进阶的PVT——更灵活鲁棒的视觉Transformer基准模型
PVT(Pyramid Vision Transformer)作为 Transformer 应用于视觉领域的代表性模型之一,在诸多任务上取得了优异的结果。最近在PVT的基础上,研究人员为其添加了重叠片元嵌入编码、卷积前传网络和线性复杂度的注意力层等功能模块,实现了PVTv2模型,大幅提升了在图像分类、目标检测和分割等任务上的性能,为研究领域提供了功能更为强大、可用的基准模型。

一、持续演进的PVT模型
视觉 Transformer 领域最近的研究工作不断推动着主干网络的设计和进步,为像图像分类、目标检测、实例语义分割等下游任务提供更好的基础架构。从 Vision Transformer 首次验证纯 Transformer 架构可以在视觉任务上实现优异的性能开始,一系列优异的视觉Transformer模型不断涌现,Pyramid Vision Transformer(PVT) 模型甚至在某些方面可以超过基于 CNN 的模型,Swin Transformer、CoaT、LeViT、Twins 等模型的提出进一步提升了 Transformer 作为下游任务主干网络的性能。
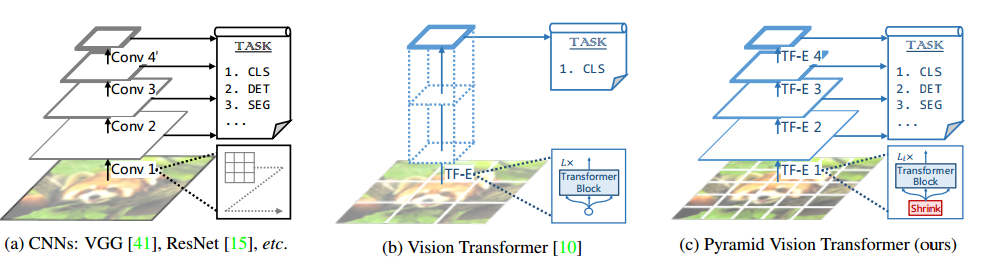
PVTv1与ViT和CNNs系列的模型架构的对比
二、改进的金字塔
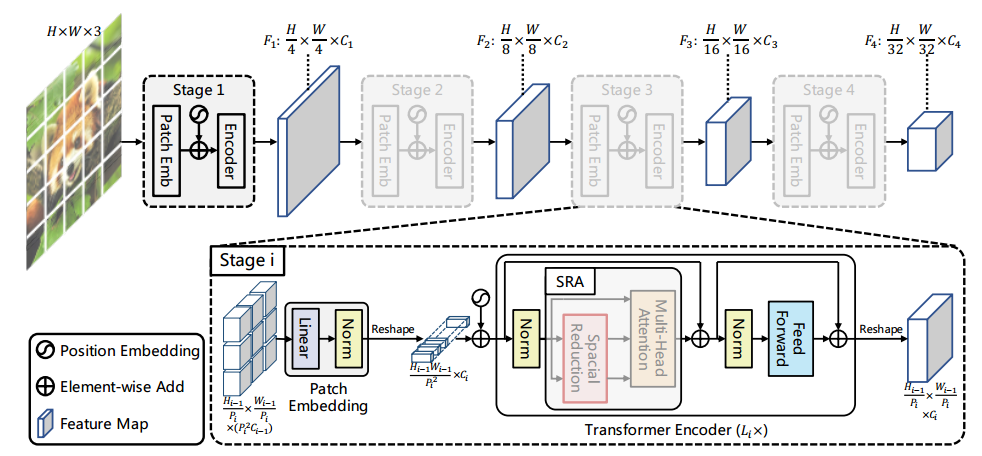
PVTv1系列的模型架构,其中图像片元彼此不重叠造成了局域信息不连续性。
首先,与 ViT 相同 PVTv1 将图像视为一系列非重叠的片元序列,这样对图像的非重叠切片与编码会在一定程度上损失图像中原有的连续性;其次,PVTv1 中的位置编码为固定尺寸,对于任意尺度的图像处理缺乏灵活性。当高分辨率的图像输入时,PVTv1 的计算复杂度就会飙升,大大降低了模型的性能。为了改善 PVTv1 中存在的问题,研究人员从三个方面对原有模型进行了改进。
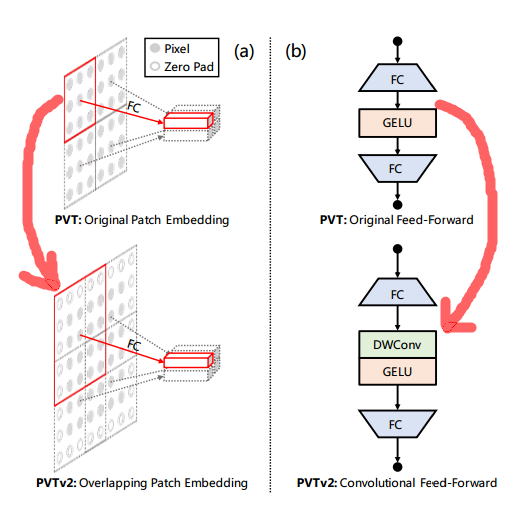
重叠片元 (patch) 嵌入编码。在 PVTv2 中使用了重叠片元嵌入来对图像进行编码。上图左侧展示了重叠片元操作的示意图,图中每个片元的窗口尺寸被放大、与相邻窗口互相重叠一半,同时对特征图进行0填充操作。而后使用卷积对填充后特征图进操作实现嵌入编码。具体来讲,给定 hxwxc 的输入,应用步长为S、尺寸为2S-1的卷积,填充大小为S-1,使用c’个卷积核最终获得 h/S x w/S x C’的输出结果。
卷积前传。为了解决图像大小灵活性的问题,在新版的 PVT 中固定位置编码被移除,并引入了填充零的位置编码机制,上图右侧显示了在前传网络和全连接层间插入的3x3零填充逐深度卷积。
线性空间缩减注意力机制。为了进一步优化PVT的计算开销,线性空间注意力 (Spatial Reduction Attention, SRA) 机制被引入到新的模型中来。与原始的SRA不同,线性空间注意力机制具有线性的计算复杂度和内存开销,对于输入为hxwxc的特征图,与SRA相比线性SRA的复杂度大大降低:
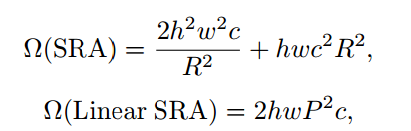
其中R是SRA的空间缩减比例,P是线性SRA中的池化大小,在PVTv2中被设置为7。
通过这三方面的改进,PVTv2不仅可以保证图像和特征图的局域连续性,同时可灵活处理不同尺度的输入信号,还能将计算复杂度控制在线性范围内。
为了充分探索 PVTv2 的实验性能,下表列出了一系列配置下的 PVTv2 模型家族,其中S、C、R、P、N、E、L分别代表了重叠片元的步长、输出通道数、SRA的缩减比例、池化大小、注意力头数量、前传网络层的拓展比例、编码器的层数。
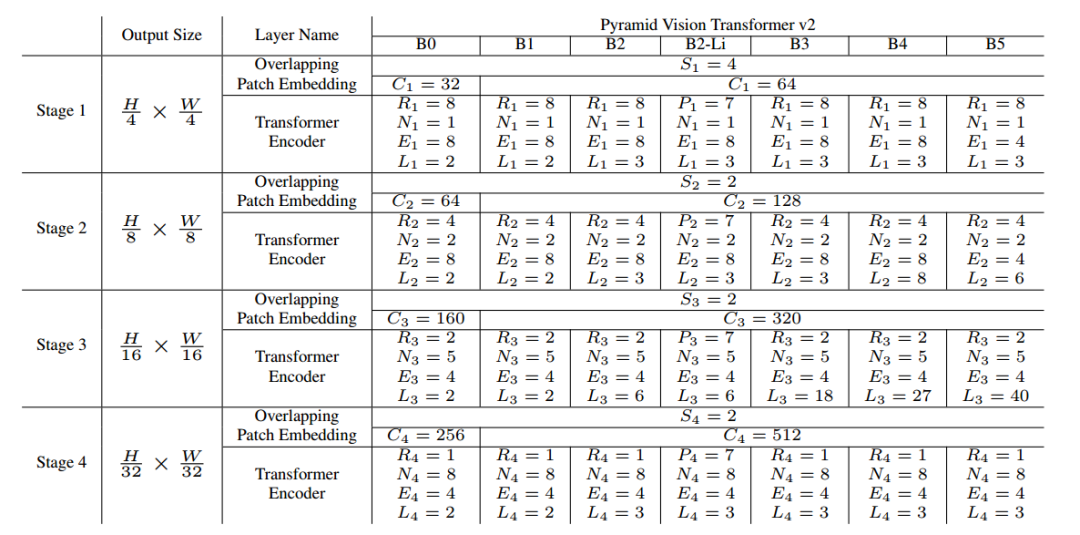
PVTv2系列的模型架构参数表
其设计原理参考了ResNet的思想,随着空间分辨率的缩小提升通道数量、第三阶段赋予最大的计算开销。
三、实验验证
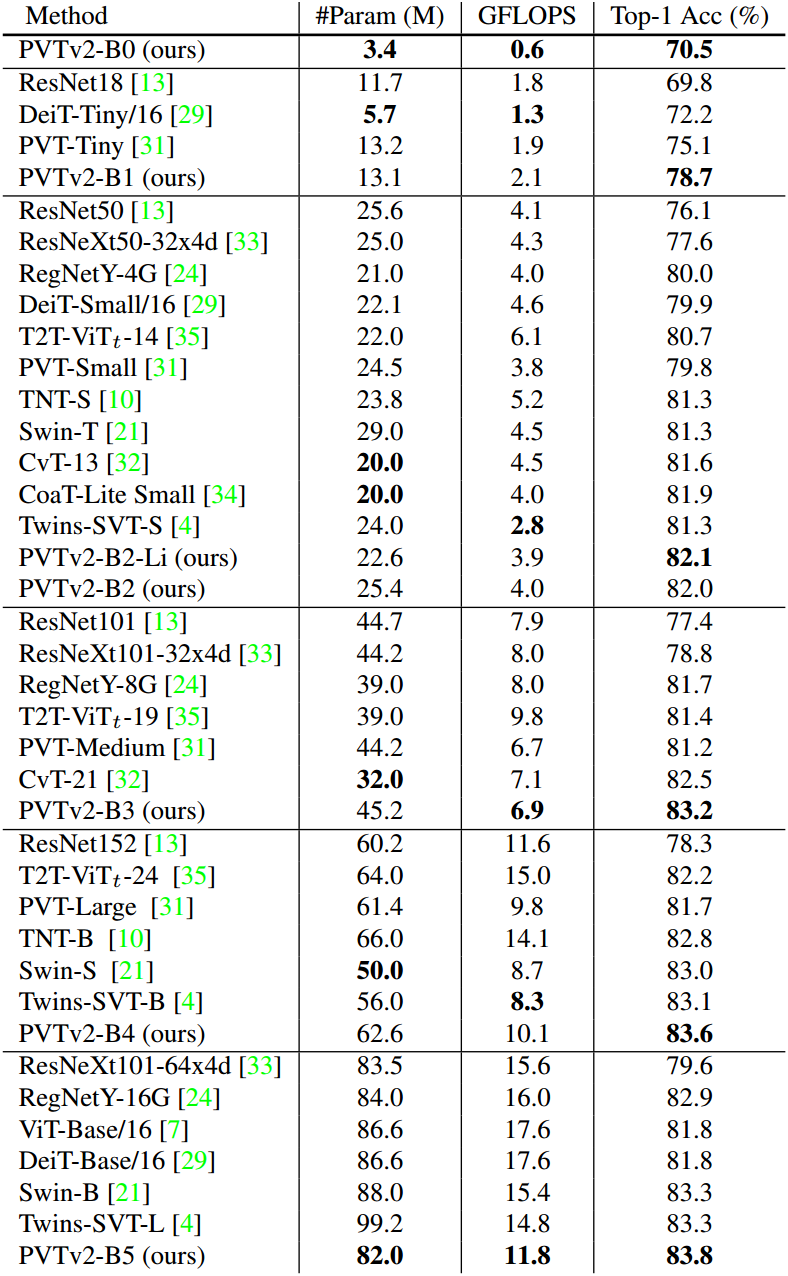
图像分类结果对比
在实验中 PVTv2 是性能最优异的模型,虽然计算和参数与 PVT 相似但精度得到了大幅提升;与一些最新的模型相比,PVTv2 系列在模型精度和参数效率上有很大的优势,例如与 Swin Transformer 相比 PVTv2-B5 在较小的参数和操作数量下实现了更高的Top-1分类精度。
在目标检测任务中,研究人员在 COCO 数据集上进行了训练和测试,并与多个先进的目标检测主流模型进行了比较。同样 PVTv2 超过了 PVT 的结果,不同规模的模型在同量级的比较下都具有显著的优势。
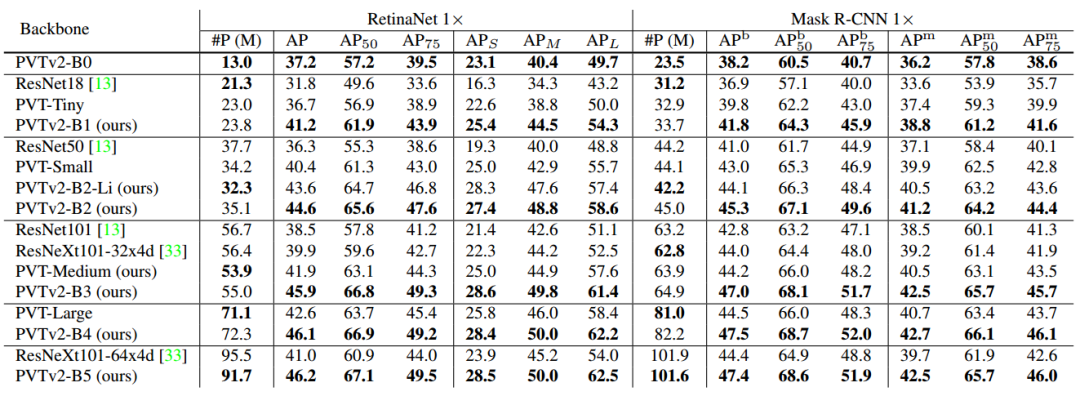
目标检测结果对比
下表还展示了与 Swin Transformer 的对比,将主干网络和检测头分别进行组合比较,结果表明 PVTv2 具有显著性能提升:
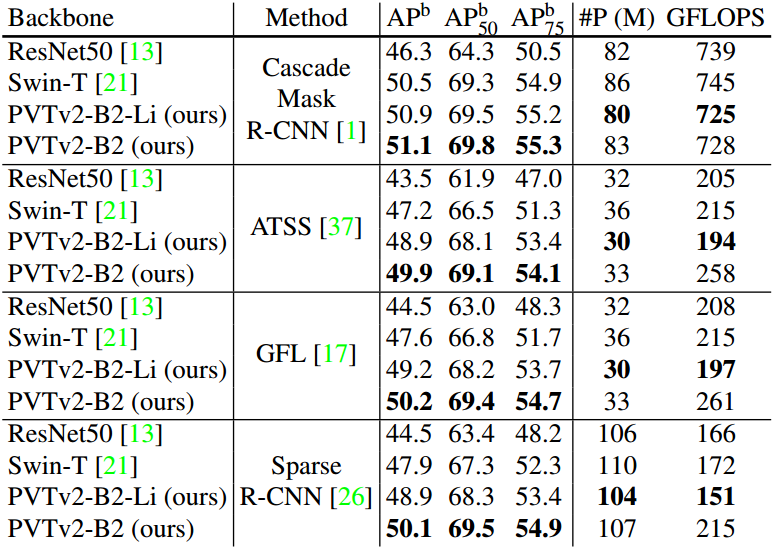
PVT2与Swin Transformer在主干网络和不同检测头上的性能对比。
PVTv2:https://arxiv.org/pdf/2106.13797v2.pdf
PVT(好学的你一定想复习一下):
PVT:金字塔架构的视觉Transformer,助力稠密视觉任务的高效实现
https://arxiv.org/pdf/2102.12122.pdf
代码上手尝试和学习,也提供了预训练权重:
https://github.com/whai362/PVT
From: arxiv 编译: T.R.

本周上新!



