Perceiver IO--适应多模态任务的高性能新架构

paper:
https://arxiv.org/pdf/2107.14795.pdf
code:
https://dpmd.ai/perceiver-code

一、多模态学习
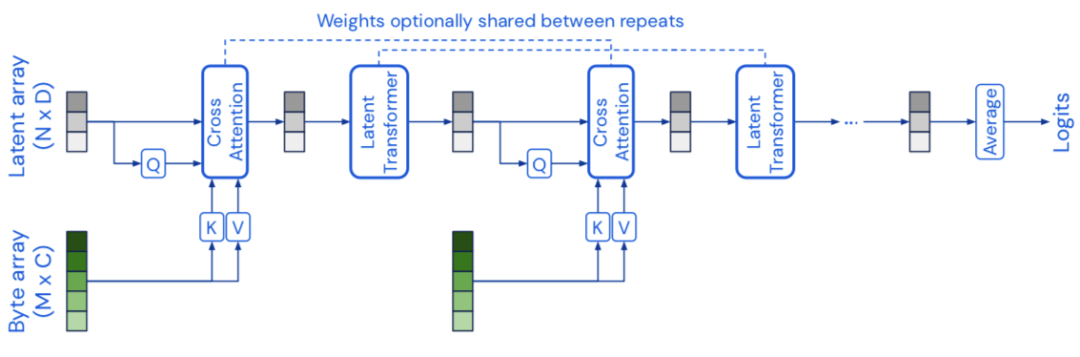 先前只能获取简单输出的Perceiver整体架构
先前只能获取简单输出的Perceiver整体架构但遗憾的是Perceiver只能输出简单的分类信息,无法适应真实世界中负责任务的输出需要。为了突破这一极限实现更通用的网络架构,在本文中提出了一种实现结构化输出的解码机制,从Perceiver的隐空间中直接解码出语言、光流场、音视频序列、符号序列等多模态信息,以灵活地适应新任务的需求。其中关键的思想在于利用与任务相关的特定查询向量与隐变量一起生成特定的输出。通过这样的方式,模型可以生成大量的任意形状与结构的输出,同时隐变量特征还能保持与特定任务无关的通用特性。
全新的Perceiver IO模型中利用了全注意力读入-处理-输出架构:输入被读入编码到隐空间中, 随后隐式表达被多层模型进一步优化处理,最终解码生成任务相关的输出结果。这一架构综合了transformer注意力机制抽取通用全局特征的能力以及编解码器架构的非线性映射能力,使其具备了解耦输入大小、模态与输出的能力,可对输入输出的空间或局域结构做出最小化假设。在Perceiver IO中使用了交叉注意力机制将隐变量映射到任意尺寸和模态输出上,基于查询机制可灵活地适应不同域上多任务语义输出需求。Perceiver IO直接代替各领域中使用的特定网络模型,同时提高原有分类任务上的性能。
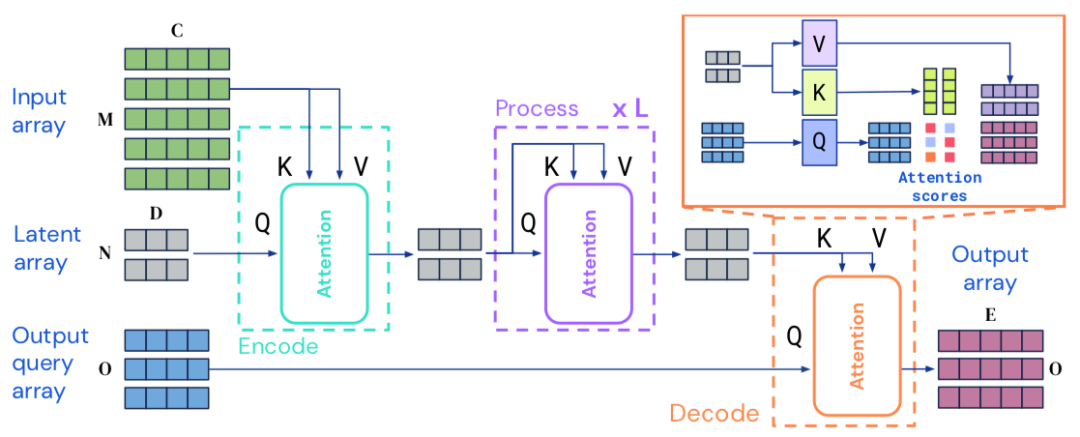
上图中显示了Perceiver IO的编码、处理和解码过程。首先,编码过程利用注意力模块将输入序列映射到了隐空间中;而后通过一系列模块对隐变量进行处理;最后利用注意力模块将处理后的隐变量进行解码,映射到输出特征上。输入输出对应的数据维度可以很大,而中间隐变量的维度则是可手工合理定义的超参数,其远小于输入输出维度使得计算开销保持线性。
与Perceiver相同,所以的模块都使用了与Transformer类似的全局QKV(query-key-value)机制和多层感知机进行后续处理。MLP在索引维度上独立地应用于每一个元素,编码器和解码器都包含了两个输入,一部分是模型的键、值网络的输入,另一部分是查询网络的输入。模型的输出具有与查询输入相同的索引维度(相同个数的元素),这使得编解码器可以生成不同尺度的输出。
另一方面Perceiver IO依赖于Transformer架构,但为什么transformer无法完成所需的目标呢?其主要原因在于transformer在计算和内存方面的开销巨大,它在所有层中均匀部署了注意力模块,整个输入需要在每一层都生成查询和键,这意味着每一层都需要平方计算复杂度使其难以在处理高维度数据的实际任务中大规模应用。甚至在transformer发迹的语言处理领域也需要复杂的预处理编码才能完成中长序列的建模任务。
但Perceiver IO使用了完全不同的非均匀注意力机制,首先将输入映射到隐空间,而后在隐空间中进一步处理,并最终映射到输出空间中去。这使得模型的计算量不再依赖于输入输出的维度,编码器、解码器和注意力模块只需要线性计算复杂度,同时隐空间中的注意力模块则独立于输入输出大小。Perceiver IO的结构优势大幅减小了计算开销,可以拓展到更大的输入和输出上去,将transformer能处理的典型序列长度从几千拓展到了几十万的量级。
编码器由单个注意力模块构成,通过学习获取与输入数据独立的查询向量,这也是的模块的计算复杂度与输入线性相关。处理部分由一系列堆叠注意力模块构成,可视为隐空间中的transformer。解码器部分则与编码器类似,在查询变量与KV的共同作用下将处理后的隐变量映射到输出空间中。这一结构可以处理任意形状和维度甚至不同模态的数据,但隐空间并没有显式地输入中的共享结构,因此需要利用交叉注意力来实现。
本研究的目标是利用给定大小的隐含表示生成最终任务所需的输出,可将相同维度的查询变量送入解码器。为了捕捉输出空间的结构查询向量需要包含适当的信息,这意味着查询向量需要反映下游任务需求,并捕捉输出中所需要的结构信息,包括图像中的空间位置或序列中输出词的位置信息。
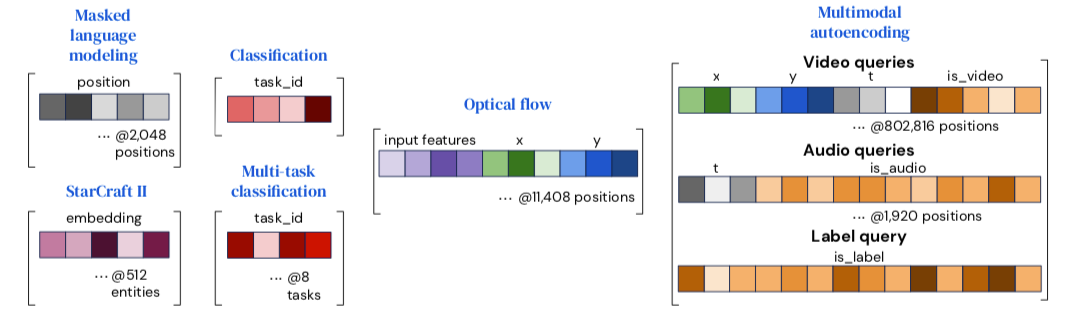
Perceiver IO使用特定输出相关的查询来生成不同语义的输出。对于像语言一类的同类型输出,其每个输出点只与其位置相关,可以使用位置编码来作为查询。对于目标输出的输入特征也可以与位置特征一起作为查询。对于多任务多模态输出来说,需要为每个模态或任务建立独立的查询。与某些查询相关的特征与多模态嵌入结合,并组合为目标输出所需的维度。
通过结合一系列相关的信息构建了查询向量,上图中显示了不同情况下的查询向量构建情况。对于像分类这类简单输出,查询从头开始学习获取并在每一个样本上复用。针对具有空间或序列结构的输出,需要将包含位置编码的包含到查询中去。对于多任务多模态输出,则需要针对每个特定任务或模态学习特定的查询,使得网络得以甄别任务或模态间的不同。对于其他任务而言,输出需要在查询位置反映出对应的输入内容。例如,光流估计任务在涵盖查询点的输入特征时性能更好;对于星际II则使用了单位信息将模型输出与对应单位练习起来。总的来说,实验表面非常简单的特征也可获得较好的输出结果,这意味着隐式注意力处理可以学习到用易于查询的方式组织与对应输出相关信息。

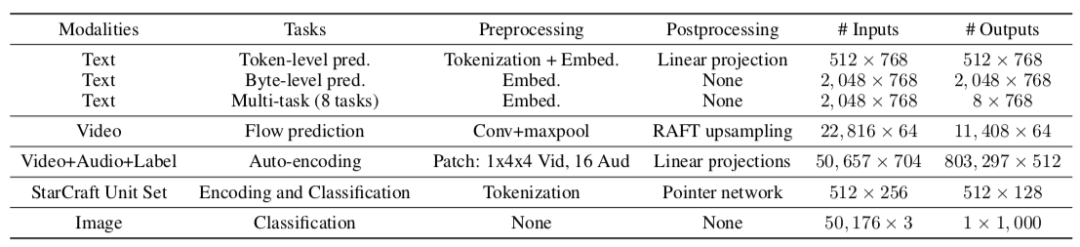
首先研究人员验证了模型在GLUE上的性能,Perceiver IO实现了与BERT等模型可媲美的优势,同时还克服了对序列长度的限制。
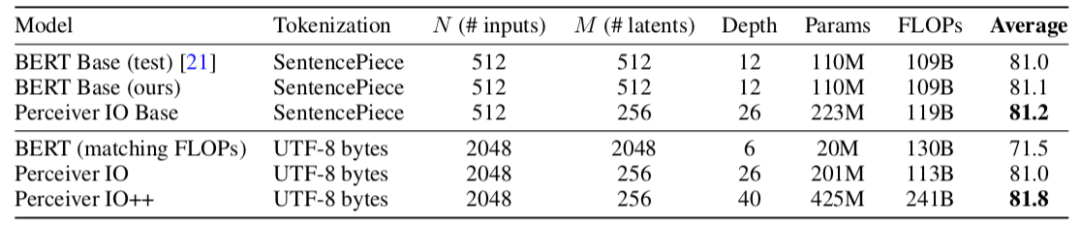
随后测试了Perceiver IO在光流估计任务上的表现,在多个数据集上的错误率都达到了前沿水平。


编译:T.R From: DeepMind
Illustrastion by Irina Molchanova from Icons8
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

> 投稿请添加工作人员微信!

本周上新!


扫码观看!
关于我“门”
▼
