只需两行代码,2080Ti 就能当 V100用,这个炼丹神器真牛!

作者 | 陈大鑫、青暮
 。
。

“魔法”从何而来


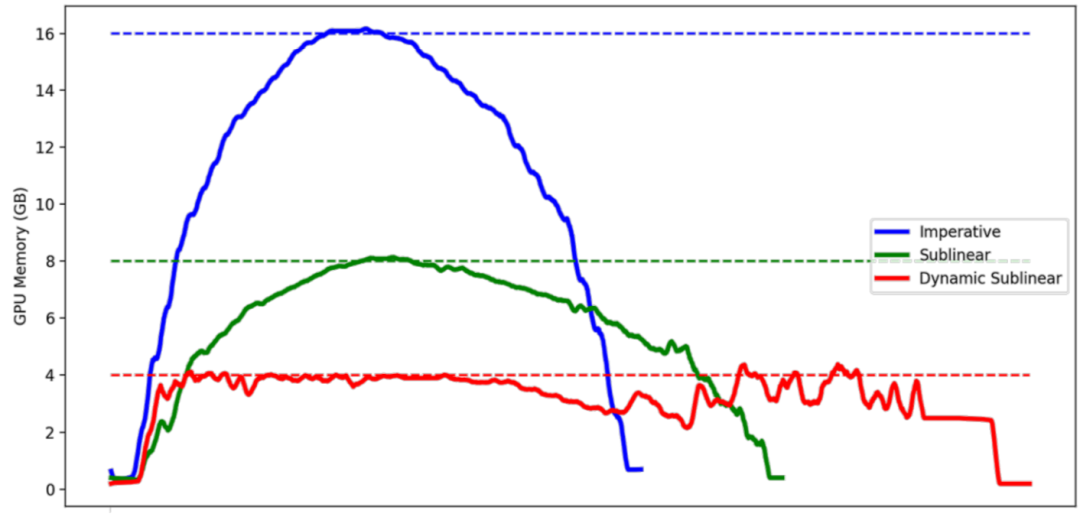
实验数据对比
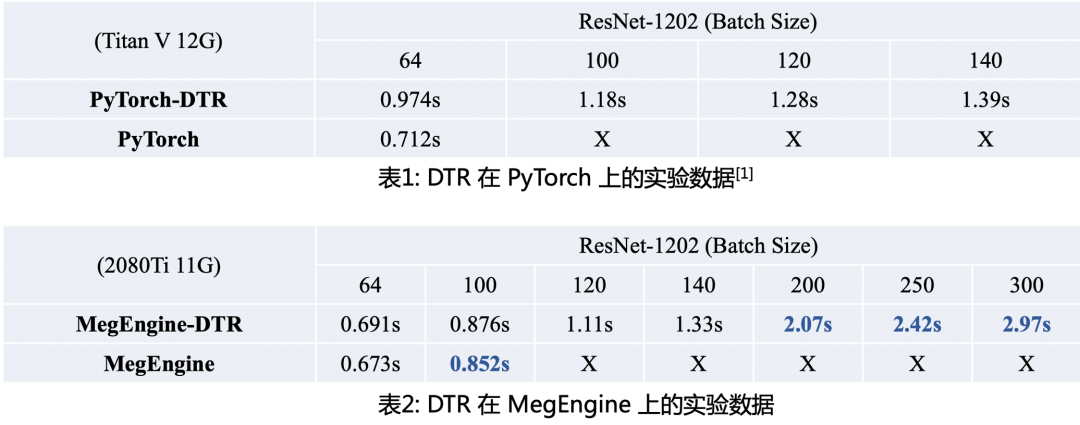
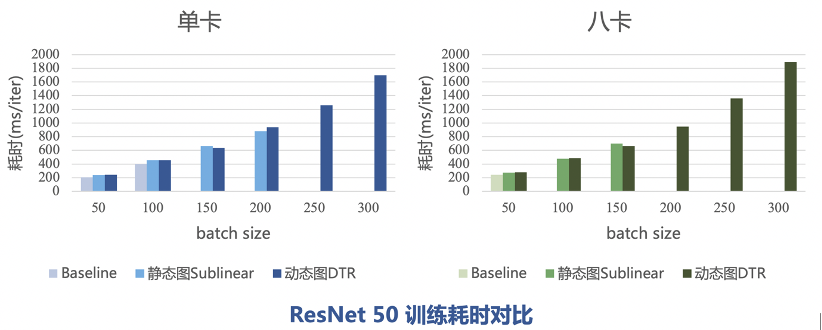
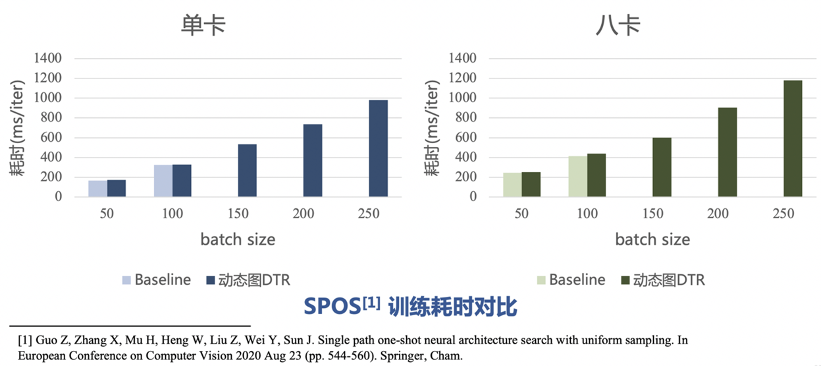
牺牲的计算时长由DTR的参数决定,最坏情况下所有 Tensor 在不被用到的时候都立即释放,恢复每个 Tensor 的时间都是 O(N)的,总的时间就会达到 O(N^2) 级别。但一般情况下只是原来的时间的常数倍。
例如训练 batchsize=200 的 ResNet50 需要 16G 左右的显存,每轮的训练耗时是800ms。设置DTR的阈值为7G时,只需要 11G 的显存,训练耗时为 898ms;设置DTR的阈值为3G时,只需要 7.5G 的显存,训练耗时为 1239ms。
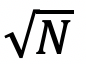 倍,这里的 O(1/
倍,这里的 O(1/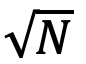 )是对于n层的前馈神经网络的理论下界。
)是对于n层的前馈神经网络的理论下界。总结
 点击“阅读原文” 链接一键直达MegEngine动态图显存优化(DTR)的实现与优化路径。
点击“阅读原文” 链接一键直达MegEngine动态图显存优化(DTR)的实现与优化路径。