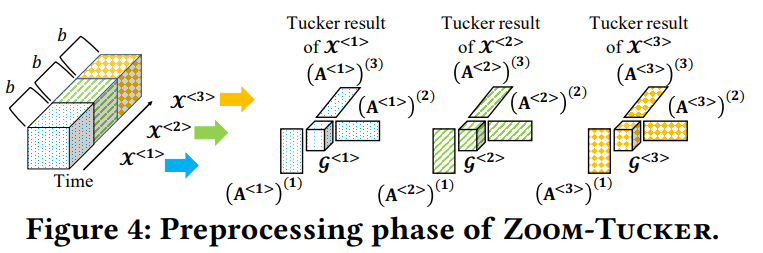
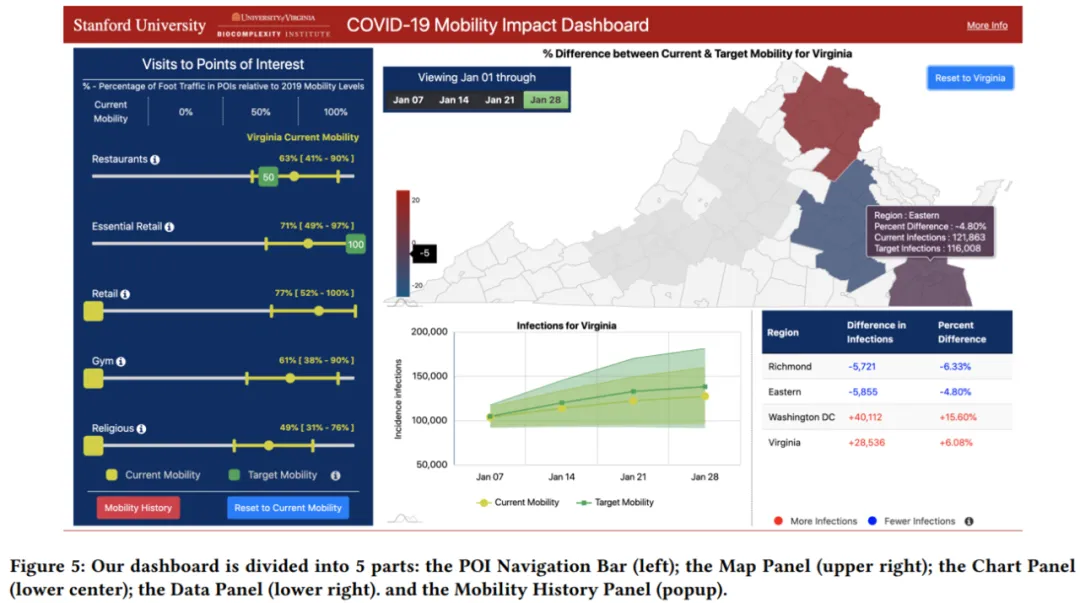
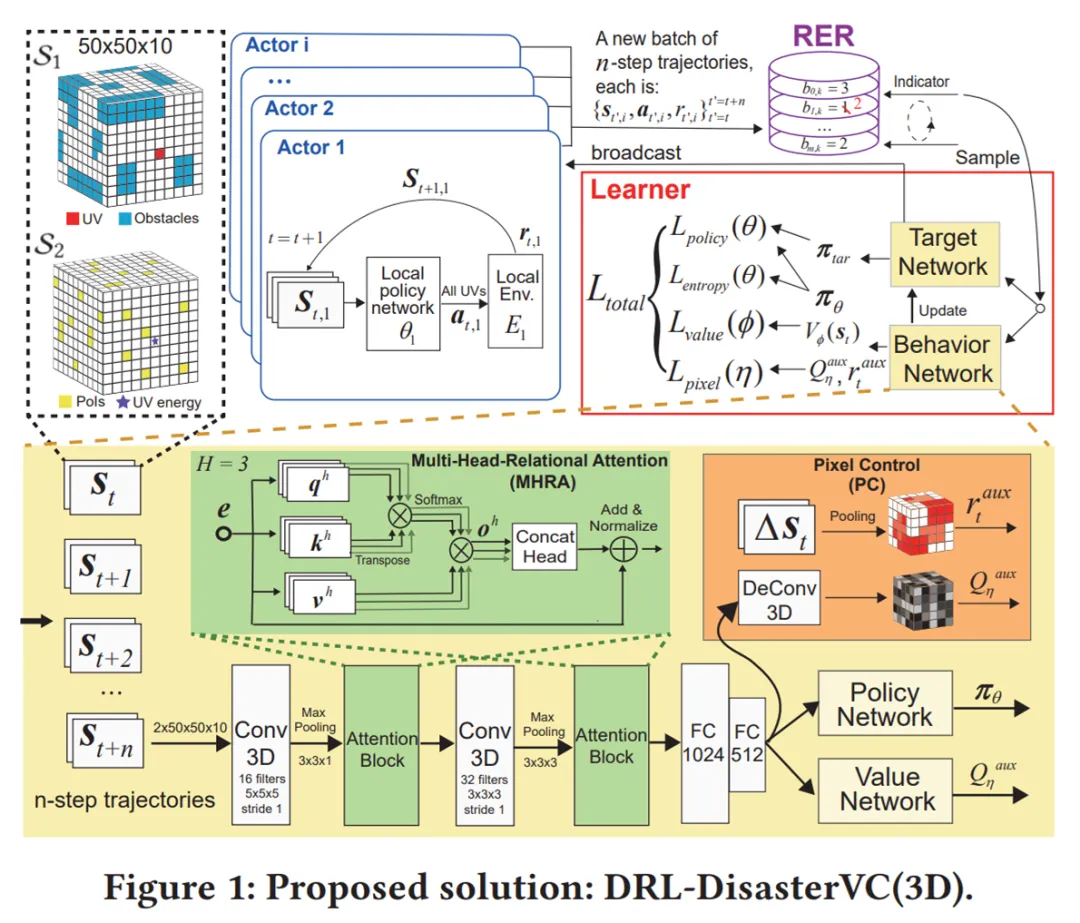
由 5 部分组成的交互式仪表板,分别是 POI 导航栏(左)、地图面板(右上)、表格面板(中下)、数据面板(右下)和移动性历史面板(弹出窗口)。 推荐:KDD 2021 应用数据科学方向最佳论文奖。 论文 4:Energy-Efficient 3D Vehicular Crowdsourcing For Disaster Response by Distributed Deep Reinforcement Learning
1. Active Learning for Massively Parallel Translation of Constrained Text into Low Resource Languages. (from Alex Waibel)2. SAPPHIRE: Approaches for Enhanced Concept-to-Text Generation. (from Eduard Hovy)3. TSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity. (from Yifan Hu)4. Integrating Dialog History into End-to-End Spoken Language Understanding Systems. (from Brian Kingsbury)5. Mr. TyDi: A Multi-lingual Benchmark for Dense Retrieval. (from Jimmy Lin)6. Complex Knowledge Base Question Answering: A Survey. (from Jing Jiang, Ji-Rong Wen)7. Fine-Grained Element Identification in Complaint Text of Internet Fraud. (from Lei Chen)8. AdapterHub Playground: Simple and Flexible Few-Shot Learning with Adapters. (from Iryna Gurevych)9. MeDiaQA: A Question Answering Dataset on Medical Dialogues. (from Yan Liu)10. Accurate, yet inconsistent? Consistency Analysis on Language Understanding Models. (from Thomas Lukasiewicz) 10 CV Papers.mp300:0021:22
本周 10 篇 CV 精选论文是:
1. Fully Convolutional Networks for Panoptic Segmentation with Point-based Supervision. (from Jian Sun, Jiaya Jia)2. Clustering augmented Self-Supervised Learning: Anapplication to Land Cover Mapping. (from Vipin Kumar)3. Finding Representative Interpretations on Convolutional Neural Networks. (from Jian Pei)4. Towards unconstrained joint hand-object reconstruction from RGB videos. (from Ivan Laptev, Cordelia Schmid)5. Pixel Difference Networks for Efficient Edge Detection. (from Qi Tian, Matti Pietikäinen, Li Liu)6. Federated Multi-Target Domain Adaptation. (from Ming-Hsuan Yang)7. Generalized and Incremental Few-Shot Learning by Explicit Learning and Calibration without Forgetting. (from Bernt Schiele)8. Variational Attention: Propagating Domain-Specific Knowledge for Multi-Domain Learning in Crowd Counting. (from Wangmeng Zuo, Lei Zhang)9. SynFace: Face Recognition with Synthetic Data. (from Wei Liu, Dacheng Tao)10. Structure-Aware Feature Generation for Zero-Shot Learning. (from Wei Liu, Dacheng Tao)
10 ML Papers.mp300:0020:18
本周 10 篇 ML 精选论文是:
1. Learning Equilibria in Matching Markets from Bandit Feedback. (from Michael I. Jordan)2. Weakly Supervised Classification Using Group-Level Labels. (from Vipin Kumar)3. Continual Backprop: Stochastic Gradient Descent with Persistent Randomness. (from Richard S. Sutton)4. Understanding Structural Vulnerability in Graph Convolutional Networks. (from Liang Chen, Yang Liu)5. A physics-informed variational DeepONet for predicting the crack path in brittle materials. (from George Karniadakis)6. Towards Understanding Theoretical Advantages of Complex-Reaction Networks. (from Zhi-Hua Zhou)7. Effective and Efficient Graph Learning for Multi-view Clustering. (from Xinbo Gao, Dacheng Tao)8. Provable Benefits of Actor-Critic Methods for Offline Reinforcement Learning. (from Martin J. Wainwright)9. Panoramic Learning with A Standardized Machine Learning Formalism. (from Eric P. Xing)10. Incremental cluster validity index-guided online learning for performance and robustness to presentation order. (from Donald C. Wunsch II)