CVPR Waymo Open Dataset挑战赛“冠军方案”:清华叉院DenseTNT详文解析!

Waymo Open Dataset是Waymo推出的用于自动驾驶的公开数据集,其中轨迹预测挑战赛是CVPR 2021的挑战赛之一,吸引了计算机视觉和自动驾驶方向的众多参与者。本文介绍了清华大学交叉信息院MARS Lab在这项挑战赛中取得冠军表现的解决方案。
博士预研生辜俊儒,实习生孙桥,指导老师赵行教授
论文地址:
https://arxiv.org/abs/2106.14160


由于人类行为的高度不确定性和多模态性,轨迹预测是自动驾驶中非常具有挑战性的任务。为了能够对这种高度的不确定性进行建模,最近研究者们提出了基于终点的方法,即先预测轨迹的终点,再补充完整个轨迹(TNT:Target-driveN Trajectory Prediction, Zhao et al. CoRL 2020)。这样做的原因在于轨迹的高度不确定性大部分体现在轨迹的终点上,如果确定了轨迹的终点,那么整条轨迹就能够较为容易地求出来。这些方法需要事先定义一些稀疏的anchor,每个 anchor 会通过回归得到对应的一个终点,如下图左边所示。有的方法在道路的中心线上采样一些点作为 anchor,有的方法则将道路的每个片段作为一个anchor。

二、本文方法
在这次挑战赛中,我们提出了 DenseTNT,一个 anchor-free 的基于终点的轨迹预测方法,能够有效提升终点预测的效果,不需要依赖事先定义的anchor的质量。我们首先从向量化的地图和 Agent 中抽取特征,然后对路面上的所有位置进行密集概率估计来生成候选终点的概率分布热力图,最终使用轨迹补全模块基于终点来补全整个轨迹。
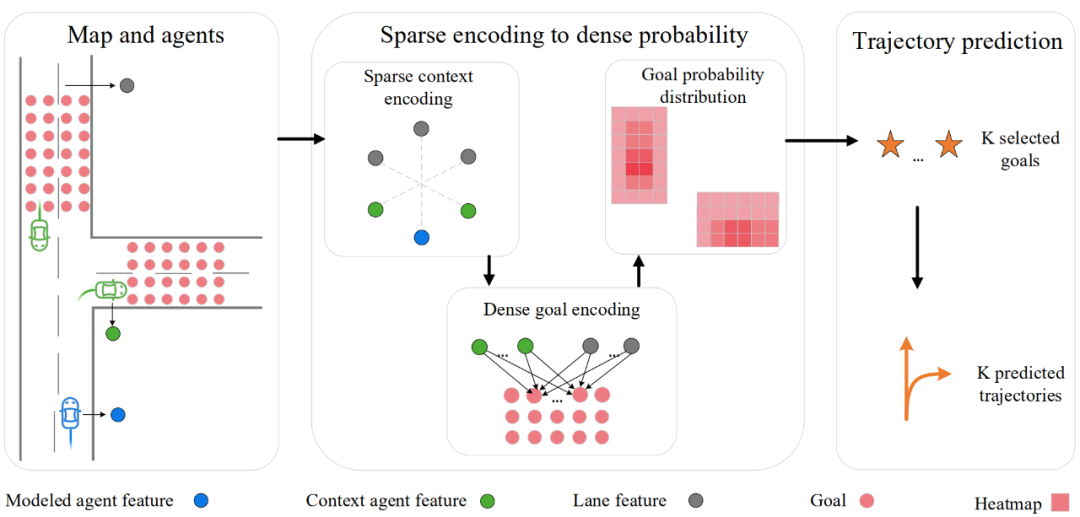
场景编码:对场景进行编码是预测的第一步。我们使用 VectorNet 进行对地图和Agent 进行编码,VectorNet 采用向量化的方式进行编码,而不是将地图和 Agent 渲染到图片上然后使用卷积进行特征抽取。通过对场景进行编码,我们得到了每条道路和每个 Agent 的特征。
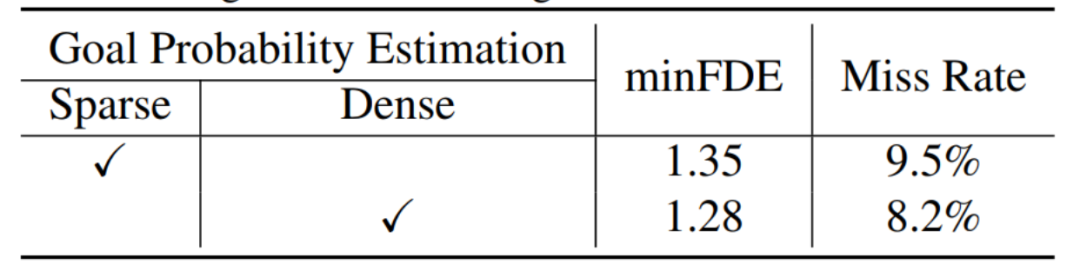
密集概率估计:对场景编码之后,我们进行密集概率估计。密集概率估计首先计算密集地分布在道路上的所有候选终点的特征,候选终点的采样间隔为1m。我们使用注意力机制计算候选终点的特征,从而抽取候选终点的局部信息,例如该终点和道路边界之间的距离。最终我们对每个候选终点的特征进行解码,得到候选终点的概率分布。
终点选择:我们使用NMS(非极大抑制)从密集终点中选择最终的K个终点。NMS每次选择当前剩余的候选终点中概率最高的终点,然后将该终点周围一定范围内的候选终点删去,如此重复,直到选出K个终点。
轨迹补全:最后一步,我们基于每个终点补全整个轨迹。训练时,将轨迹的真实终点作为轨迹补全模块的输入,用真实的完整轨迹来监督轨迹补全模块的训练。
三、实验结果
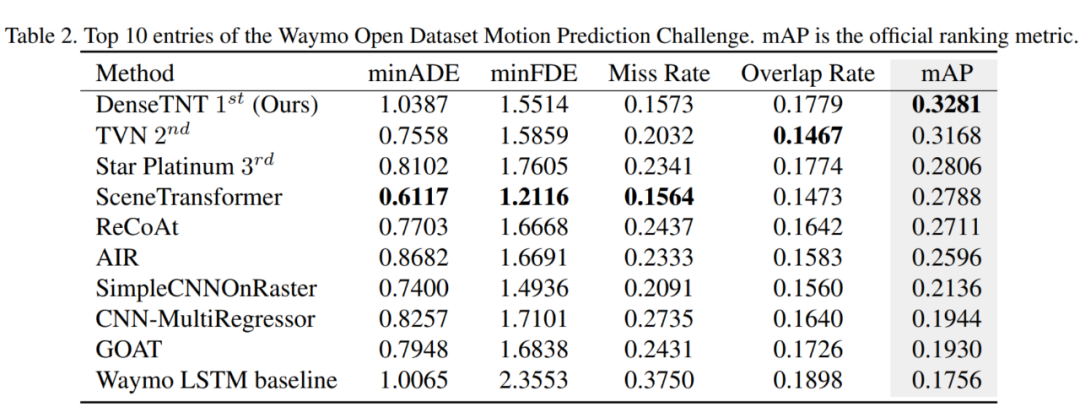
Waymo Open Dataset轨迹预测挑战赛:我们的DenseTNT在Waymo Open Dataset上取得了第一名的成绩,如下表所示。其中mAP是官方的排名指标,能够更加全面地刻画轨迹预测模型的性能。
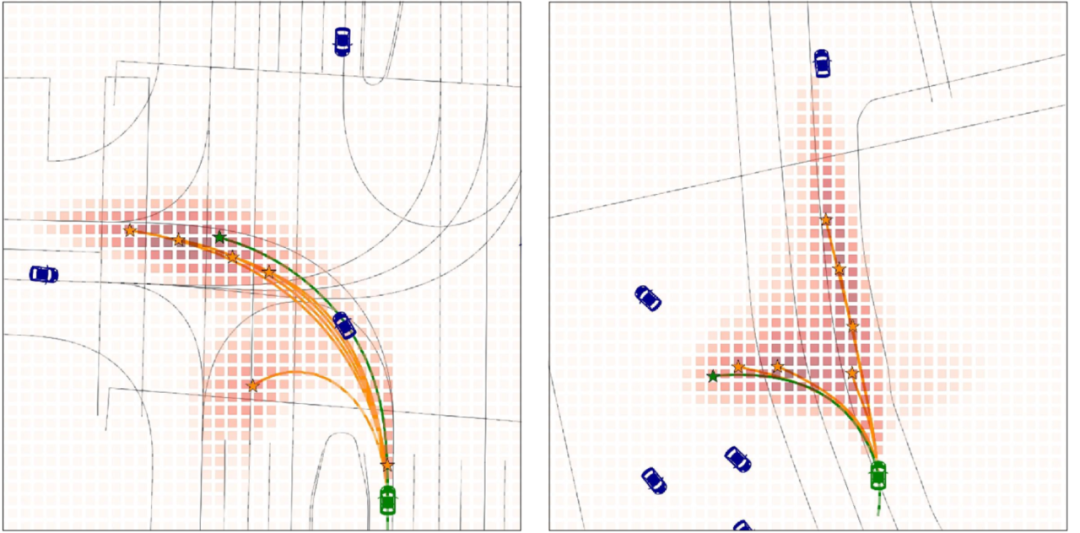
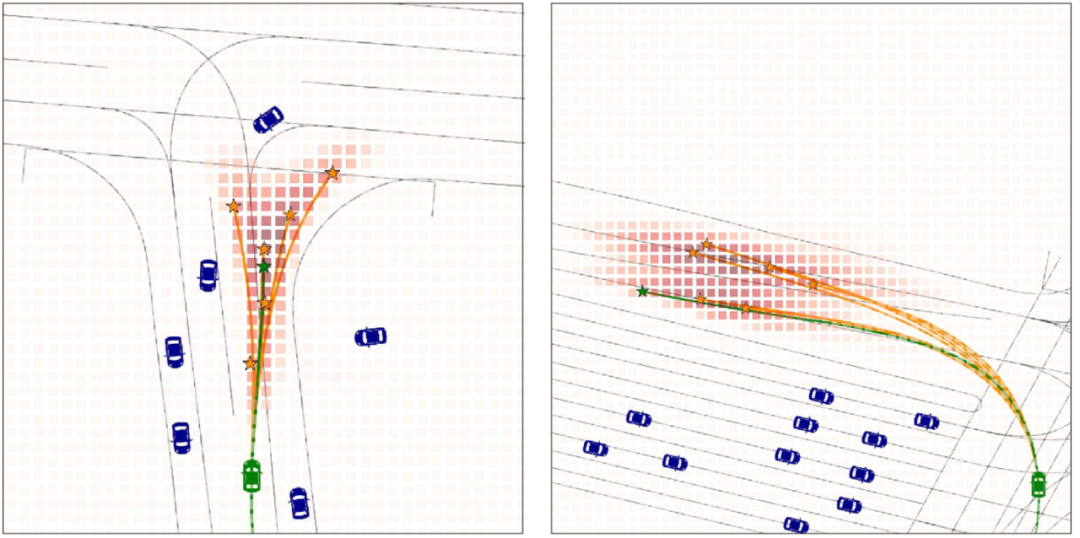
可视化结果:下图是我们的模型在Waymo Open Dataset轨迹预测任务中的可视化结果,密集终点的概率被标注为红色,预测的K个终点和相应的轨迹被标注为橙色,真实的轨迹被标注为绿色。
四、总结
在本文中,我们提出了一个 Anchor-free 的轨迹预测模型 DenseTNT。我们的模型超越了之前基于终点的轨迹预测方法,模型的性能不需要依赖事先定义的 anchor 的质量。DenseTNT 在 Waymo Open Dataset 轨迹预测挑战赛中取得了第一名的成绩。
团队介绍
MARS Lab
清华大学交叉信息院 MARS Lab 多模态学习实验室,由助理教授赵行组建。(戳这里阅读赵行教授专访)目前主要研究的问题是多模态学习和自动驾驶。像人类探索火星,赵行希望自己的实验室不被研究领域所定义,永远在寻找新的问题,同时希望实验室的每一位成员能够始终走在探索的最前列,喜欢研究。实验室感兴趣的问题包括但不限于:

本周上新!



