本文主要介绍由Oulu大学主导的几个差分卷积(Difference Convolution)工作及其在图像、视频领域中的应用。 相关工作已被 TPAMI, TIP, CVPR’20, ICCV’21 (Oral), IJCAI’21 等顶级期刊会议接收,并斩获两项国际大赛冠亚军(1st Place in the ChaLearn multi-modal face anti-spoofing attack detection challenge with CVPR 2020 [16] 和 2nd Place on Action Recognition Track of ECCV 2020 VIPriors Challenges [17])。一、鼻祖LBP的简单回顾
[1] Timo Ojala, et al. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. TPAMI 2002.[2] Zitong Yu, et al. Searching central difference convolutional networks for face anti-spoofing. CVPR 2020.[3] Zitong Yu, et al. Nas-fas: Static-dynamic central difference network search for face anti-spoofing. TPAMI 2020.[4] Juefei Xu, et al. Local binary convolutional neural networks. CVPR 2017.[5] Shangzhen Luan, et al. Gabor convolutional networks. TIP 2018.[6] Ramachandran Prajit, et al. Stand-alone self-attention in vision models. NeurIPS 2019.[7] Zitong Yu, et al. Dual-Cross Central Difference Network for Face Anti-Spoofing. IJCAI 2021.[8] Zhuo Su, et al. Pixel Difference Networks for Efficient Edge Detection. ICCV 2021 (Oral)[9] Li Liu, et al. Extended local binary patterns for texture classification. Image and Vision Computing 2012.[10] Zitong Yu, et al. Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition. TIP 2021.[11] Shuyang Sun, et al. Optical flow guided feature: A fast and robust motion representation for video action recognition. CVPR 2018.[12] Myunggi Lee, et al. Motion feature network: Fixed motion filter for action recognition. ECCV 2018.[13] Klimack, Jason. A Study on Different Architectures on a 3D Garment Reconstruction Network. MS thesis. Universitat Politècnica de Catalunya, 2021.[14] Zabihi Samad, et al. A Compact Deep Architecture for Real-time Saliency Prediction. arXiv 2020.[15] Zhao Yu, et al. Video-Based Physiological Measurement Using 3D Central Difference Convolution Attention Network. IJCB 2021.[16] Zitong Yu, et al. Multi-modal face anti-spoofing based on central difference networks. CVPRW 2020.[17] Haoyu Chen, et al. 2nd place scheme on action recognition track of ECCV 2020 VIPriors challenges: An efficient optical flow stream guided framework. arXiv 2020.
Illustrastion by Julia Gnedinafrom Icons8-The End-


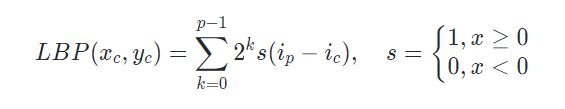
 图2. 人脸及其LBP图
图2. 人脸及其LBP图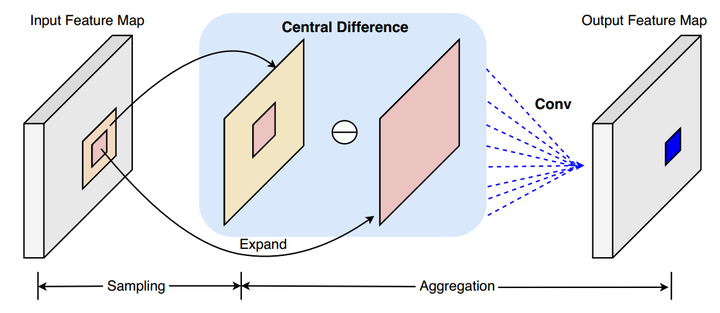
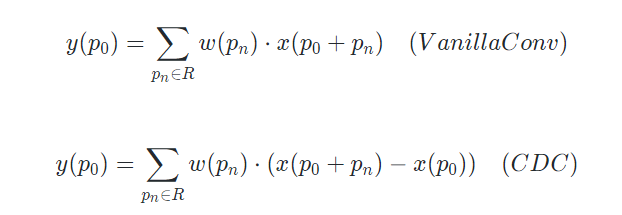
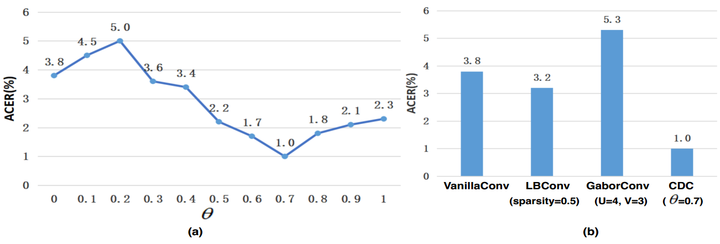

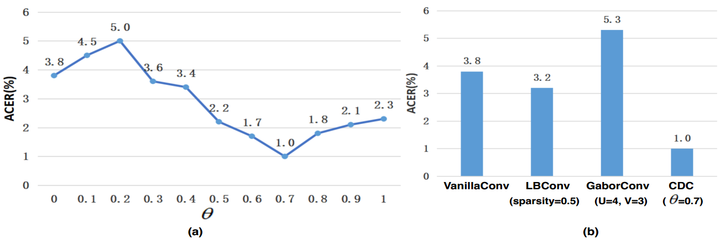
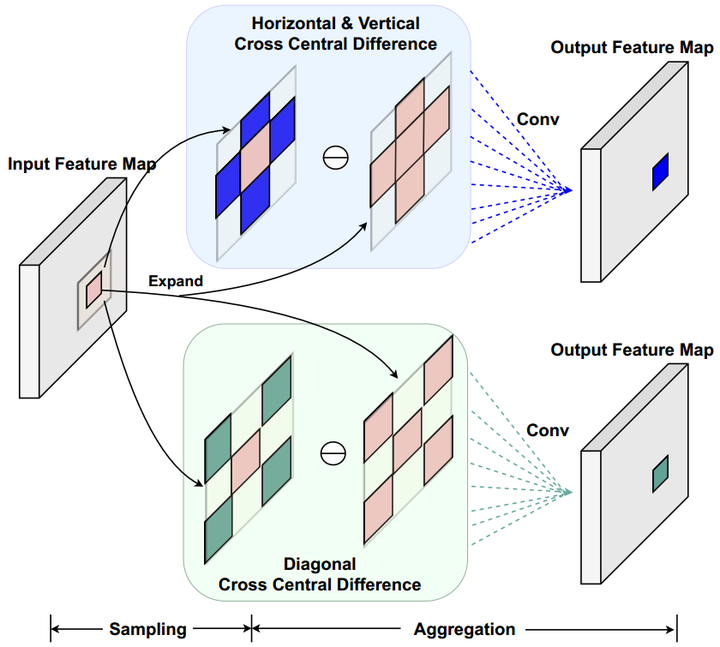
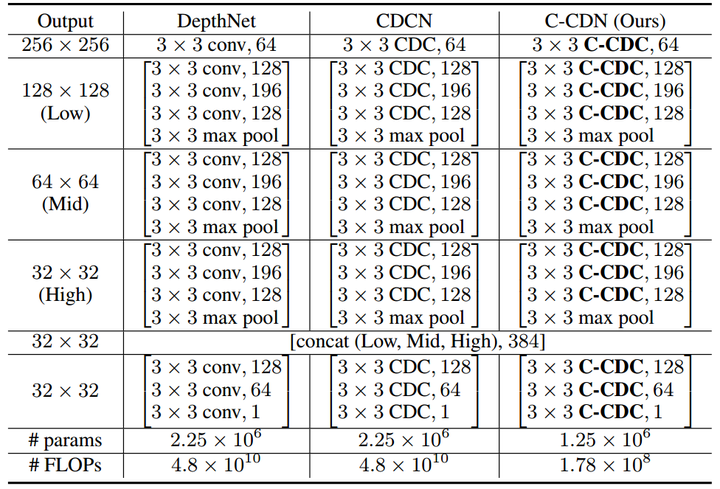
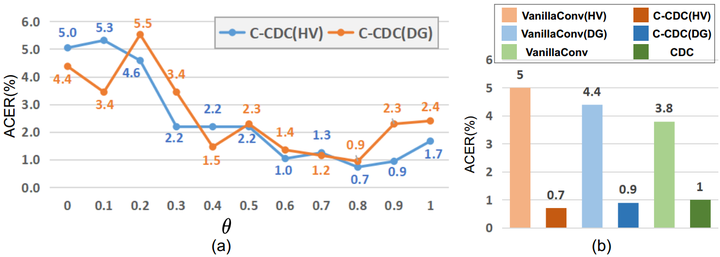
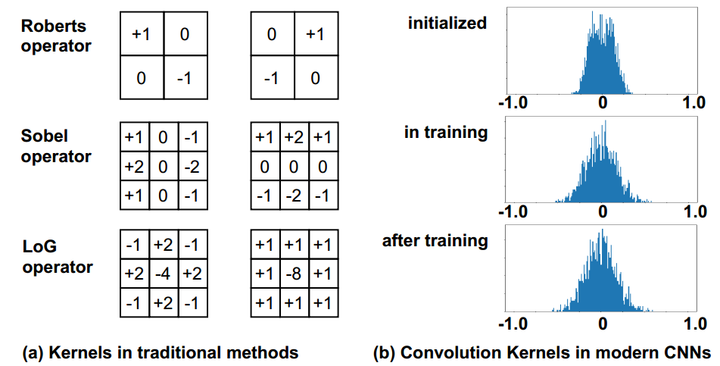
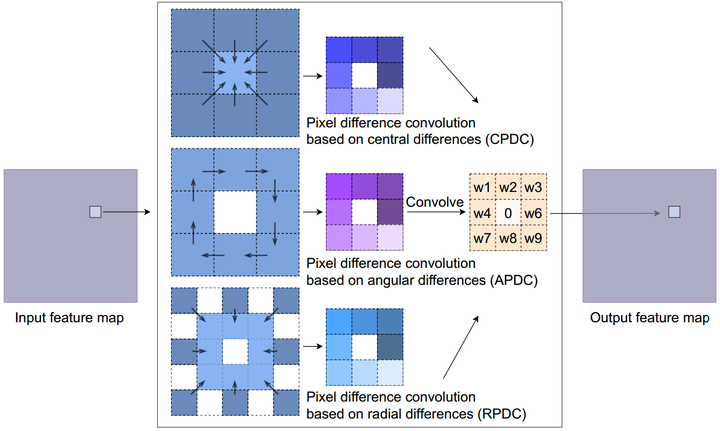
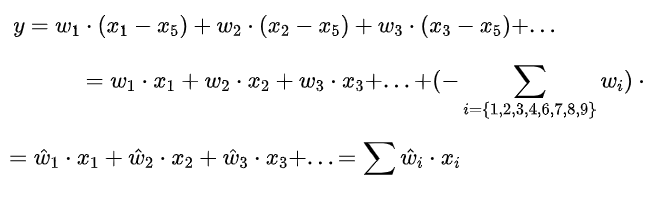
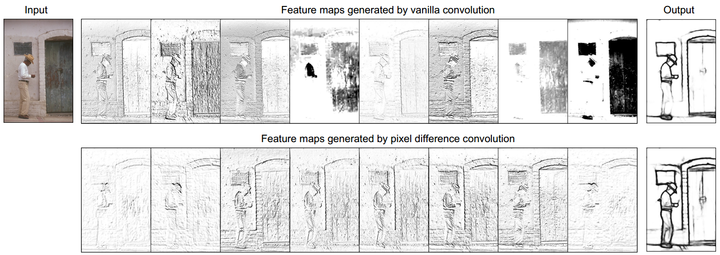
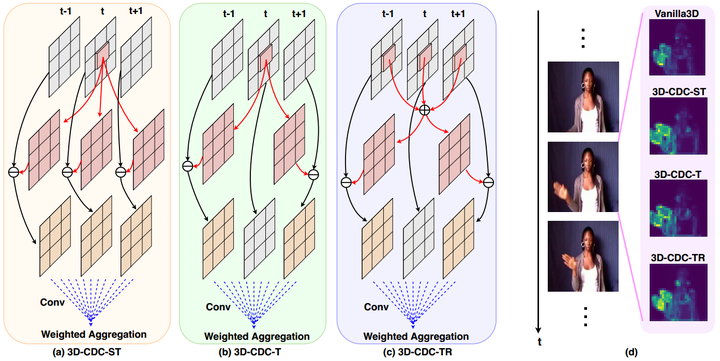

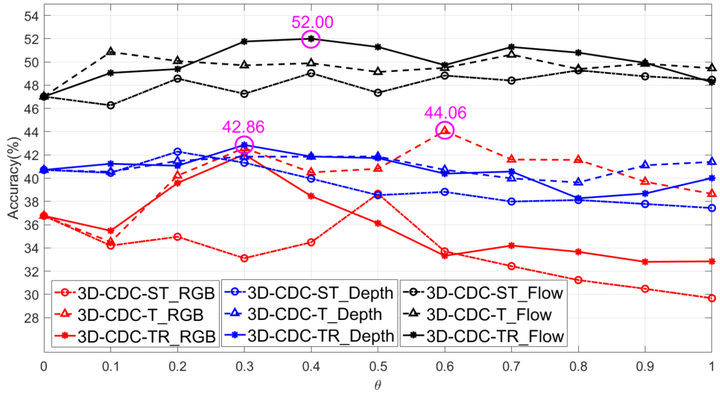 图11. Chalearn IsoGD上关于3D-CDC及超参theta值在三种模态上RGB、Depth、光流的实验。
图11. Chalearn IsoGD上关于3D-CDC及超参theta值在三种模态上RGB、Depth、光流的实验。