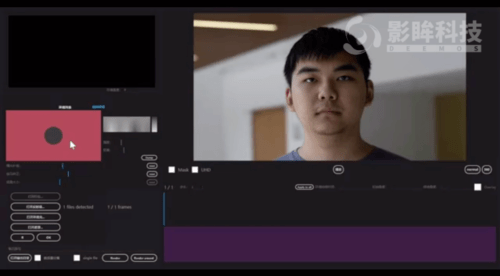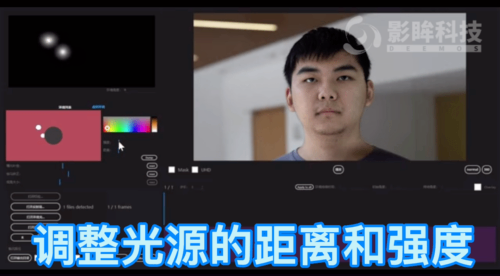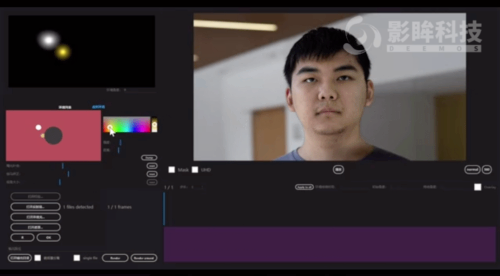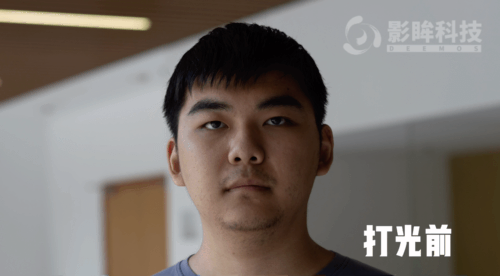
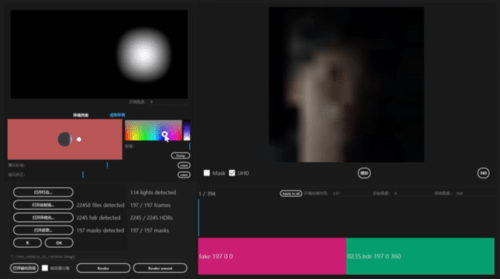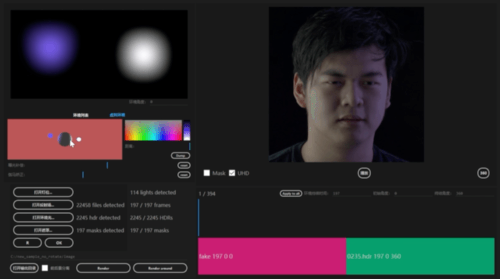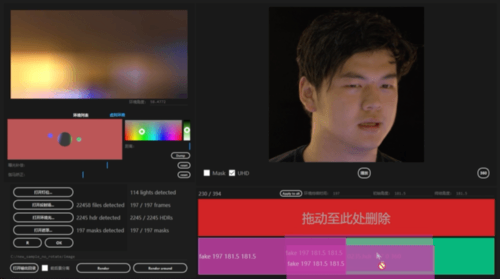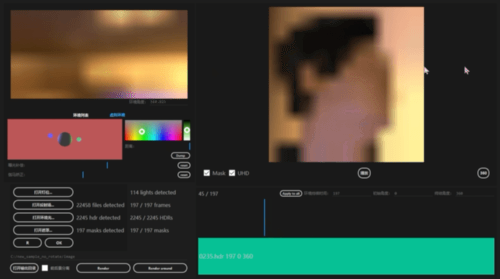
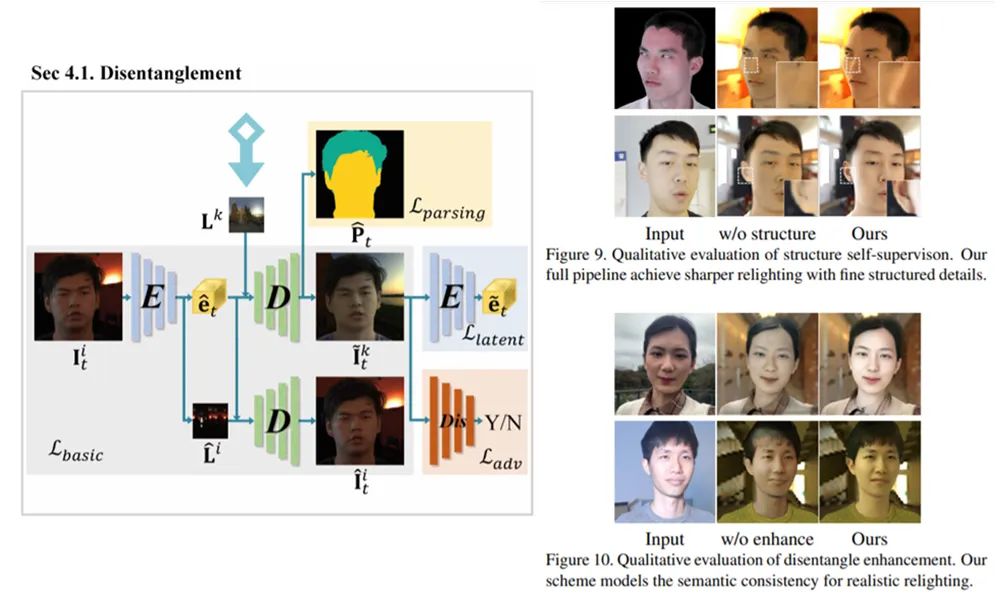
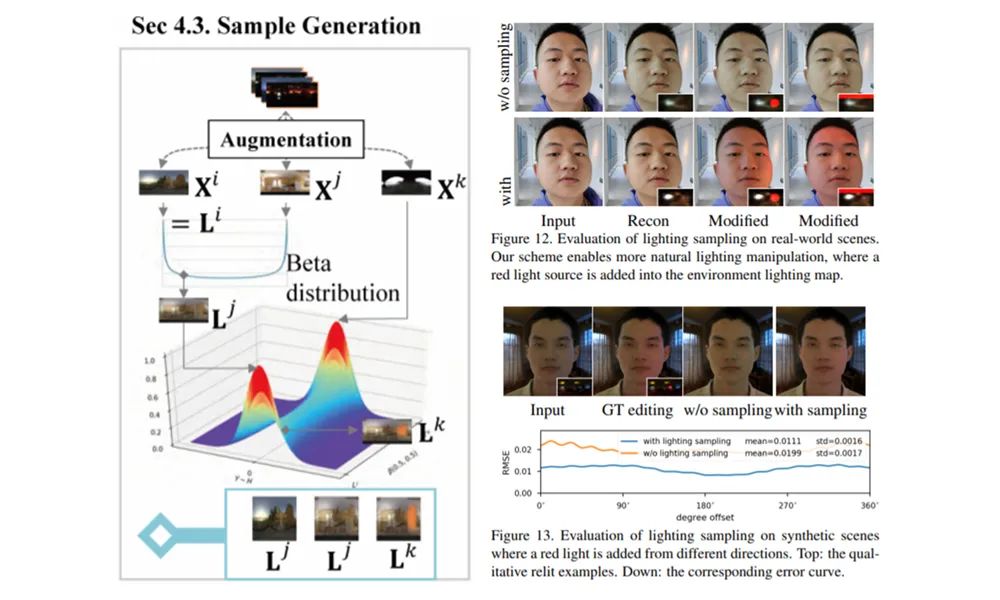
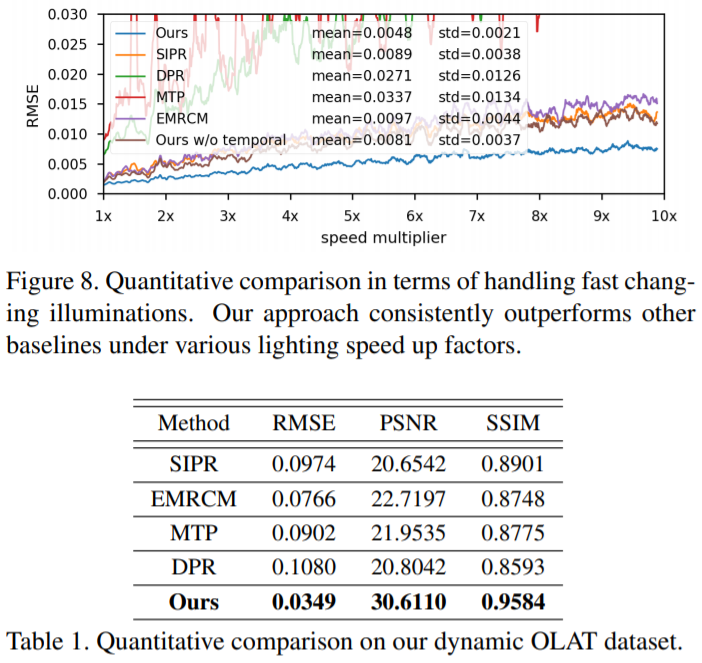
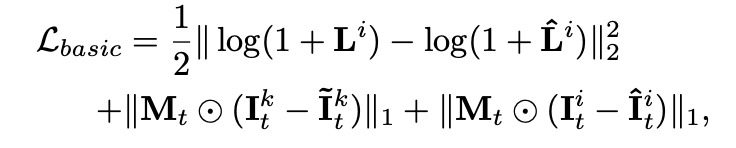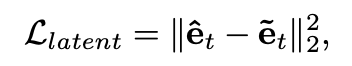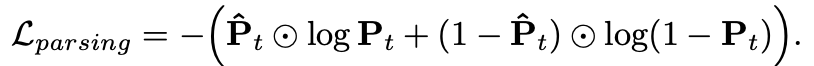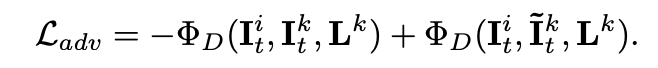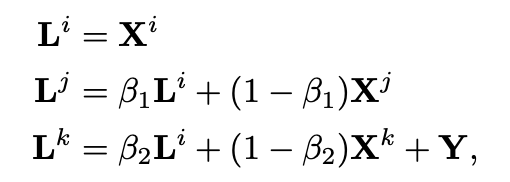图 2 模型更换光影后的输出结果这个研究主要有以下亮点:· 研究者提出了一种基于神经网络的新型实时人像视频重打光方法,使模型的输出在光影变化时足够连贯,效果显著优于现存的最佳模型;· 研究者将人像结构信息与光影信息分离,通过自有的时序建模方法和光影采样策略,使得使用者可实时编辑光影;· 研究者构建了动态的单帧单一光照的影像数据集(One Light at A Time,OLAT)单帧单一光照。这个数据集包含了 36 位实验参与者共计 603,288 张动态 OLAT 影像,可支持后续的人像与光照研究。
一、动态、单一光照(OLAT)
:新的数据集是怎么炼成的?
从监督学习的角度对单张图片应用重打光的难点是数据集的丰富程度,我们需要同一人像在大量不同光照下的对应数据,而实拍几乎是不可能的。这个问题在 MARS 实验室的支持下得到了解决。我们实验室自主研发的穹顶光场(Light Field Stage)由包含 114 个 LED 光源和一台 1000 fps 的 4K 超高速摄像机组成。穹顶光场以多灯光与高速相机的配合,帮助研究者成功采集出动态单帧单一光照(OLAT)的影像数据,解决了人像重打光面临的数据瓶颈。
图 3 穹顶光场(Light Field Stage) 采集数据、应用数据的过程。
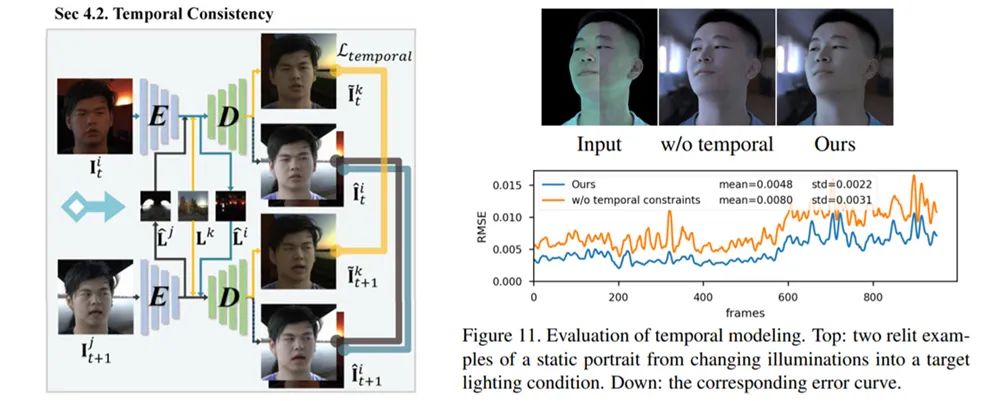
为了实现高效率的数据采集与处理,我们也制定了一套数据采集流程、开发了一套数据处理工具链,并最终采集处理了 36 位实验参与者共 603,288 张影像数据,建立了第一个动态单帧单一光照(OLAT)的数据集。图 4 模型更换光影的工具使用过程二、框架方法人像结构信息与光影信息分离这篇论文提出的框架以 U-Net 结构作为基础,可以看作是含有跳跃连接的编码器 - 解码器组合。编码器对输入人脸编码出光照信息 L 和结构信息 e ,解码器通过光照信息和结构信息生成对应的人脸。论文提出了针对人脸结构信息的自监督学习,让同一人脸在不同光照条件下编码出相同的结构信息e ,以便和人脸携带的光照信息 L 解耦。编码器同时对源图像和目标图像(在不同光照下的生成结果)编码出两个隐向量,并优化两个隐向量的距离。这篇论文提出的框架同时监督网络输出对于人脸的分割 P ,让网络学习人脸的语义结构,以期在未知的人脸上获得更好的表现。 同时,这篇论文还使用对抗生成训练,使用辨别器 加强网络输出的细节。 时间连续性约束 ——动态单帧单一光照的诀窍通过采集的时间连续的单帧单一光照(OLAT)数据,研究者可以计算出前后帧之间的的光流信息 t,t+1,以此在网络训练的过程中提供额外的时序信息。这篇论文提出的框架在训练时将多个前后相邻的 OLAT 数据输入给网络,将输出的图像经光流变换后计算损失函数,同时在多次前向传播过程中进行优化。这样的方式使得网络可以让变化光照条件下的人脸序列,经过重打光后在时间上连贯。这篇论文提出的框架在应用的时候仅需要单帧作为输入,而不需要额外的时间信息,即可以获得具有时间连续性的输出。