ICML 2021 | Self-Tuning: 如何减少对标记数据的需求?
以下文章来源于THUML ,作者王希梅
清华大学软件学院机器学习实验室,专注于迁移学习、深度学习、科学学习等基础理论方法及在人工智能和工业数据软件中的应用研究,负责人为王建民教授和龙明盛副教授,顾问为Michael I. Jordan院士。

作者:
王希梅,高敬涵,龙明盛,王建民
论文链接:
http://ise.thss.tsinghua.edu.cn/~mlong/doc/Self-Tuning-for-Data-Efficient-Deep-Learning-icml21.pdf
GitHub项目页面:
https://github.com/thuml/Self-Tuning

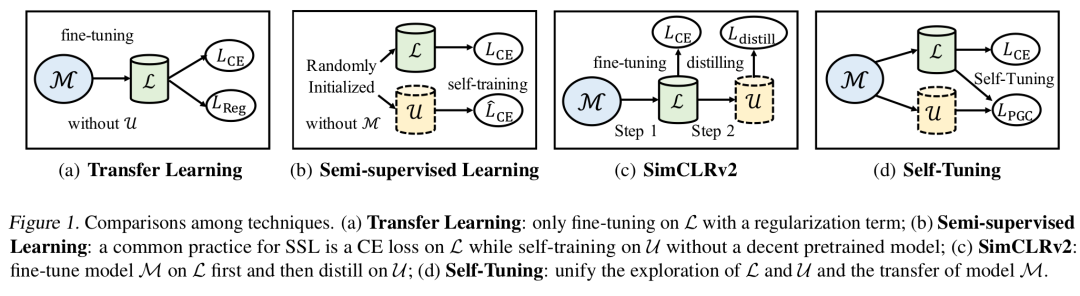
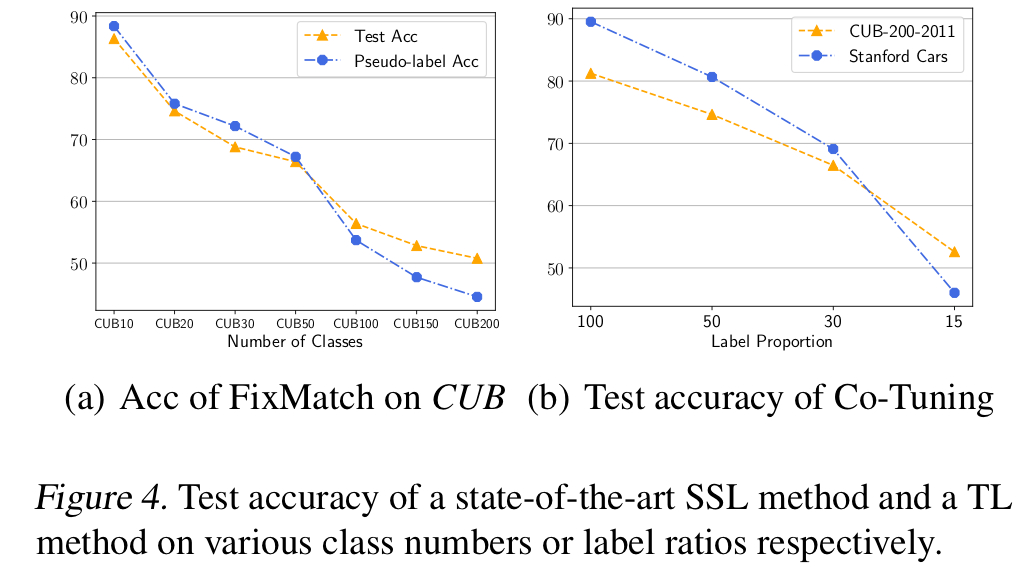
半监督学习的最新进展,例如UDA,FixMatch等方法,证明了自训练(Self-Training)的巨大潜力。通过弱增广样本为强增广样本生成伪标记(pseudo-label),FixMatch就可以在Cifar10、SVHN、STL-10数据集上取得了令人耳目一新的效果。然而,细心的读者会发现,上述数据集都是类别数较少的简单数据集(都是10类),当类别数增加到100时,FixMatch这种从头开始训练(train from scratch)的自训练方法的表现就差强人意了。进一步地,我们在CUB200上将类别数从10逐渐增加到200时,发现FixMatch的准确率随着伪标签的准确率的下降而快速下降。这说明,随着类别数的增加,伪标签的质量逐渐下降,而自训练的模型也被错误的伪标签所误导,从而难以在测试数据集上取得可观的效果。这一现象,被前人总结为自训练的确认偏差(Confirmation Bias)问题,说明Self-training虽然是良药,偶尔却有毒。
迁移学习在计算机视觉和自然语言处理中被广泛使用,预训练-微调(fine-tuning)的范式也比传统的领域适应(domain adaptation)约束更少,更具落地价值。然而,现有的迁移学习方法专注于从不同角度挖掘预训练模型和标记数据,却对更为容易获取的无标记数据熟视无睹。以迁移学习的最新方法Co-Tuning为例,它通过学习源领域类别和目标领域类别的映射关系,实现了预训练模型参数的完全迁移。然而,因为仅仅将预训练模型迁移到标记数据中,Co-Tuning容易过拟合到有限的标记数据上,测试准确率随着标记数据比例的减少而迅速下降,我们将这一现象总结为模型漂移(model shift)问题。
二、如何解决确认偏差问题?
为了找出自训练的确认偏差(confirmation bias)问题的根源,我们首先分析了伪标签(pseudo-label)广泛采用的交叉熵损失函数(Cross-Entropy, CE):
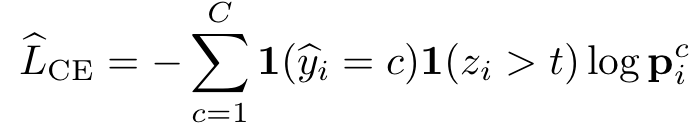
 是输入
是输入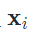 生成的伪标签, 而
生成的伪标签, 而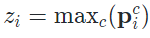 是模型对于样本
是模型对于样本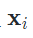 的信心(confidence)。通常地,大多数自训练方法都会针对confidence做一个阈值过滤,只有大于阈值
的信心(confidence)。通常地,大多数自训练方法都会针对confidence做一个阈值过滤,只有大于阈值 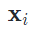 在不同数据增广下生成的副本k0,以及D个不同输入生成的负样本
在不同数据增广下生成的副本k0,以及D个不同输入生成的负样本 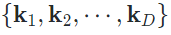 ,则通过内积度量相似性的对比学习(Constrastive Learning, CL)损失函数可以定义为
,则通过内积度量相似性的对比学习(Constrastive Learning, CL)损失函数可以定义为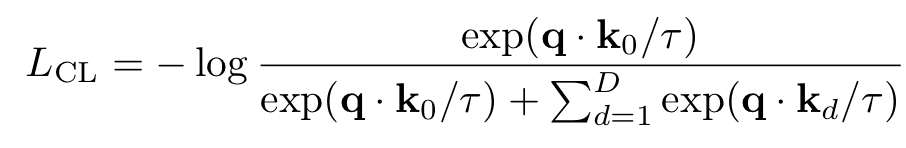
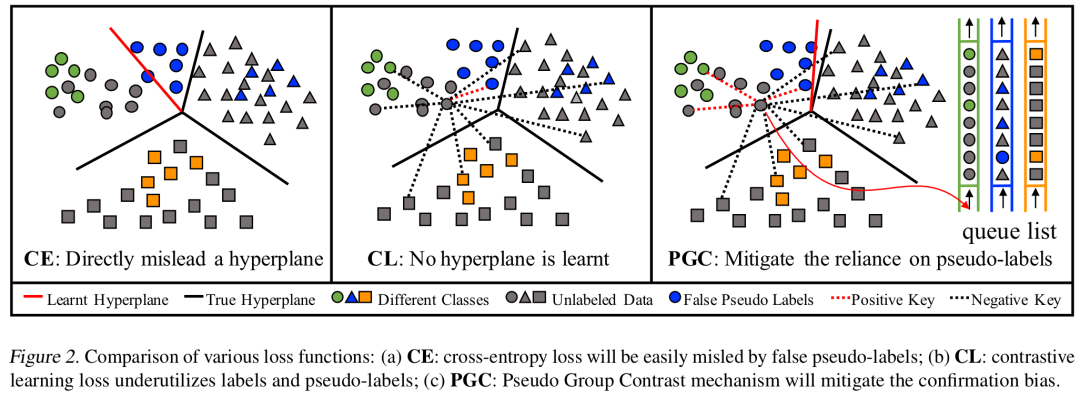
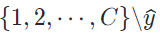 )的样本则组成了负样本,从而最大化查询样本与具有相同伪标签的正样本的表征相似性,实现伪标签的组对比。
)的样本则组成了负样本,从而最大化查询样本与具有相同伪标签的正样本的表征相似性,实现伪标签的组对比。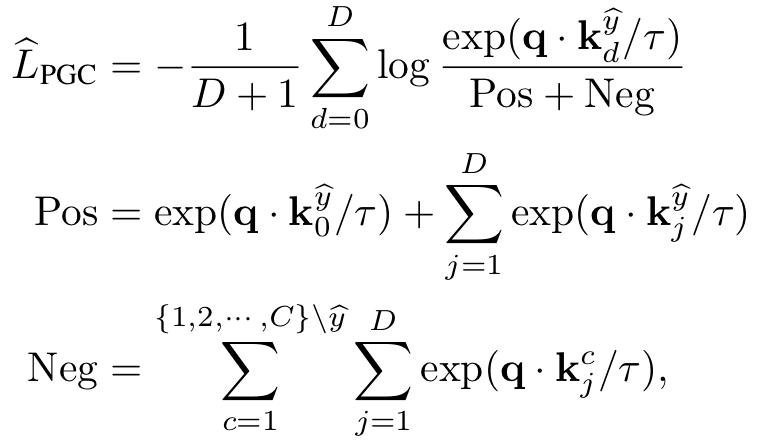
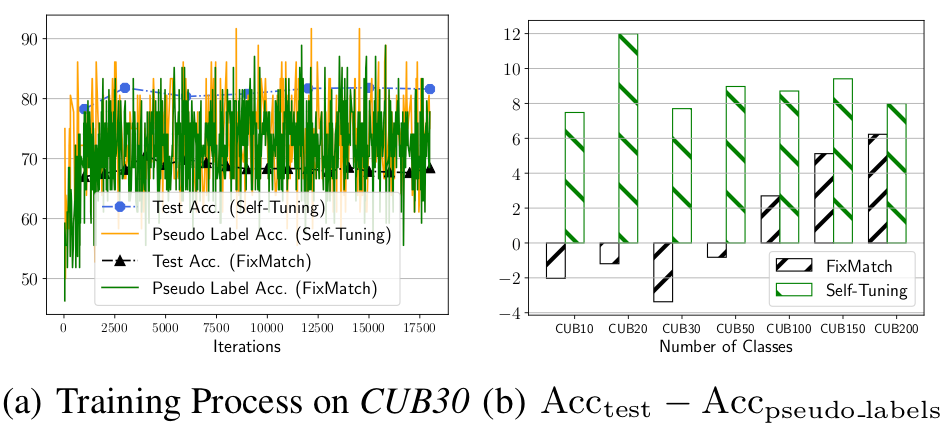
1. 在模型训练伊始,Self-Tuning和FixMatch具有相似的伪标签准确率,但是随着模型逐渐趋于收敛,Self-Tuning的测试集准确率明显高于FixMatch。
2. 在具有不同类别数的CUB数据集上,Self-Tuning的测试准确率始终高于伪标签准确率,而FixMatch的测试准确率被伪标签准确率给限制住了。
三、如何解决模型漂移问题?
如前所述,当我们只在有限的标记数据集上微调预训练模型时,模型漂移问题往往难以避免。为了解决这个问题,近期发表的一篇名为SimCLRv2的论文提出可以综合利用预训练模型、标记数据和无标记数据的信息。他们给出了一个有趣的解决方案:首先在标记数据集(L)上微调预训练模型(M),继而在无标记数据集(U上进行知识蒸馏。然而,通过这一从 M 到 L 再到 U 的“序列化”方式,微调后的模型依然倾向于向有限的标记数据偏移。我们认为,应该将标记和未标记数据的探索与预训练模型的迁移统一起来。
与SimCLRv2的“序列化”方式不同,我们提出了一种“一体化”的形式来解决模型漂移问题。首先,与半监督学习从零开始训练模型的通用实践不同,Self-Tuning的模型起点是一个相对准确的大规模预训练模型,通过更准确的初始化模型来提供一个更好的隐式正则。同时,预训练模型的知识将并行地流入标记数据和无标记数据中,标记数据和无标记数据产生的梯度也会同时更新模型参数。这种“一体化”的形式有利于同时探索标记数据的判别信息和无标记数的内在结构,大大缓解模型漂移的挑战。
另一方面,在对比学习中,负样本的规模越大,模型的效果往往越好。与MoCo类似,我们也通过引入队列的方式将负样本规模与批量大小(batch-size)解耦,使得负样本规模可以远大于批量大小。另一方面,队列的方式可以保证每次对比时,每个伪类下的负样本数目恒定,不受每个minibatch随机采样的影响。与标准的对比学习不同的是,由于伪标签的引入,PGC需要维护C个队列,其中C是类别数。在每次模型迭代中,对于无标记样本,将根据他们的伪标签渐进地替换对应队列里面最早的样本。而对于标记数据,因为他们天然地拥有准确的标签,则可以根据他们的标签来更新对应的队列。值得注意的是,我们在标记数据和无标记数据间共享了这些队列。这一设计的好处在于:将标记数据中宝贵的准确标签嵌入到共享队列中,从而提高了无标记数据的候选样本的伪标签准确性。
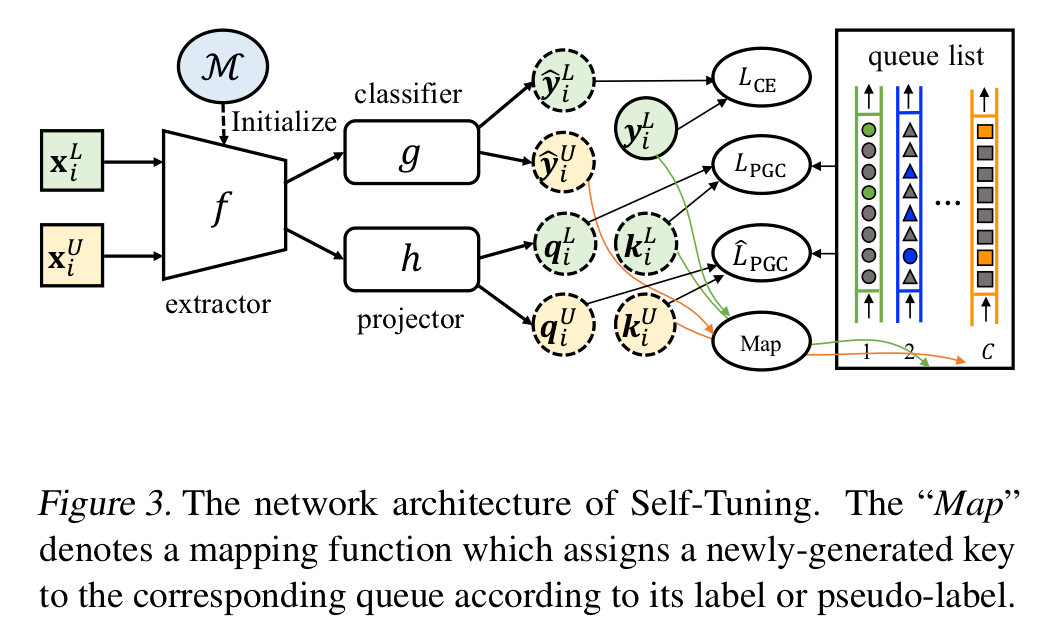
在实验部分,我们在5种数据集、3种标记数据比例和4种预训练模型下,测试了Self-Tuning的效果,同时与5种主流迁移学习方法、6种主流半监督学习方法以及他们的至强组合进行了充分的对比。
迁移学习的Benchmark
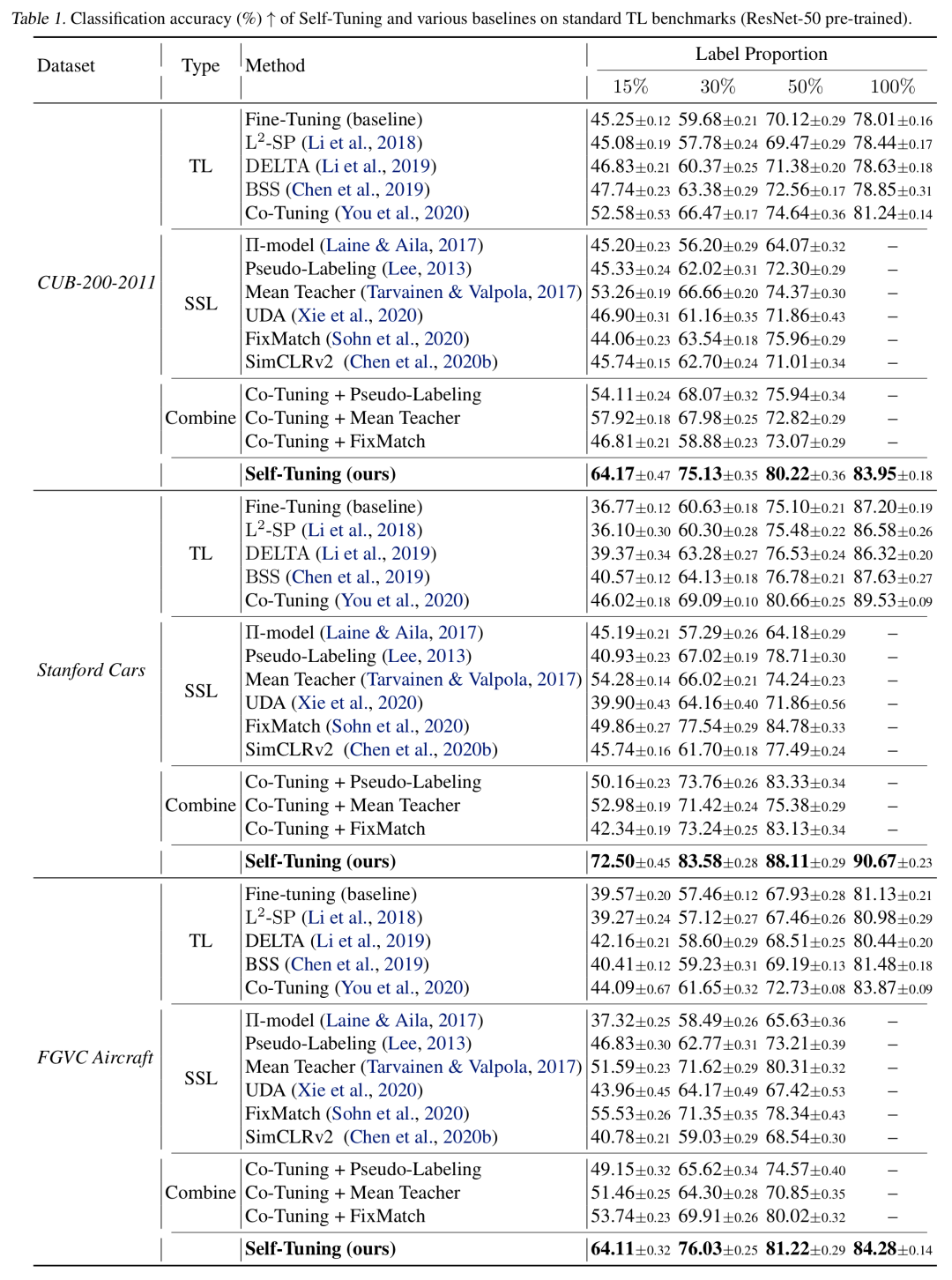
我们首先在迁移学习的常用数据集CUB-200-2011, Stanford Cas和FGVC Aircraft下进行实验,将标记数据的比例依次设置为15%,30%和50%,采用ResNet-50作为预训练模型。结果显示,Self-Tuning大幅领先于现有方法,例如,在标签比例为15%的Stanford-Cars数据集上,Self-Tuning的测试精度比fine-tuning几乎提高了一倍。
半监督学习的Benchmark
在半监督学习的主流数据集CIFAR-100、CIFAR-10、SVHN和STL-10中,我们采用了类别数最多、最困难的CIFAR-100数据集。由于在ImageNet上预训练的WRN-28-8模型尚未公开,我们采用了参数少得多的EfficientNet-B2模型。实验结果表明,预训练模型的引入对于半监督学习有如虎添翼的效果。同时,由于采用了对伪标签依赖更小的PGC损失函数,Self-Tuning充分挖掘了预训练模型、标记数据和无标记数据的所有信息,在各种实验设定下均取得了state-of-the-art的测试准确率。
无监督预训练模型
为了证明Self-Tuning可以拓展到无监督预训练模型中,我们做了MoCov2迁移到CUB-200的实验。无论是每类4个样本还是每类25个样本的实验设定,Self-Tuning相较于迁移学习和半监督学习的方法都有明显提升。
命名实体识别
为了证明Self-Tuning可以拓展到自然语言处理(NLP)的任务中,我们在一个英语命名实体识别数据集CoNLL 2003上进行了实验。按照Co-Tuning的实验设定,我们采用掩蔽语言建模的BERT作为预训练模型。以命名实体的F1得分作为度量指标的话,fine-tuning的F1得分为90.81,BSS、L2-SP和Co-Tuning分别达到90.85、91.02和91.27,而Self-Tuning取得了明显更高的94.53的F1得分,初步证明了Self-Tuning在NLP领域的强大潜力。更加详尽的NLP实验,会在未来的期刊版本中进行拓展。
消融实验
在深度学习社区中,如何减少对标记数据的需求是一个至关重要的问题。考虑到迁移学习和半监督学习的普通实践中只关注预训练模型或无标记数据的不足,本文提出了一种新的数据高效的深度学习机制,可以充分发挥预训练模型和无标记数据的优势。这一机制可能是迁移学习在工业界最为现实的落地场景,值得我们继续大力研究。另一方面,我们提出的Self-Tuning方法简单通用,是迁移学习、半监督学习和对比学习等领域的核心思想的集大成者,可以提高对伪标签的容忍度。对于其他需要用到伪标签的场景,应该也有一定的借鉴价值。
欢迎感兴趣的朋友阅读我们的论文或者访问GitHub项目页面查看更多细节内容。
ICML直播研讨会报名传送门

ICML 2021 征稿啦!
想让你的工作获得更多关注?
想与更多大佬进行学术交流?
想宣传你主办的challenges或者workshop?
一键获取投稿方式!

扫码观看!
本周上新!

关于我“门”
