ICCV 2021 | 百度YY直播等科技公司提出自监督学习助力人手图像理解新方法——HIU-DMTL优化框架

论文链接:
https://arxiv.org/abs/2107.11646

一、引言
最近一段时间,Metaverse元宇宙概念引起了巨大的轰动,其核心的概念在于沉浸式交互体验。而人手作为最重要的交互部位,相关课题比如人手重建、人手分割、人手2D关键点检测、人手3D关键点估计等等这些都成为了学术界和工业界的重点研究方向。自[1,2,3,4]在2019年首次提出并实现人手重建以来,人手重建等相关研究仍然面临着以下难题:
· 当前已有的数据的标签很难统一,比如:一些样本仅包含2D关键点标注;有的数据只有对应的人手分割Mask。怎样充分的利用已有的多模态数据是一个急需解决的问题;
· 已存在的数据大部分在受控的实验室场景下采集,基于这些数据集训练的模型在生产环境下缺乏鲁棒性。是否可以利用大量未标注的样本提升算法的泛化性很少被研究;
由百度YY直播 联合 欢聚集团、OPPO 等科技公司发表于ICCV 2021的一篇论文 Hand Image Understanding via Deep Multi-Task Learning 提出一个将多任务学习和自监督学习联合优化的框架 HIU-DMTL ,去解决以上问题。
二、方法
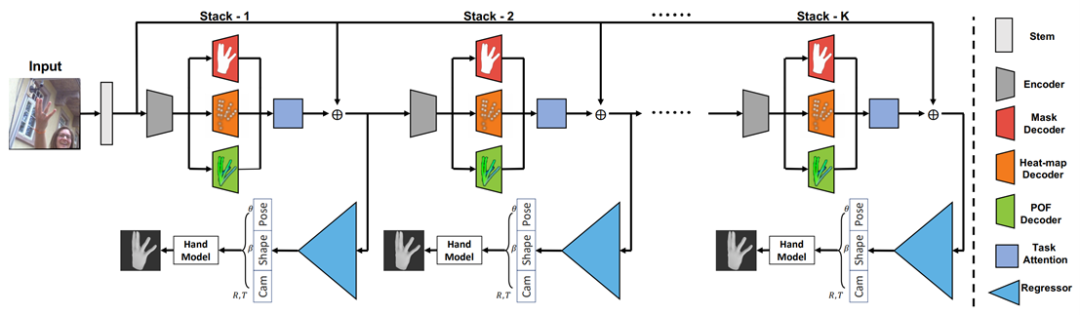
HIU-DMTL的主要架构图
整个框架遵循经典的层级式的由粗到细的设计范式,主要包含两个主要部分:
1.一个多任务学习的骨干网络,主要用于估计2D 关键点的热度图、人手区域的分割Mask以及生成包含3D语义的POF编码;
2.基于上述多模态语义信息回归人手参数化模型MANO参数以及相机参数的回归器。
HIU-DMTL基于多任务学习充分利用已有的多模态数据达到人手图像理解的目的,即:从单张RGB图像实现人手重建、人手分割、人手2D关键点检测、人手3D关键点估计。在HIU-DMTL的骨干网络中,POF主要用于编码一部分3D信息,从而达到减少2D 到 3D 之间的domain gap的目的,POF的定义如下所示:
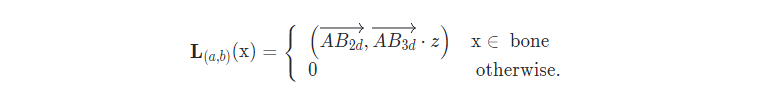
为了减小人手重建的难度,与[2]类似,HIU-DMTL也基于回归MANO系数的方式来实现人手重建的目的。MANO 的是一个由人手pose参数( θ )和shape参数( β )控制的参数化模型,给定{ θ,β } 后,人手模型的表达由下式形式化的给出:
为了进一步提高算法的效果,HIU-DMTL遵循由粗粒度处理到细粒度处理的设计准则,具体来讲,HIU-DMTL包含多个结构相同的子模块,每个子模块不断的refine先前模块的输出结果,下图较好的刻画了该过程:
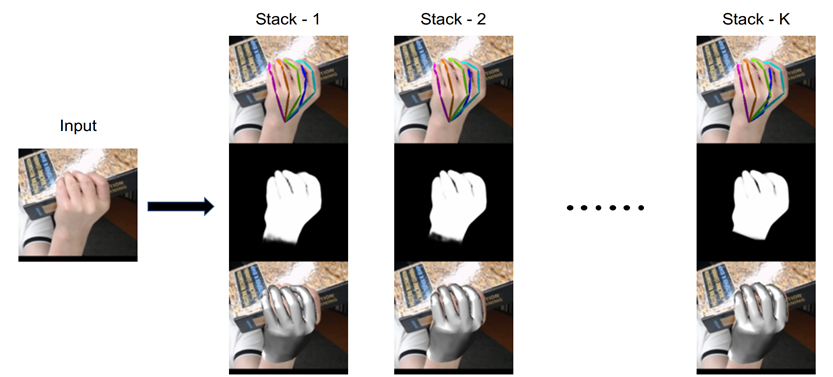
HIU-DMTL的核心思想。即由粗粒度到细粒度地完成人手重建、人手分割、人手2D关键点检测、人手3D关键点估计。
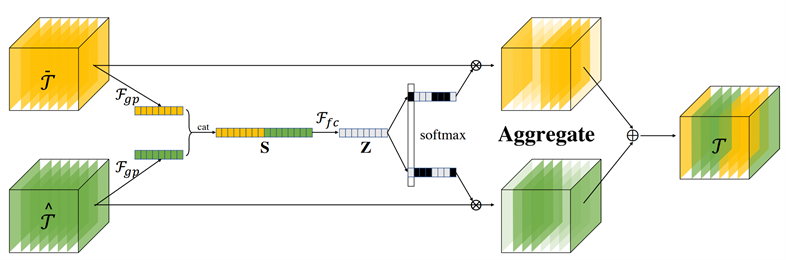
此外HIU-DMTL提出任务聚合模块(Task Attention Module – TAM)用于融合不同任务之间的特征。从数学上讲,TAM可形式化为一个函数 ,n=2 时模块可视化如下所示:
· 关键点检测到的2D人手关键点应该与3D关键点在图像上的投影相同;
· 人手重建的结果经微分渲染模块后的结果应与分割分支的预测结果一致;
HIU-DMTL提出基于这些潜在约束的一个训练方式,以达到在训练过程中充分利用大量无标注样本的目的。
三、实验
泛化实验:
与先前的方法相比,HIU-DMTL的泛化性更好。


量化实验:
HIU-DMTL与最新的方法相比,也完全不落后。得益于多任务学习和自监督学习,在一些评测指标上HIU-DMTL大幅领先于最新方法。
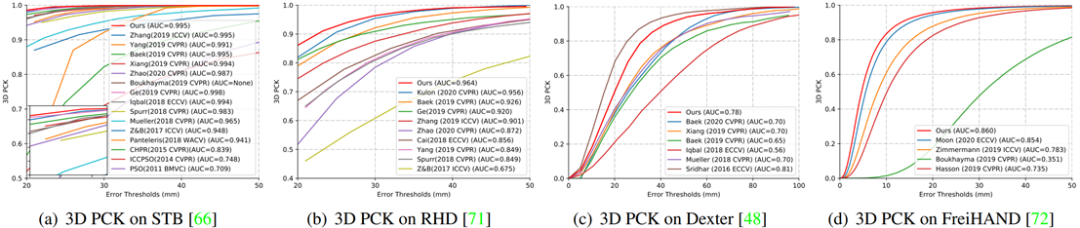
实验表明在人手图像理解任务中,多任务实习策略能提升各子任务的性能,
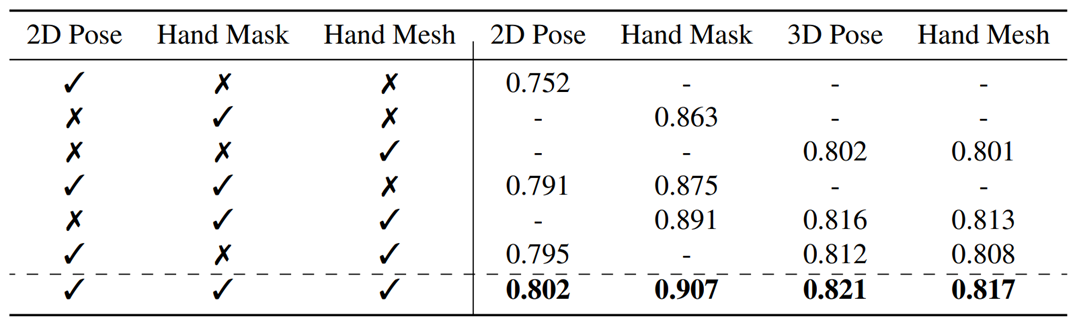
消融实验(由粗到细的学习方法):
实验表明由粗粒度到细粒度的方法对于人手图像理解是有益的。
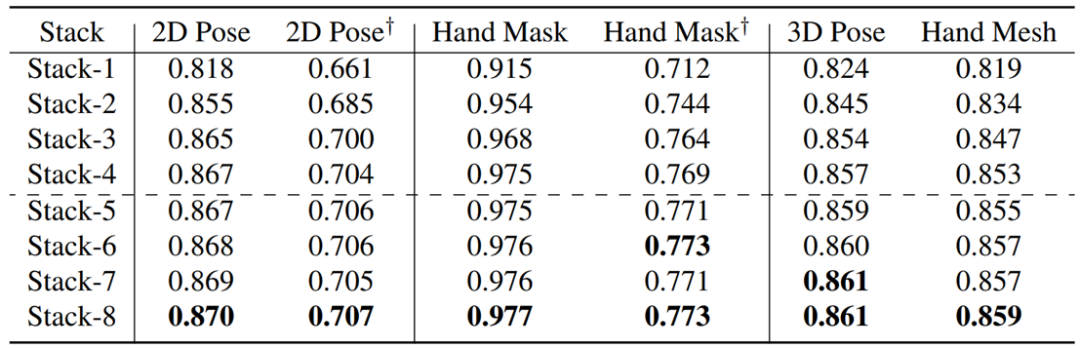
消融实验(任务聚合模块的效果):
各种实验设置均表明TAM模块能提升人手图像理解任务中各任务的性能。
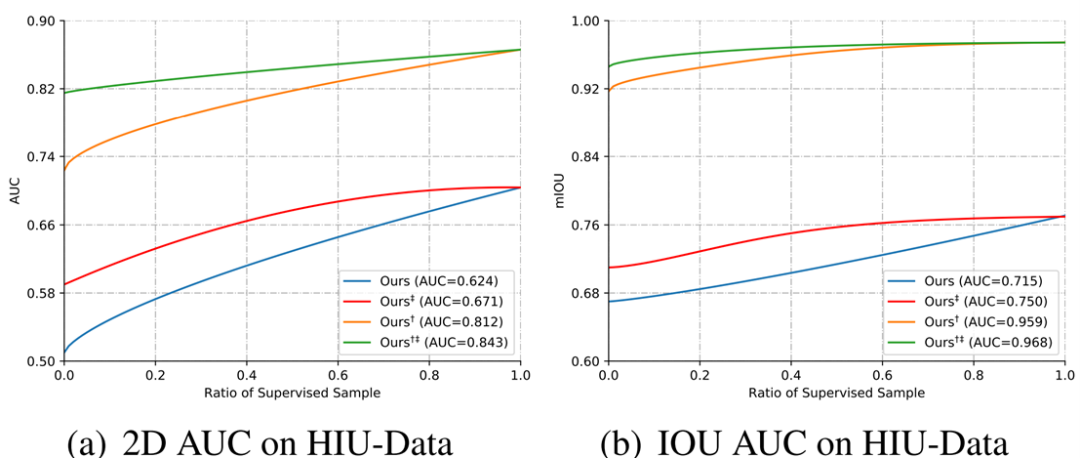
消融实验(自监督学习方法):
实验表明,自监督学习对于提高算法的效果有着极为重要的作用,

四、总结
随着VR等应用的兴起,人手交互相关的研究成为一个工业界和学术界的研究热点,但是人手相关的研究面临着数据模态不统一以及缺乏生产环境下的标注数据这两大难题。基于这些痛点,HIU-DMTL引入多任务学习和自监督学习极大的克服了这些问题,相信HIU-DMTL提出的方法论能用于解决其它领域类似的痛点难题。
参考文献:
[4]. Liuhao Ge, Zhou Ren, Yuncheng Li, Zehao Xue, Yingying Wang, Jianfei Cai, and Junsong Yuan. 3d hand shape and pose estimation from a single rgb image. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2019
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

> 投稿请添加工作人员微信!

扫码观看!
本周上新!

▼
