KDD 2021|美团联名信用卡技术实践:自适应信息迁移多任务(AITM)框架
以下文章来源于美团技术团队 ,作者冬博 陈振 燕鹏等
10000+工程师,如何支撑中国领先的生活服务电子商务平台?数亿消费者、数百万商户、2000多个行业、几千亿交易额背后是哪些技术在支撑?这里是美团、大众点评、美团外卖、美团配送、美团优选等技术团队的对外窗口。

论文链接:
https://arxiv.org/abs/2105.08489
源代码:
https://github.com/xidongbo/AITM

一、摘要
大多数大规模应用通常都需要用定向展示广告来获客,比如电子商务平台或者金融应用。随着这类应用的爆炸式增长,持续有效的获客已经成为现实世界中这些大规模应用的最大挑战之一。在这些应用中,获客通常是一个用户多步转化的过程。例如,在电子商务平台中,用户转化通常表现为一个 曝光->点击->购买 的过程。而在金融广告,比如信用卡业务中,用户转化通常是一个 曝光->点击->申请->核卡->激活 的过程。在信用卡广告中获客比传统广告更加具有挑战性:
· 用户多步转化过程中的路径序列依赖更长。
· 在多步转化的长序列依赖中,正反馈(正样本)是逐步稀疏的,类别不平衡越来越严重。
在我们的信用卡业务中,我们通常希望用户能完成最后两个转化阶段(即曝光->核卡、曝光->激活),这才被认为是有效转化。因此,用前边任务的丰富的正样本信息来缓解后续任务的类别不平衡问题是很有必要的。在这个方向上,多任务学习是一个提高端到端获客转化率的典型解决方案。
二、背景介绍
在我们的信用卡业务中,
· 曝光(impression):意味着广告被展示给了特定的用户**,这些用户是根据一些排序指标选中的,比如CTR, CVR等等。
· 点击(click):用户如果对这个广告内容感兴趣的话,他会点击这个广告,点击后,就会进入申请表格页。
· 申请(application):进入申请表格页后用户可以填写申请表格,并且点击申请按钮来申请一张信用卡。
· 核卡(approval):也称授信,意味着用户信用良好,通过申请并被授予了一定的信用卡额度。在我们的系统中,这在多数情况下也是一个系统实时判断的过程。
· 激活(activation):用户在授信并且收到邮寄的信用卡之后,可以激活信用卡并使用。是否激活的标签通常比较难获得,因为信用卡邮寄需要一定的时间,而且用户主动去激活也需要一定的表现期,所以这里类别不平衡更为严重。在这里,我们通常看用户是否会在核卡后14天内激活信用卡。
以上的转化步骤有序列依赖,这意味着只有前一个步骤发生了,后一个步骤才可能发生。基于这个约束,用户只可能有5个不同的转化阶段如下图所示。
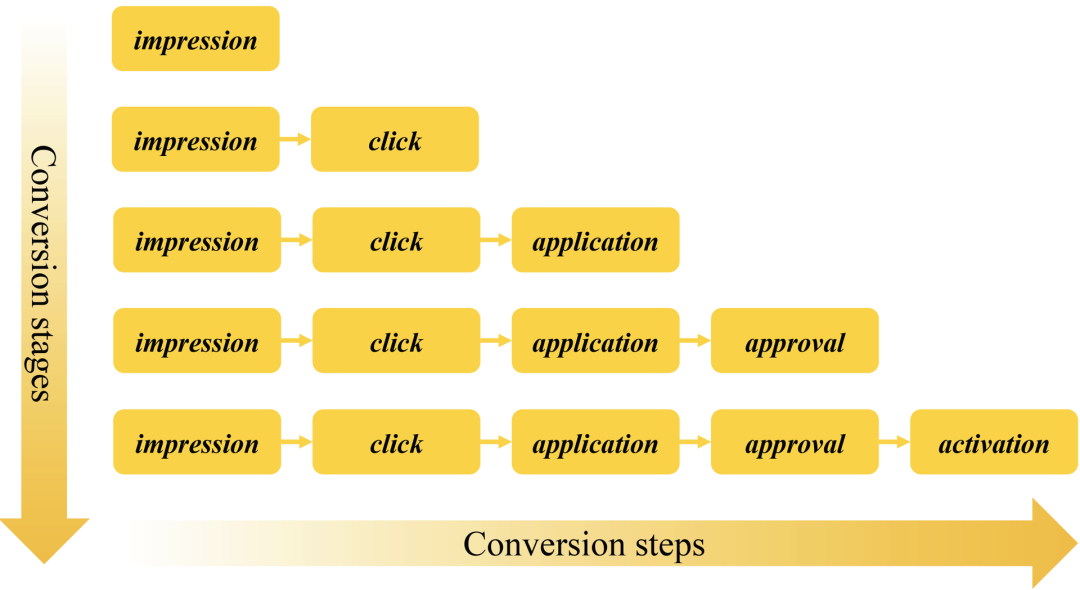
图1 5个不同的转化阶段
在工业界和学术界,多任务学习是一个提高端到端获客转化率的典型解决方案。近年来,在多任务学习中建模任务间关系的研究取得了很大的进展。我们将这些主要研究分为两大类:
1.控制多任务模型底部的专家模块如何在任务间参数共享[1, 2, 3],顶部的多塔模块分别处理每个任务,正如图3(a)所示,我们称这一类为专家底(Expert-Bottom) 模式。然而,专家底模式只能在任务间传递浅层表示,但在靠近输出层的网络中往往包含更丰富、更有用的表示[4, 5],这已被证明能带来更多的增益[6]。另外,由于专家底模式不是专门为具有序列依赖的任务设计的,因此这些具有专家底模式的模型不能显式地对序列依赖进行建模。
2.在不同任务的输出层中迁移概率[7, 8, 9, 10],如图3(b)所示,我们称之为概率迁移(Probability-Transfer) 模式。概率迁移模式只能通过标量乘积传递简单的概率信息,而忽略了向量空间中更丰富、更有用的表示,导致了信息的损失。如果其中任何一个概率没有被准确预测,多个任务将会受到影响。
本文针对序列依赖任务,提出了一种自适应信息迁移多任务(Adaptive Information Transfer Multi-task, AITM) 框架,该框架通过自适应信息迁移(AIT)模块对用户多步转化之间的序列依赖进行建模。AIT模块可以自适应地学习在不同的转化阶段需要迁移什么和迁移多少信息。此外,通过在损失函数中加入行为期望校准器,AITM框架可以更准确地识别端到端转化。该框架被部署在美团APP中,利用它来为对美团联名卡有高转化率的用户实时展示联名卡广告。
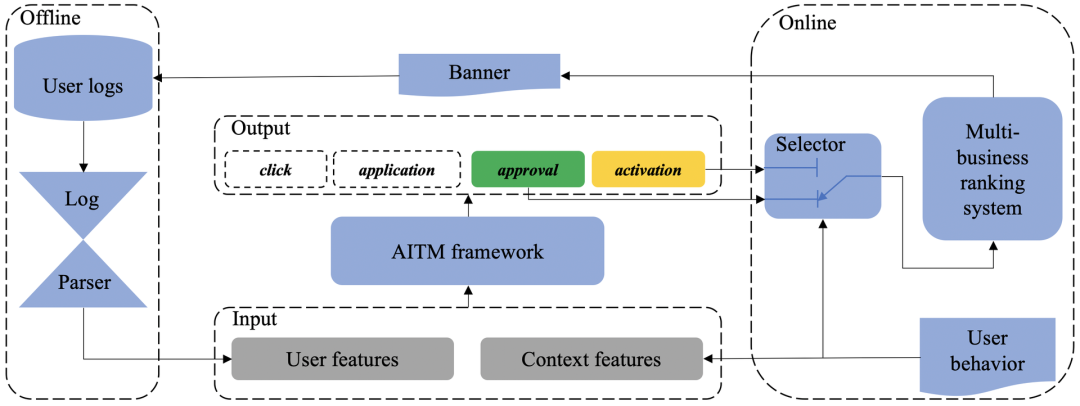
图2 美团App中的多任务排序系统
上图给出了一个多任务排序系统示意图。在我们的信用卡业务中,除了被动的曝光步骤外,我们建模了四个任务。其中,核卡、激活是主要任务,点击、申请是辅助任务。这是因为如果用户只完成了点击和申请步骤,而核卡步骤还没有完成,那么就不是一次有效转化,就会造成资源的浪费(例如计算和流量资源)。因此,我们主要关注最后两个端到端的转化任务,即曝光->核卡和曝光->激活。由于后两个任务的正样本数较少,且激活是延迟反馈的,而前两个辅助任务的正样本数较多,因此可以通过前两个任务来缓解后两个任务的类别不平衡问题。
另外,美团联名信用卡是与不同的银行合作发行的,不同的银行处于不同的业务发展阶段,因此对核卡和激活有不同的要求。信用卡业务刚刚起步的银行往往希望发行更多的信用卡以迅速占领市场,而发展成熟的银行则希望提高激活率以实现快速盈利。因此,我们的系统中有一个选择器,可以为不同的银行输出不同的转化目标,多任务框架可以很好地处理不同的业务需求。
此外,由于美团不同的业务都需要流量来为各自业务获客,而且不同用户对不同业务的兴趣也不同,所以不能简单地将流量划分给不同的业务。我们需要一个多业务排序机制来分配流量从而最大化整体的利益。
四、模型介绍
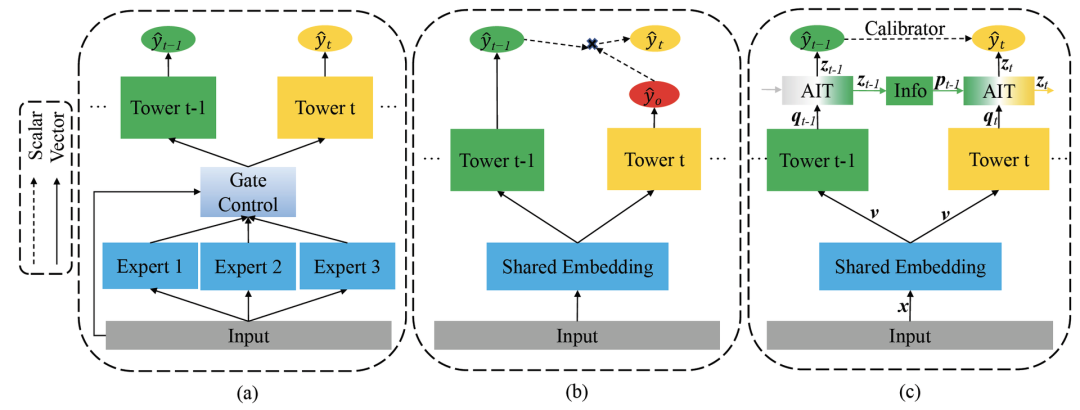
图3:(a)专家底模式(b)概率迁移模式(c)AITM框架。
上图(c)中展示了我们提出的AITM框架。该框架利用AIT模块来建模用户多步转化过程中的序列依赖。这个模型图显示了两个相邻的任务: t-1 和 t。
首先,输入特征 经过任务共享的Embedding分别输出到多个Tower网络中。通过共享Embedding模块,一方面可以用前边任务的丰富的正样本信息来学习Embedding表示,从而缓解后续任务的类别不平衡问题,另一方面可以减少模型参数。Tower网络可以根据自己需要定制,这里我们只使用了简单的MLP。然后,AIT模块利用当前任务Tower输出的向量 以及前一个任务传来的信息 来学习任务间如何融合信息。AIT模块如下定义:
,
.
,
其中, 是自动学习的迁移信息的权重。, , 利用前馈神经网络将输入投影到新的向量空间。
最后,我们通过在损失函数中施加校准器来约束概率的输出尽量满足序列依赖。损失函数是交叉熵+校准器约束,其中 定义了校准器约束强度:
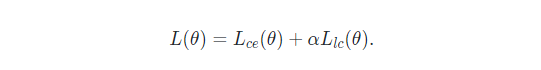
具体地,交叉熵定义如下:
校准器约束定义如下:
如果 大于 ,校准器将输出一个正的惩罚项,否则输出0。
五、实验分析
在本节中,我们将在工业和公开现实数据集上进行实验,对比各种基线模型来评估我们提出的AITM框架。接下来,首先会介绍使用的数据集,然后是离线和在线实验结果,最后是进一步的实验分析(包括消融实验、超参数实验和Case Study)。
5.1 数据集
我们使用两个数据集进行了离线实验。工业数据集是美团联名卡广告曝光的所有样本,我们取了一段时间的样本。该数据集有4个任务,分别是点击、申请、核卡、激活。在我们的业务中,我们只关注核卡和激活的转化指标,这两步转化才是有效转化。公开数据集是使用的阿里的点击转化预估数据集[9, 11],这个数据集有点击、购买两个任务。

表1:数据集统计信息。其中,“%Positive”代表采样后训练集中每个任务的正样本占比
5.2 离线、在线实验
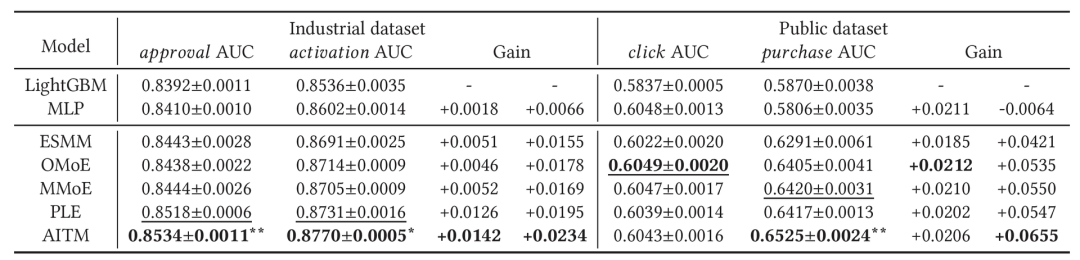
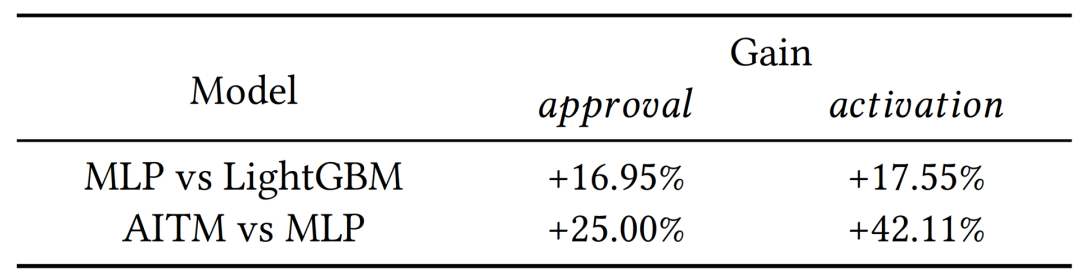
我们进行了离线和在线实验。随着业务发展,我们先后部署了LightGBM、MLP和AITM 3个模型到线上。离线和在线实验都证明了AITM的显著表现。
5.3 消融实验
我们设计了AIT模块来建模用户多步转化过程中的序列依赖,为了证明AIT模块的有效性,我们对AIT模块进行了消融研究。我们先分别随机取了500个激活正、负样本,然后对它们的激活任务预测分进行排序。越TOP 的预测分,表明模型预测这些用户越容易激活联名卡。然后我们利用t-SNE在激活任务上画出了原始信息 ,迁移+原始信息 ,以及AIT模块学习到的信息 的二维图。
从下图中,我们可以看到当用户激活比较容易预测时(即激活分TOP0%-TOP50%),三个模块都能够较好地区分正负样本。但是,当用户激活比较难预测时(即激活分TOP50%-TOP100%),原始信息 、迁移+原始信息 +都不能很好地区分正负样本,而AIT模块在TOP50%-TOP100%预测分上显著优于其他两个部分,说明了AIT模块的有效性。
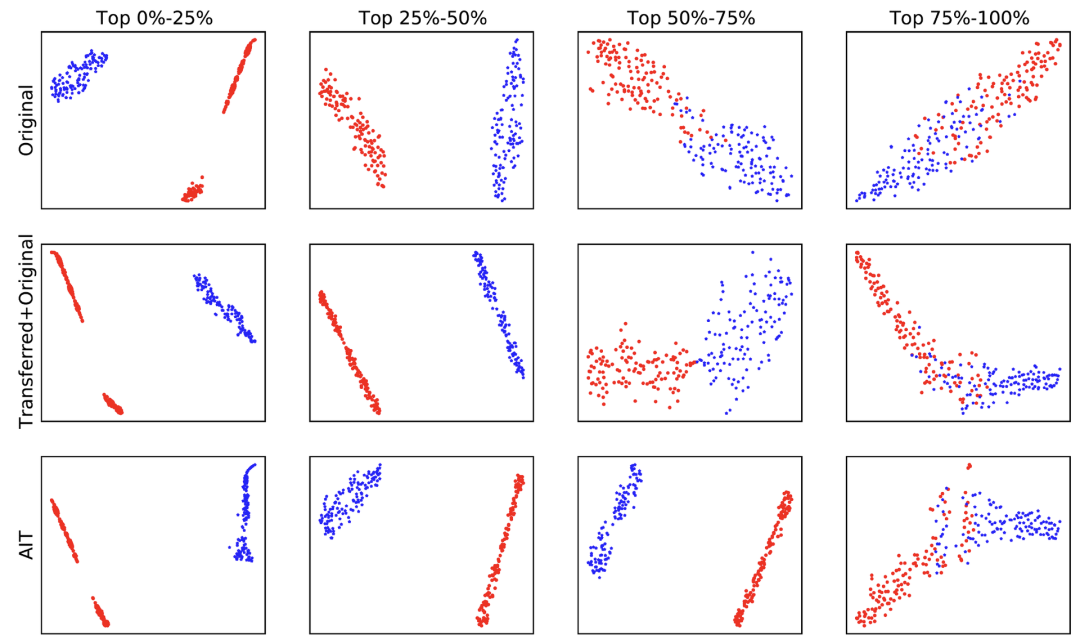
图4:AIT中不同模块的t-SNE可视化
5.4 超参数实验
另外,为了研究AITM框架的稳定性以及对超参数的依赖,我们进行了超参数研究。我们通过对Embedding向量维度、校准器强度、正样本比例、任务数量取不同的值进行多次实验,有以下发现:
· 前两个超参数实验表明,AITM模块在Embedding向量维度、校准器强度这些超参数下都表现比较稳定。
· 第三个超参数实验表明合适的下采样比例是缓解类别不平衡的一个重要举措。
· 最后一个图显示了更多的任务可以带来更多有用的信息,从而进一步提升端到端转化率。
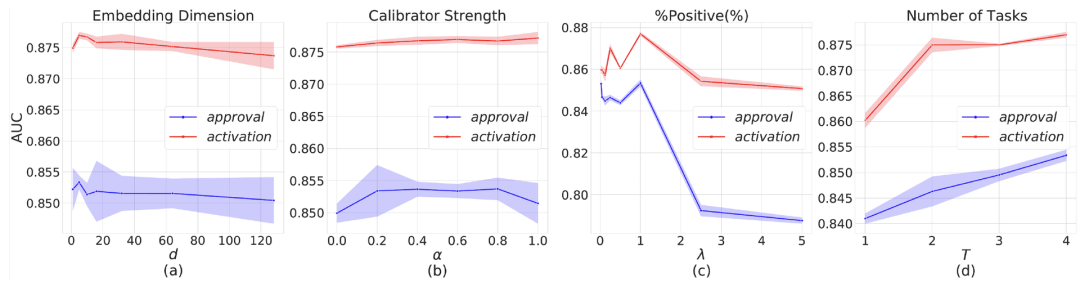
图5:不同超参数设置下的平均AUC表现,阴影代表多次实验的标准差
5.5 Case Study
最后,为了理解AIT模块在不同的阶段迁移了什么信息以及多少信息,我们进行了case study。下图中Wu 是迁移信息的权重。我们先随机采样4万个测试样本,然后将它们按照相邻两个任务的label分成3组:00/10/11 (分别对应图中红色、蓝色、绿色的线),并且在每个组中根据logloss对TOP500 个样本进行排序,越TOP 的样本表示预测越准。
· 首先,看红色的线,由于存在序列依赖,当前一个任务label是0时,后一个任务label也只能是0。所以我们看到前一个任务迁移了很强的信息给后一个任务(权重几乎为1)。
· 然后,看蓝色和绿色的线,当前一个任务label是1时,后一个任务label是不确定的。随着logloss的增加,迁移信息的权重会逐渐增大,这表明后一个任务的预测结果可能会被前一个任务所误导。
· 另外,看绿色的线,当后一个任务label是1时,前一个任务迁移了很少的信息(权重很小),这表明后一个任务主要根据自己任务本身来识别正样本。
· 从以上的结果中,我们可以看到AIT模块能学习到两个相邻的任务间应该迁移多少信息。
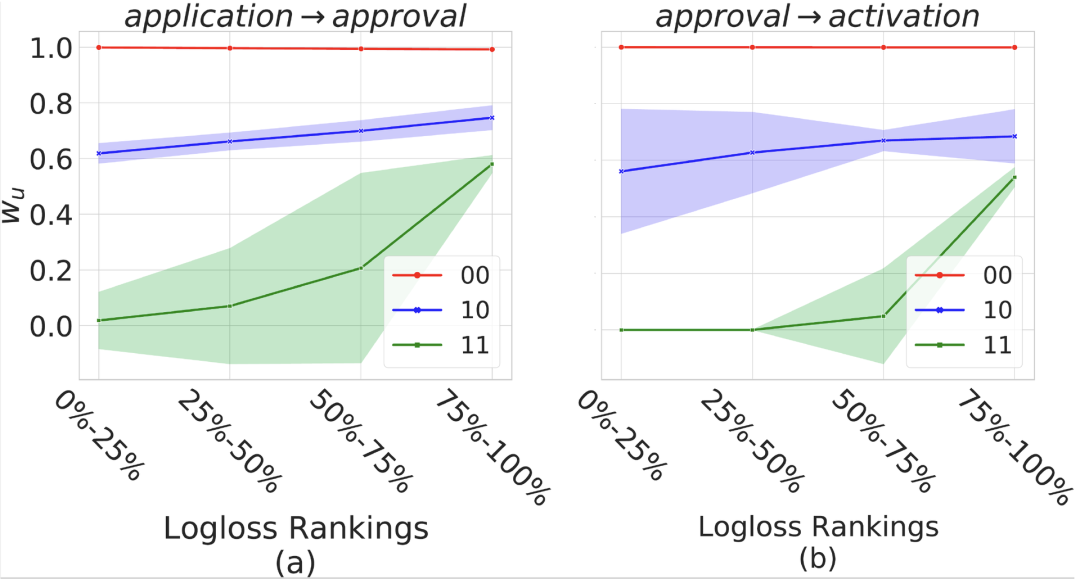
图6:不同转化阶段的迁移信息平均权重,阴影代表标准差
六、总结
[1] Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In KDD. 1930–1939.
[2] Zhen Qin, Yicheng Cheng, Zhe Zhao, Zhe Chen, Donald Metzler, and Jingzheng Qin. 2020. Multitask Mixture of Sequential Experts for User Activity Streams. In KDD. 3083–3091.
[3] Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. In RecSys. 269–278.
[4] Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, and John E Hopcroft. 2016. Convergent Learning: Do different neural networks learn the same representations? In ICLR.
[5] Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolutional networks. In ECCV. 818–833.
[6] Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. 2014. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474 (2014).
[7] Chen Gao, Xiangnan He, Dahua Gan, Xiangning Chen, Fuli Feng, Yong Li, Tat-Seng Chua, and Depeng Jin. 2019. Neural multi-task recommendation from multi-behavior data. In ICDE. 1554–1557.
[8] Chen Gao, Xiangnan He, Danhua Gan, Xiangning Chen, Fuli Feng, Yong Li, Tat-Seng Chua, Lina Yao, Yang Song, and Depeng Jin. 2019. Learning to Recommend with Multiple Cascading Behaviors. TKDE (2019).
[9] Xiao Ma, Liqin Zhao, Guan Huang, ZhiWang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. In SIGIR. 1137–1140.
[10] Hong Wen, Jing Zhang, Yuan Wang, Fuyu Lv, Wentian Bao, Quan Lin, and Keping Yang. 2020. Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction. In SIGIR. 2377–2386.
[11] https://tianchi.aliyun.com/datalab/dataSet.html?dataId=408
Illustration by Dmitry Nikulnikov from Ouch!
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

> 投稿请添加工作人员微信!

扫码观看!
本周上新!

▼
