SIGIR 2021 | 包内和包间注意力网络的包推荐
以下文章来源于北邮 GAMMA Lab ,作者李晨
北邮图数据挖掘与机器学习实验室

论文链接:
https://doi.org/10.1145/3404835.3462841

随着移动互联网中在线社交网络的蓬勃发展,一种新兴的推荐场景在用户获取信息中起着至关重要的作用,这种推荐场景不再为用户推荐单个商品或商品列表,而是将异质和多样化对象组合在一起推荐(称为包,例如一个包包含新闻,发布者和阅读过此新闻的朋友)。
与常规推荐只给用户推荐商品本身不同,在包推荐中,用户会对显式展示的对象表现出极大的兴趣,这可能会对用户的行为产生重大影响。然而,据我们所知,现有方法几乎没有尝试解决包推荐问题,并且几乎无法对包中各种对象的复杂相互作用进行建模。因此,在本文中,我们首次研究包推荐问题,并提出了基于包内与包间注意力网络的包推荐模型(IPRec)。
具体来说,为了建模包,我们提出了一种包内注意力网络来捕获用户与包交互的对象级的意图,而包间注意力网络则充当包层级的信息编码器,以捕获相邻包的协同特征。另外,为了捕获用户偏好表示,我们提出了一种用户偏好学习器,该学习器配备了细粒度特征聚合网络和粗粒度包聚合网络。在三个真实世界的数据集上进行的广泛实验表明,IPRec的性能明显优于现有方法。附加的模型分析证明了我们IPRec的可解释性以及用户行为特征。
一、引言
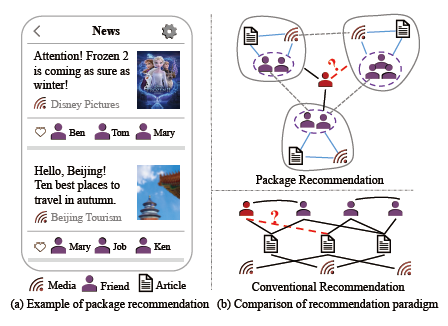
包推荐系统正在蓬勃发展,并已被数亿用户广泛使用。图1说明了在真实社交平台微信看一看中包推荐的典型场景。如图1(a)中所示,系统推荐给用户两个候选条目(我们称之为包),每个包包括新闻文章,新闻的发布者以及进行交互(例如,共享/喜欢/评论)的朋友。与仅向用户展示项目的传统推荐相反,在包推荐中还明确展示了异质和多样化的对象(例如,发布者和朋友),这将突出各种显示对象对用户行为的影响。仍然以图1(a)为例,两个候选包都被用户点击,但是原因不同。作为迪士尼的忠实爱好者,这个用户显然是出于自己的兴趣而点击了第一个包,因为他不会错过迪士尼公司发布的任何新闻。对于第二个推荐的候选包,用户点击它的主要原因可能是他的朋友(例如,他的配偶Mary)已经阅读了它,而不是被文章本身所吸引。这个直观的示例清楚地说明了包推荐和常规推荐之间的区别,包中的异质对象会对用户行为产生多方面的影响,后续实验也对此进行了验证。
基于此,我们针对包推荐问题提出了一个新颖的包内与包间注意力网络。具体地讲,我们提出了一种包内注意力网络,它包含一个社会影响力编码器以从社会关系中分解出多方面的影响力,并提供了一个交互层对来自不同对象的复杂和异构影响力进行编码来获得包的特征表示。同时,我们提出了一种包间注意力网络,该网络可作为包级信息编码器来融合相邻包的协同信息。
此外,为了捕获用户的偏好,我们提出了一个用户兴趣学习器,该学习器配备了两个不同粒度的聚合网络。细粒度特征聚合器融合对象级别的节点和类型异构信息,而粗粒度软件包聚合网络则聚合历史交互过的包信息。最后,利用学习到的包表示和用户表示,将它们输入到多层感知机中从而预测交互的概率。
为了捕获用户与包交互的多种意图,我们提出了一种用于包推荐的新颖的包内与包间注意力网络,称为IPRec。图2是IPRec的框架示意图。我们提出的IPRec包含三个组成部分:
· 包建模模块,包括包内注意力网络和包间注意力网络,其中包内注意力网络捕捉用户与包交互的对象级意图,包间注意力网络捕捉外部连接的邻居包的协同特征。
· 用户建模模块,包括两个特征聚合器,用于从不同角度建模用户兴趣。一个是细粒度的特征聚合网络,它将对象级别的节点和类型特征聚合融合在一起,另一个是粗粒度的包特征聚合网络,用于聚合历史交互过的包。
· 最后,预测器模块输入学习到的包和用户表示,并输出它们的交互概率y。
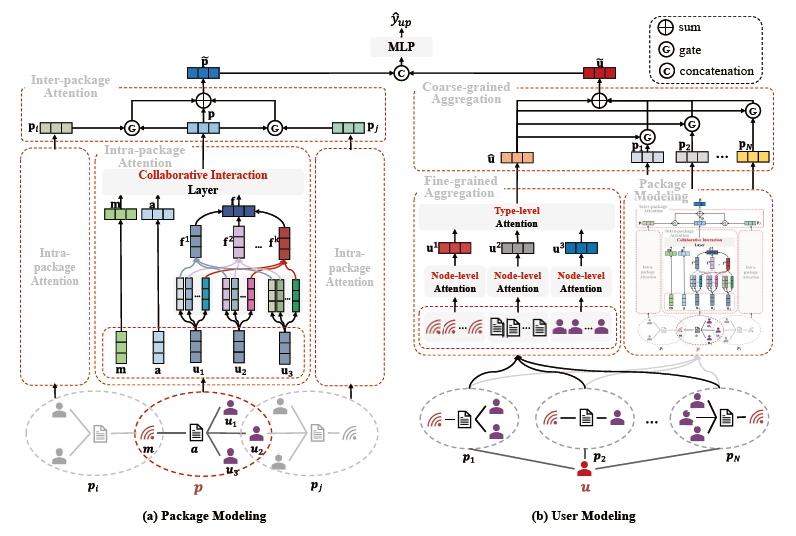
图2 IPRec的框架示意图
它包括三个部分:
· 包建模模块,通过包内和包间注意力网络学习包的表示,获取多方面的影响和协同信息;
· 用户建模模块,通过细粒度和粗粒度聚合网络对不同粒度的用户偏好进行建模;
· 以及评分预测模块,通过学习到的用户和包嵌入对评分进行预测。
2.1 包建模模块
IPRec的第一个组件是包建模模块,旨在学习包的潜在表示。如前所述,在包推荐中,包的连接状态包含包中对象的包内连接和多个包的包间连接。因此,我们设计了两个注意力网络,分别称为包内和包间注意力网络,以处理包内和包间连接。包内注意力网络融合了对象级属性,配备了社交影响力编码器以从社交关系中分解出多方面的影响,以及一个交互层对包中来自异质对象的复杂而多方面的影响进行编码。另一方面,包间注意力网络则通过门注意力机制聚集相邻包以捕获协同特征。接下来,我们将详细介绍包内注意力网络和包间注意力网络。
(1)包内注意力网络
正如前面提到的,包内异质对象能够更好地得到包表示,尤其是包内朋友对用户行为具有不同的社会影响。例如,当包中的文章与技术相关时,技术专家朋友可能会对用户产生更大的影响,而亲密的朋友可能会在娱乐方面文章影响更大。因此,我们首先对朋友的影响力进行解耦得到解耦的社会影响,然后将所有在一个包中的对象相互交互,以模拟用户与包交互的复杂意图。
我们首先解耦朋友 和文章a到k个解耦空间如下式:
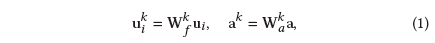
随后,对于包P中的文章a,朋友社交影响力第k个解耦嵌入 可以表示为:
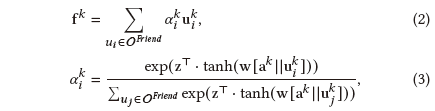
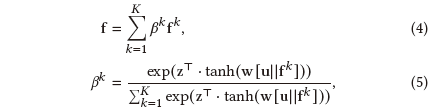
其次,由于包中的异质对象对用户行为的影响是多方面的,所以我们让包中的每个对象进行交互,从而协同融合异质、多样化的信息。回想一下,对于包P,我们有文章a,媒体m和朋友 ,其表示分别为 a,m 和f ,我们定义组合影响如下:
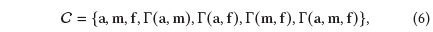
其中 作为融合函数,可以是级联,加法或按元素乘积(我们在本文中采用按元素乘积)。然后,我们利用注意力机制来提取当前用户u对于多方面信息的不同偏好,并将其融合为:
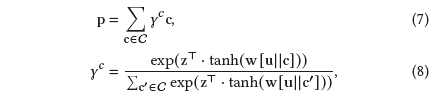
(2)包间注意力网络
除了包中对象的内部连接之外,包之间还存在外部连接,这些外部连接为包的特征表示注入了协同信息。为了融合协同信息,我们将包集通过门过滤器聚合在一起,如下所示:
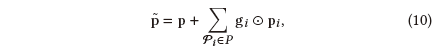
2.2 用户建模模块
我们提出的IPRec的第二个组件是用户建模模块,它被设计用来捕获用户的基本偏好。直观地说,包中的异质对象和不同包都为用户偏好提供了多方面的信息,它们从不同的角度揭示了用户的兴趣。因此,我们在两种不同的粒度上融合这些多方面和异质的用户偏好信息,包括细粒度特征聚合网络融合对象特征,以及粗粒度特征聚合网络聚合历史交互的包。
(1)细粒度特征聚合网络
考虑到多种类型的对象具有不同的特征,其特征可能落在不同的特征空间中,设计一个层次注意力聚合网络是进行对象特征聚合的关键,能够捕获不同节点和类型的异质信息。
Node-level Attention: 我们提取与用户交互过的包中的所有对象,以在细粒度级别捕获用户偏好。首先,我们区分多个相同类型的不同对象对用户偏好的不同贡献。对于所有类型为t的对象,我们以节点级的注意力机制将它们聚集到类型空间t中:
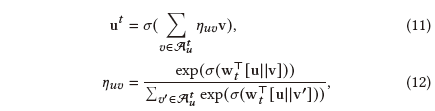
Type-level Attention: 此外,学习到用户u在各种类型空间中的多个嵌入表示后,我们学习不同类型空间中多样信息的注意力权值,然后将其通过类型级注意力机制融合:
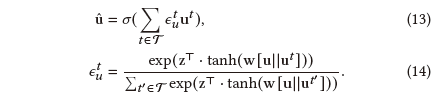
(2)粗粒度特征聚合网络
为了进一步在粗粒度级别捕获用户偏好,我们使用前面介绍的门控机制聚合用户u历史交互过的包,如下所示:
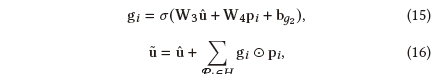
2.3 预测与模型优化
现在我们获得用户u与包P的表示,我们将它们拼接起来输入两层MLP预测最终点击概率:
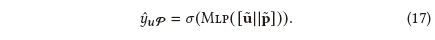
为了优化我们的模型,我们使用交叉熵作为我们的损失函数:
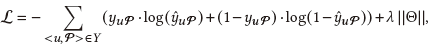
3.1 性能实验
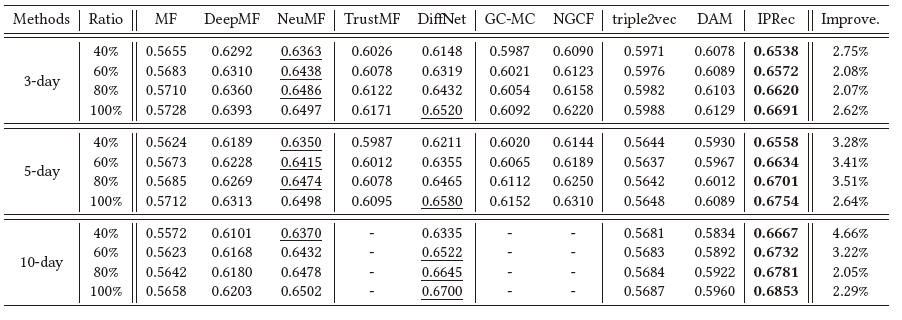
表1. 在三个数据集上的各个方法的性能实验结果。最好的方法用粗体表示,次优的方法用下划线表示。最后一列显示了IPRec相对于次优模型的提升。'-'表示由于内存不足,模型无法训练获得结果。
从表中我们可以得出以下结论:
总的来说,我们提出的IPRec在三个数据集上的所有方法中始终具有最好的推荐性能,与最佳性能的对比方法相比,它在AUC上仍然带来了2.05%-4.66%的提高。我们分析认为这些显著的性能提升归功于针对异质和协同信息设计的包内和包间注意力网络。
在不同的对比方法中,传统的矩阵分解方法是最不具竞争力的,因为在我们的包推荐场景中,矩阵分解方法很难处理多方面的信息。同时,我们注意到,在我们的场景中,NGCF的性能比NeuCF差,分析其原因是因为在我们的数据集中,一篇文章会被大量用户点击的,而基于图的方法(即NGCF)聚合所有邻居会导致过平滑问题,降低推荐性能。社交推荐方法(如TrustMF和DiffNet)由于融入了社交关系的影响而表现得更好,但在所有数据集上仍然不如我们的IPRec。原因可能是他们都只是将社交关系作为辅助信息,而没有探究朋友对用户行为的复杂和多方面的影响。而在IPRec中,我们设计了包内注意网络,学习针对特定包的好友解耦表示,从而仔细捕捉包中复杂的社会影响和用户意图。商品集推荐方法利用包中的所有对象,性能略有提高,但仍然低于我们提出的IPRec。这是有理由的,因为这些方法将异质对象视为同一类型的商品,从而忽略了多方面的信息。
从纵向比较来看,IPRec在不同规模的训练数据中表现最好,这意味着我们方法的稳定性和鲁棒性。而且,随着数据规模的增大,我们的IPRec的提升也更加明显,说明IPRec更适合实际工业应用中的大规模数据。相反,基于图卷积网络的方法对于大规模数据集计算效率低下,甚至由于内存不足而无法进行训练。
3.2 可解释分析
(1)微观可解释性
我们在包推荐场景中选择了四个阅读推荐条目时关注不同因素的用户,然后在图3中可视化了他们在与包交互时中对对象的注意力分布。

图3. 微观可解释性分析,其中“f”,“a”和“m”分别表示朋友,文章和媒体。
· 编号为263145的用户主要关注包内的文章因素,因为大多数交互包内文章的注意力权重都明显高于其他对象或组合。事实上,编号 263145用户的注意力分布也表明,他/她在推荐系统中是一个传统的用户,用户对新闻文章有自己的个人偏好,其行为受到文章的显著影响。
· 然而,包推荐的独特特点,即推荐异质对象的组合,使得用户也会受到其他对象的影响。如图3(b)和©所示,编号613和编号786807的用户分别更关注包中的好友和公众号因素,而不是文章本身。特别地,编号613的用户明显受到与包有过互动的朋友的影响,这意味着编号613用户是一个重视社交关系的人,更喜欢阅读朋友推荐和过滤的文章。
(2)宏观可解释性
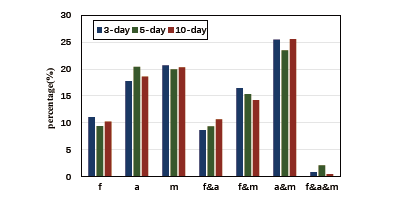
从宏观角度来看,我们进一步分析了导致用户与包交互的各种原因的比例。具体来说,如果对象或组合在用户u交互的大多数包中具有最高的注意力权重,我们认为其是用户u在“看一看”浏览信息时关注的最主要因素。因此,我们可以计算整个数据集中的用户关注不同因素的比例,如图4所示。可见,大多数用户只关心包内的单个对象影响,几乎达到了50%,这与上述个体分析是一致的。此外,异质对象的组合对用户也有很大的影响。例如,文章和公众号的协同影响是用户与包进行交互的主要原因,该比例达到约25%,远大于单个文章或公众号影响的百分比。这是有道理的,因为对公众号的认可可以提高文章的可信度,从而对用户行为产生更大的影响。
在本文中,我们首先研究了一种被广泛采用的推荐场景,即包推荐,向用户推荐异质对象的组合。为了对包推荐进行建模,我们提出了一种新颖的包内和包间注意力网络,称为IPRec,该网络捕获包中异质对象的多方面影响以及包之间的协同信息。为了捕获用户的喜好,我们设计了一个细粒度的特征聚合网络和粗粒度的包聚合网络,从不同的角度对用户嵌入进行建模。在三个真实数据集上的大量实验结果表明,我们提出的IPRec始终优于最新方法,并且展现出优异的可解释能力。
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

> 投稿请添加工作人员微信!

扫码观看!
本周上新!

关于我“门”
▼
