YOffleNet | YOLO V4 基于嵌入式设备的轻量化改进设计
以下文章来源于集智书童 ,作者ChaucerG
机器学习知识点总结、深度学习知识点总结以及相关垂直领域的跟进,比如CV,NLP等方面的知识。


一、简介
最新的基于CNN的目标检测模型相当精确,但需要高性能GPU实时运行。对于内存空间有限的嵌入式系统来说,它们在内存大小和速度方面依旧不是很好。
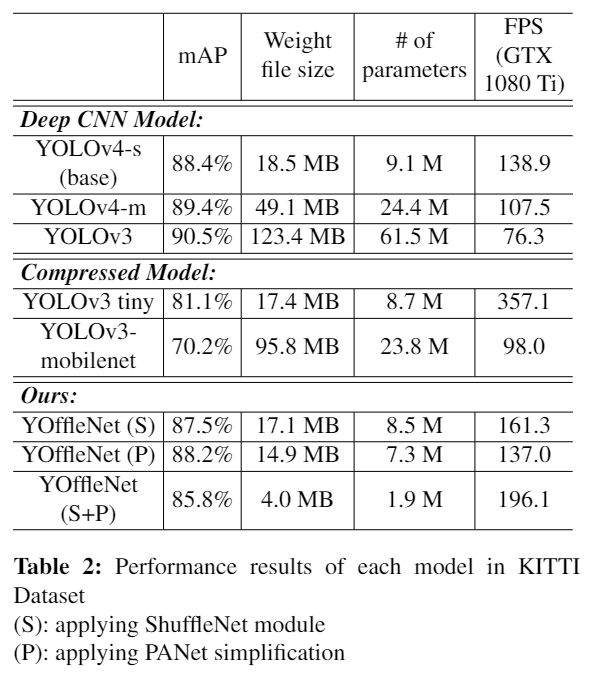
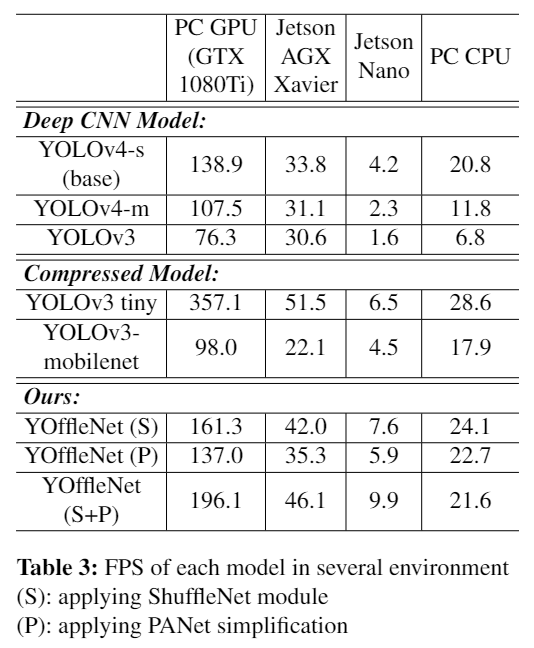
由于目标检测是在嵌入式处理器上进行的,因此在保证检测精度的同时,最好尽可能地压缩检测网络。有几个流行的轻量级检测模型,但它们的准确性太低。因此,本文提出了一种新的目标检测模型 YOffleNet,该模型在压缩率高的同时,将精度损失降到最小,可用于自动驾驶系统上的实时安全驾驶应用。该模型的Backbone架构是基于YOLOv4实现,但是可以用ShuffleNet的轻量级模块代替CSP的高计算负荷的DenseNet,从而大大压缩网络。
在YOLOv4的主干网络CSPDarknet-53中,CSP将特征卷积一定次数后复制使用与前一层特征cat起来,然后利用DenseNet模块。
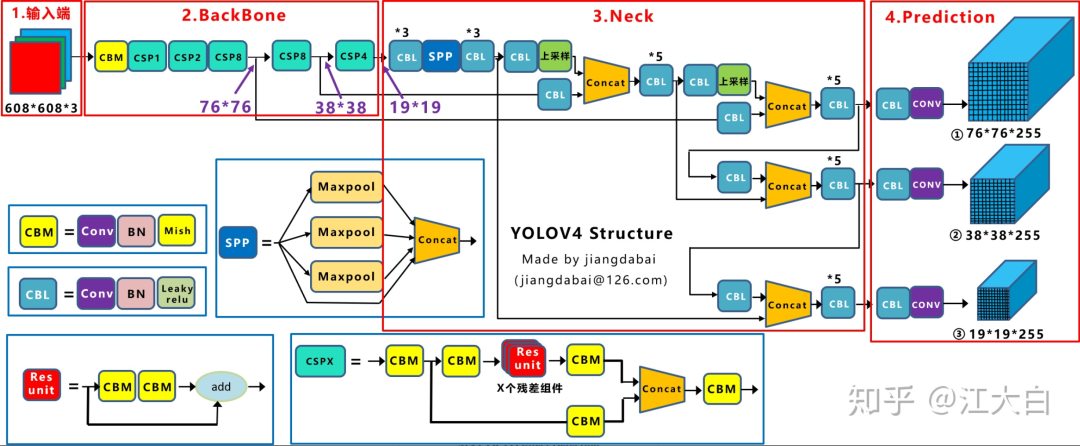
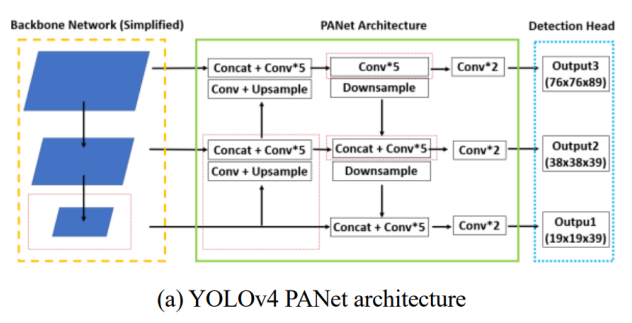
在Neck中,输入特征图有3种大小。SPP最大池化后concat技术提高了各种尺寸输入的准确性。此外,它通过自底向上的路径增强技术平滑特征。
YOLOv4引入PANet以促进信息流和它弥补了权重带来的精度损失问题。
YOLO v4的Head依旧采用YOLOv3的物体检测方法。
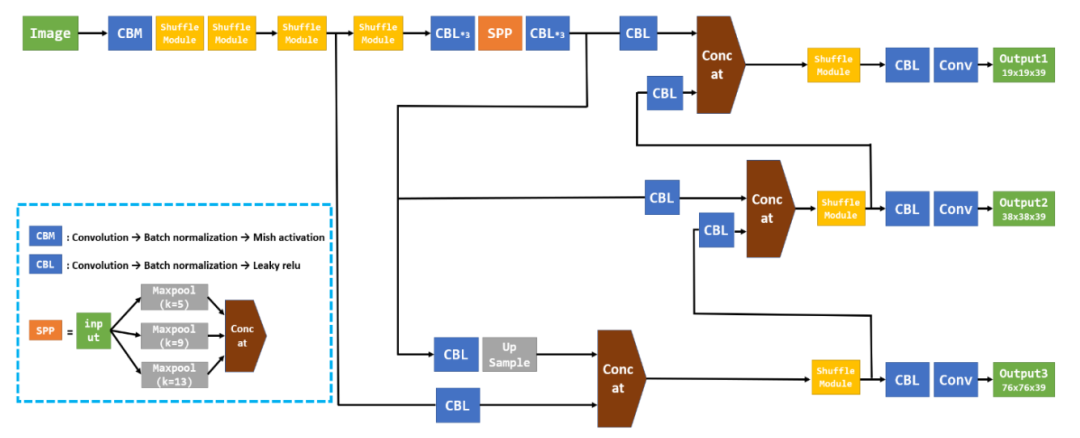 YOffleNet
YOffleNet
YOLOv4中使用的主要模块是下图中的CSP DenseNet;此外为了防止初始特征图中的信息丢失的问题,作者还设计了PANet结构,其是通过自下而上的路径增强特征表达的。它促进信息的流动的同时也增加了特征图中的通道数、增加参数的数量,这也是YOffleNet模型为它改进了上述YOLOv4模型的缺点。
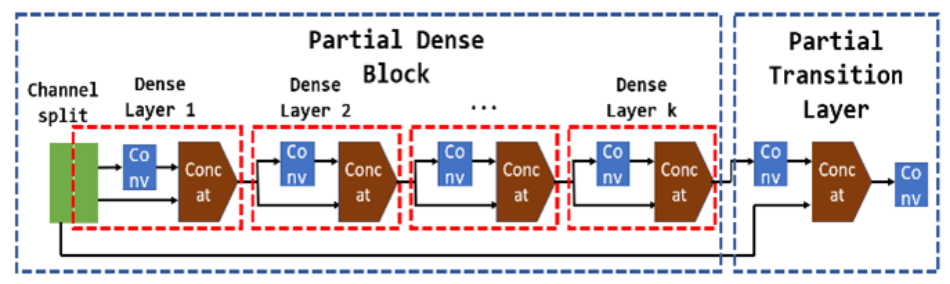 CSP DenseNet
CSP DenseNet
改进点 1
主干层CSP DenseNet是一种随着深度增加而不可避免地增加计算量的结构。在本研究中,主干网络层被配置为ShuffleNet模块。
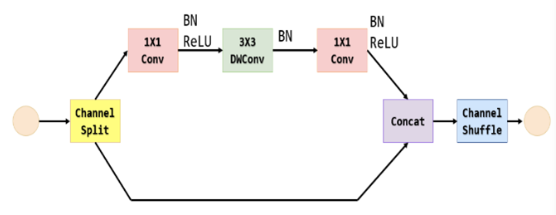
ShuffleNet模块
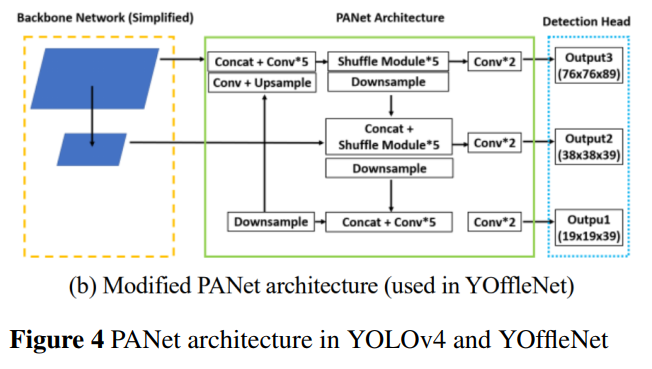
改进点 2
YOLOv4网络中使用的SPP+PANet结构简化和减轻模型的大小。现有YOLOv4模型的PANet从主干网络分为3层作为输入的。然而,常见对象检测情况与自动驾驶环境不同,有限类别中的物体检测(汽车、行人等,更小的目标也就少了)。
[1] Developing a Compressed Object Detection Model based on YOLOv4 for Deployment on Embedded GPU Platform of Autonomous System
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

> 投稿请添加工作人员微信!

扫码观看!
本周上新!

关于我“门”
▼
