ACM MM 2021 | 基于图卷积网络的视频人物社交关系图生成方法
以下文章来源于USTC MINE ,作者USTC MINE
中国科学技术大学多模态智能与知识网络(Multimodal Intelligence & knowledge NEtwork)研究组,隶属于大数据分析与应用安徽省重点实验室(BDAA),专注社交媒体、商务智能与知识网络相关研究。
论文标题:
Linking the Characters: Video-oriented Social Graph Generation via Hierarchical-cumulative GCN
论文作者:
Shiwei Wu, Joya Chen, Tong Xu, Liyi Chen, Lingfei Wu, Yao Hu, Enhong Chen

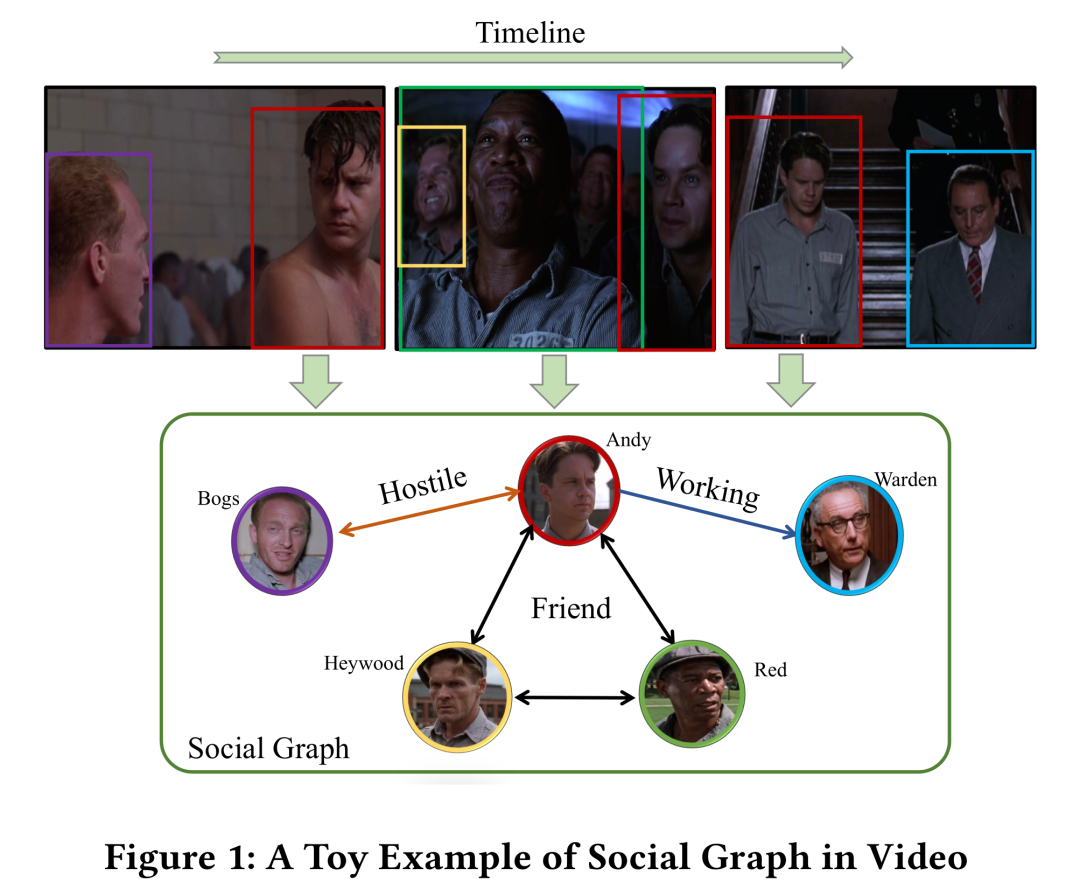
一、引言
2.1 问题描述
给定视频集
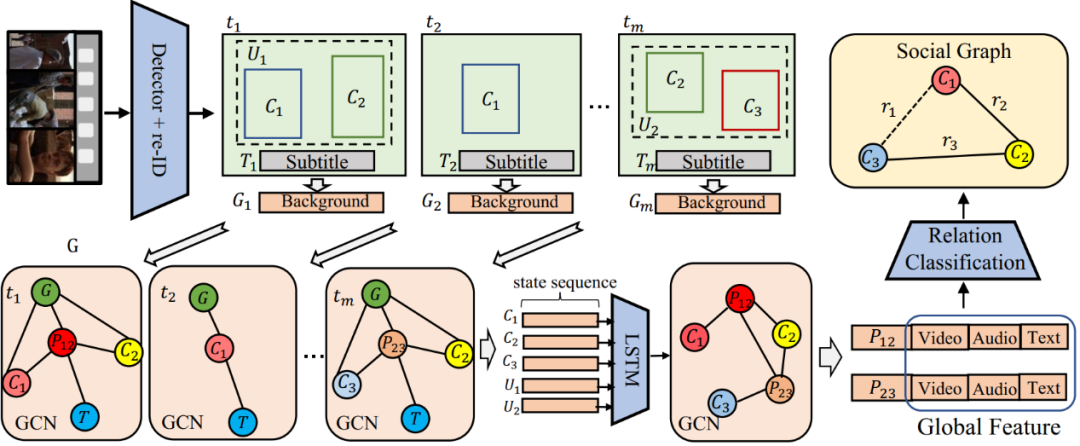 图2 模型整体框架
图2 模型整体框架我们提出的人物社交关系图生成模型主要包括:帧级别的图卷积网络模块、多通道时序累积模块以及片段级别的图卷积网络模块。
2.3 帧级别的图卷积网络模块
在帧级别的图卷积网络模块中,目标是生成一个帧级别的子图,用来提供当前帧的人物社交关系图。主要过程如下:
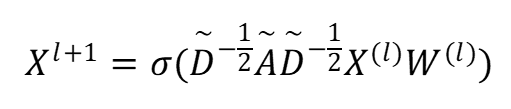 其中,
其中, 子图的邻接矩阵定义为:
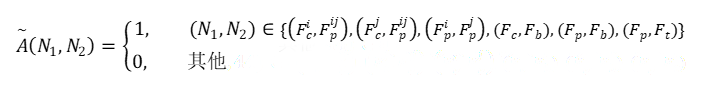 其中
其中 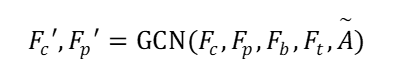
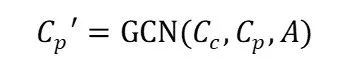
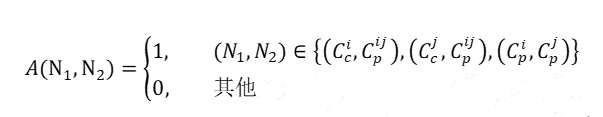 其中
其中 2.6 基于弱监督学习的训练和测试方案。
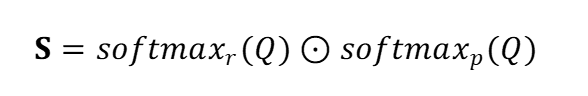 其中,
其中, 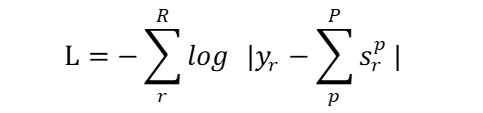 其中,
其中, 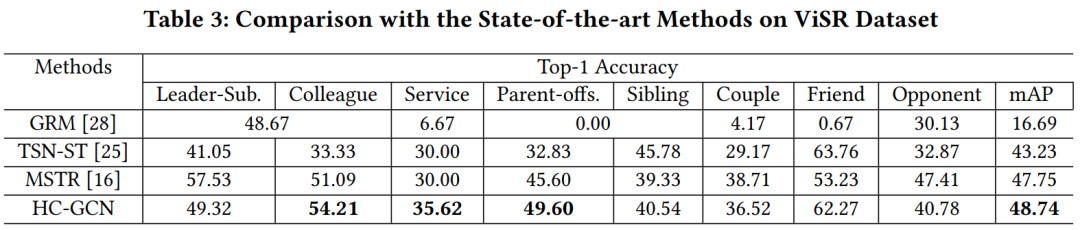
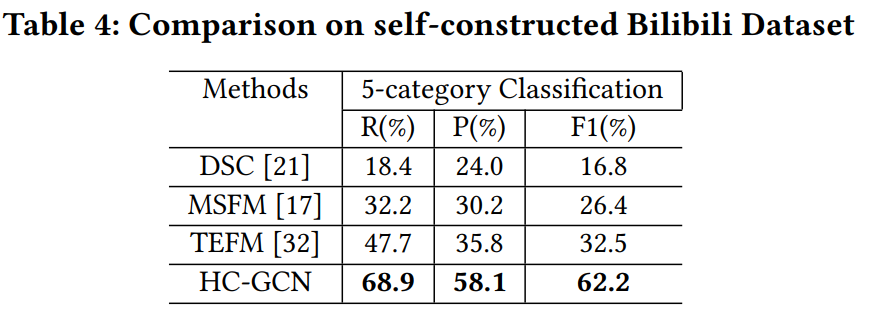
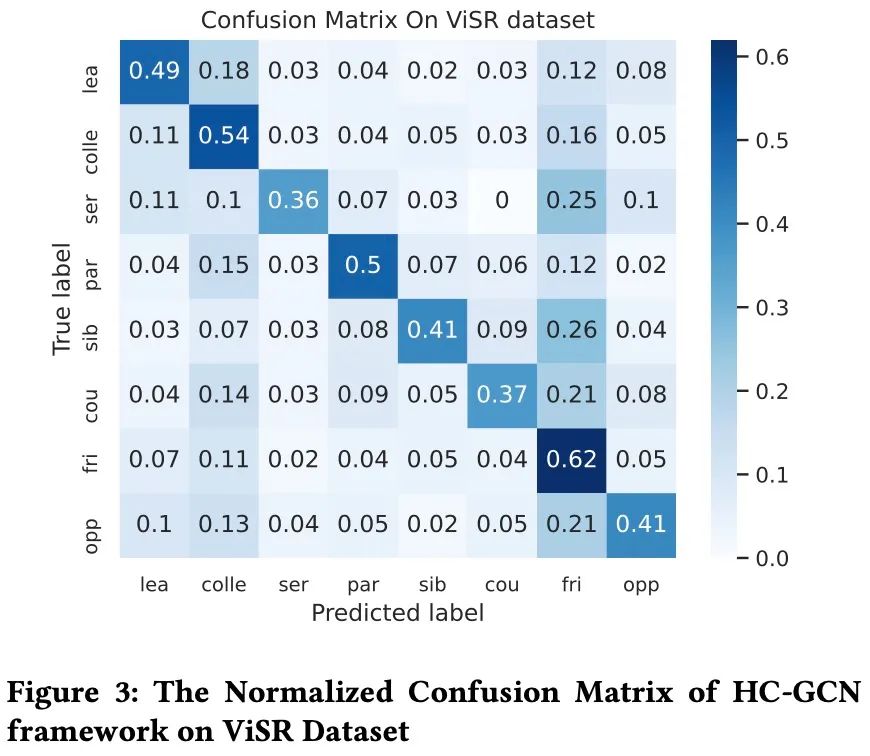
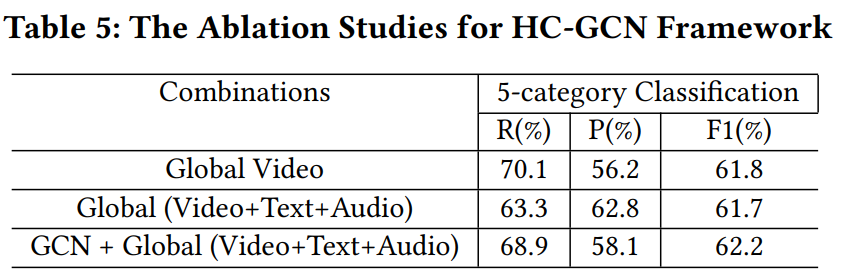
3.3 消融实验
-The End-
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>>> 投稿请添加工作人员微信!

扫码观看!
本周上新!

