AI 的方法平均可以在 6 小时内完成设计,这要比人类专家所需要的数周时间快得多。近日,谷歌大脑团队联合斯坦福大学的研究者对这一基于 AI 的芯片设计方法进行了改进,并将其应用于不久前 Google I/O 2021 大会上正式发布的、下一代张量处理单元(TPU v4)加速器的产品中。谷歌此前表示,TPUv4 可以在目标检测、图像分类、自然语言处理、机器翻译和推荐基准等工作负载上优于上一代 TPU 产品。相关论文研究已经在 Nature 上发表,Jeff Dean 为核心作者之一。据介绍,在不到六小时的时间内,谷歌 AI 芯片设计方法自动生成的芯片布局在功耗、性能和芯片面积等所有关键指标上都优于或媲美人类,而工程师需要耗费数月的艰苦努力才能达到类似效果。这项基于强化学习的快速芯片设计方法对于资金紧张的初创企业大有裨益,如果谷歌公开相关技术的话,这些初创企业可以开发自己的 AI 和其他专用芯片。并且,这种方法有助于缩短芯片设计周期,从而使得硬件可以更好地适应快速发展的技术研究。

推荐:缩短芯片设计周期,生成的芯片布局在功耗、性能和芯片面积等所有关键指标上都优于或媲美人类。摘要:几十年来,在人工智能领域,计算机科学家设计并开发了各种复杂的机制和技术,以复现视觉、语言、推理、运动技能等智能能力。尽管这些努力使人工智能系统在有限的环境中能够有效地解决特定的问题,但却尚未开发出与人类和动物一般的智能系统。人们把具备与人类同等智慧、或超越人类的人工智能称为通用人工智能(AGI)。这种系统被认为可以执行人类能够执行的任何智能任务,它是人工智能领域主要研究目标之一。关于通用人工智能的探索正在不断发展。近日强化学习大佬 David Silver、Richard Sutton 等人在一篇名为《Reward is enough》的论文中提出将智能及其相关能力理解为促进奖励最大化。该研究认为奖励足以驱动自然和人工智能领域所研究的智能行为,包括知识、学习、感知、社交智能、语言、泛化能力和模仿能力,并且研究者认为借助奖励最大化和试错经验就足以开发出具备智能能力的行为。因此,他们得出结论:强化学习将促进通用人工智能的发展。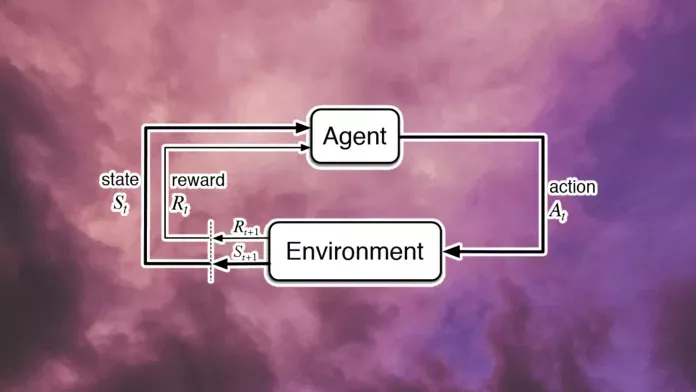
论文 6:A Survey of Transformers摘要:自 2017 年 6 月谷歌发布论文《Attention is All You Need》后,Transformer 架构为整个 NLP 领域带来了极大的惊喜。在诞生至今仅仅四年的时间里,Transformer 已经成为自然语言处理领域的主流模型,基于 Transformer 的预训练语言模型更是成为主流。随着时间的推移,Transformer 还开始了向其他领域的跨界。得益于深度学习的发展,Transformer 在计算机视觉(CV)和音频处理等许多人工智能领域已然杀疯了,成功地引来了学界和业界研究人员的关注目光。到目前为止,研究者已经提出了大量且种类驳杂的 Transformer 变体(又名 X-former),但是仍然缺失系统而全面的 Transformer 变体文献综述。去年,谷歌发布的论文《Efficient Transformers: A Survey》对高效 Transformer 架构展开了综述,但主要关注 attention 模块的效率问题,对 Transformer 变体的分类比较模糊。近日,复旦大学计算机科学技术学院邱锡鹏教授团队对种类繁多的 X-former 进行了综述。首先简要介绍了 Vanilla Transformer,提出 X-former 的新分类法。接着从架构修改、预训练和应用三个角度介绍了各种 X-former。最后概述了未来研究的一些潜在方向。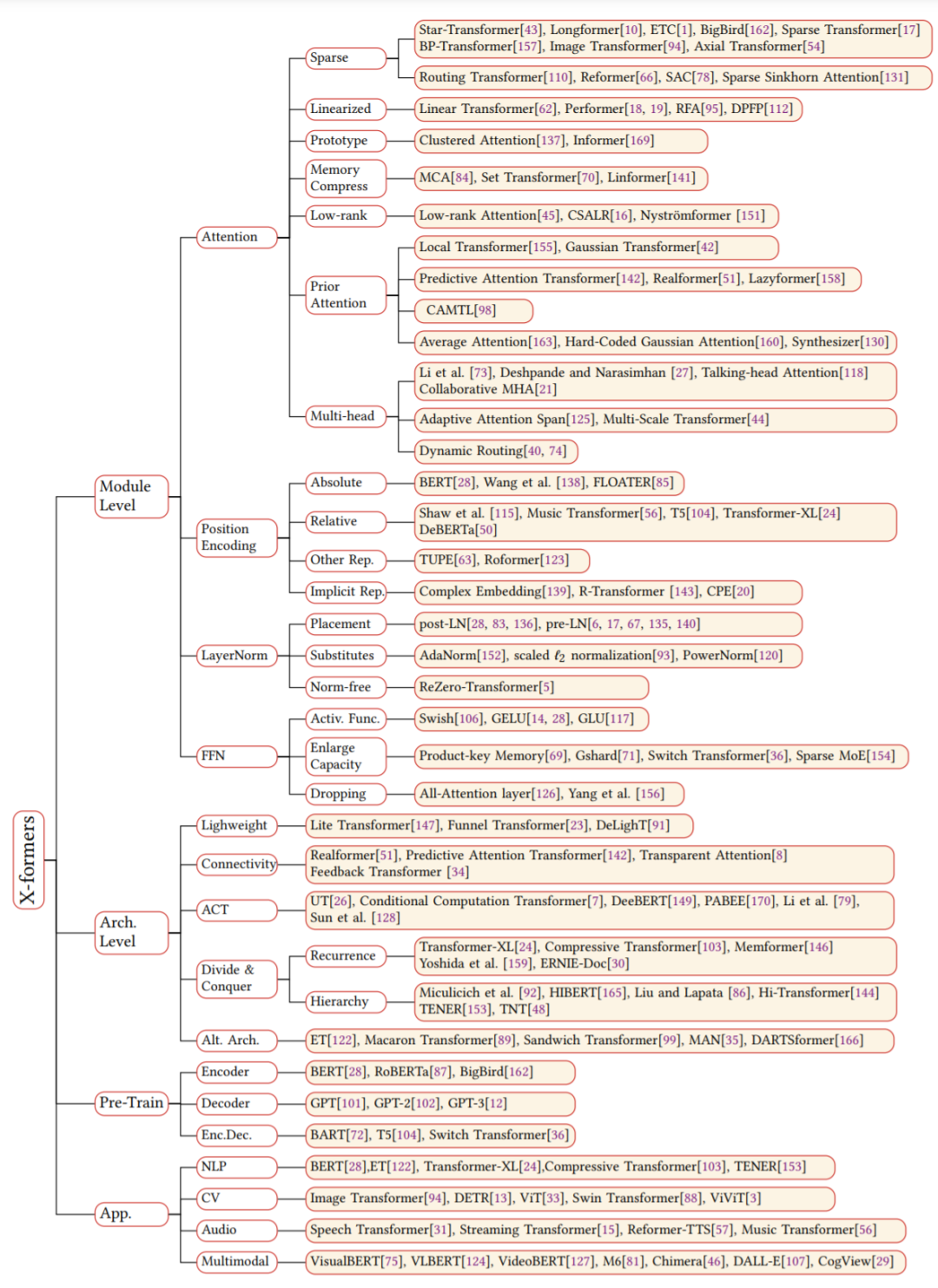
论文 7:Recent Advances and Trends in Multimodal Deep Learning: A Review摘要:在深度学习领域,多模态学习有助于更好地理解和分析不同感官参与信息处理的过程。本文中,来自浙江大学和华东师范大学的研究者详细分析了过去和当前的基准方法,并对多模态深度学习应用的最新进展进行了深入研究。
ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:10 NLP Papers.mp3 来自机器之心 00:00 20:18
1. Are Pretrained Transformers Robust in Intent Classification? A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection. (from Philip S. Yu)2. Progressive Multi-Granularity Training for Non-Autoregressive Translation. (from Dacheng Tao)3. Neural Abstractive Unsupervised Summarization of Online News Discussions. (from Evangelos Milios)4. Measuring Conversational Uptake: A Case Study on Student-Teacher Interactions. (from Dan Jurafsky)5. Scalable Transformers for Neural Machine Translation. (from Xiaogang Wang)6. Prediction or Comparison: Toward Interpretable Qualitative Reasoning. (from Yang Gao)7. Improving Automated Evaluation of Open Domain Dialog via Diverse Reference Augmentation. (from Eduard Hovy)8. NAST: A Non-Autoregressive Generator with Word Alignment for Unsupervised Text Style Transfer. (from Minlie Huang)9. MultiOpEd: A Corpus of Multi-Perspective News Editorials. (from Dan Roth)10. UniKeyphrase: A Unified Extraction and Generation Framework for Keyphrase Prediction. (from Wei Liu)10 CV Papers.mp3 来自机器之心 00:00 20:50
1. NeRF in detail: Learning to sample for view synthesis. (from Andrew Zisserman)2. DETReg: Unsupervised Pretraining with Region Priors for Object Detection. (from Trevor Darrell)3. Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering. (from William T. Freeman, Joshua B. Tenenbaum, Fredo Durand)4. Learning to See by Looking at Noise. (from Phillip Isola, Antonio Torralba)5. SOLQ: Segmenting Objects by Learning Queries. (from Xiangyu Zhang)6. Curiously Effective Features for Image Quality Prediction. (from Thomas Wiegand)7. Novel View Video Prediction Using a Dual Representation. (from Mubarak Shah)8. Hierarchical Video Generation for Complex Data. (from Aaron Courville)9. Glance-and-Gaze Vision Transformer. (from Alan Yuille)10. Progressive Stage-wise Learning for Unsupervised Feature Representation Enhancement. (from Alan Yuille, Wen Gao)10 ML Papers.mp3 来自机器之心 00:00 20:18 本周 10 篇 ML 精选论文是:
1. Phase Retrieval using Single-Instance Deep Generative Prior. (from Vipin Kumar)2. Vector Quantized Models for Planning. (from Sherjil Ozair, Oriol Vinyals)3. Conditional Contrastive Learning: Removing Undesirable Information in Self-Supervised Representations. (from Louis-Philippe Morency, Ruslan Salakhutdinov)4. Integrating Auxiliary Information in Self-supervised Learning. (from Ruslan Salakhutdinov, Louis-Philippe Morency)5. SketchGen: Generating Constrained CAD Sketches. (from Niloy Mitra, Leonidas Guibas)6. Hash Layers For Large Sparse Models. (from Jason Weston)7. Staircase Attention for Recurrent Processing of Sequences. (from Jason Weston)8. GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings. (from Jure Leskovec)9. Pretraining Representations for Data-Efficient Reinforcement Learning. (from Aaron Courville)10. A Variational Perspective on Diffusion-Based Generative Models and Score Matching. (from Aaron Courville)© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com