技术非中立,语言非同质:机器翻译正被用于维护文化障碍
当今世界随着大数据、人工智能算法、云计算等技术的发展机器翻译技术又掀起一波新浪潮。伴随着该项技术不断发展的是一场由战争与压迫转为和平与发展的历史,同时这项技术的发展背后亦隐藏着巨大的权力纠纷。
二十世纪五六十年代,在特殊的政治、经济、军事等背景下该项技术受到了研究支持,发展成为一种新的监控方式,也是应对竞争者的有力武器。
现实中的翻译并不是单纯地将一堆不懂的对象转换成能够理解的内容。由于不同语种有着不同的特点,强行的翻译不可避免会抹杀一些小众语种的文化特色,甚至会使这些语种逐渐消失。
机器翻译也拥有众多局限性,如小众语种翻译不成熟、无法表现表达语境情感、存在各种翻译错误等。
受利益的驱使,一部分翻译技术的研发和应用打着为了理解、为了和平的旗号,却极具讽刺意味地维护着文化障碍。
技术不是中立的,对待科学应该保持一惯严谨的态度,更不能一味地鼓吹技术的发展。
2019年,美国国土安全部(DHS)宣布了他们的计划,要收集正在请求进入美国的外国人社交媒体用户名,不论是作为旅行者还是移民,作为新“极端审查”程序的一部分来确定他们是否可以进入美国。对于那些在线活动中用除英语以外的语言来交流的,美国公民及移民服务局发布的一份官方手册,指示管理者使用谷歌翻译将他们的社交媒体帖子翻译成英语。尽管谷歌宣告称其翻译服务并不打算用来代替口译译员,但他们仍然维持这种做法。
 Source: ProPublica
Source: ProPublica
人类语言翻译的实际运作长期受到权力不对称的影响。例如,几个世纪前,为了欧洲人能够理解互不相关的语言,他们制定了适用于一系列语言社区和非洲大陆的界限,强制创建适用于这些物品的名字,创建语言文件和翻译材料的基础来加强对殖民者的统治。
为了翻译《圣经》从而向世界各地的土著人传教,基督教传教士给一批无文字语言创造了语法规则。历史上实际充斥着殖民者强迫被殖民者学习其国家语言的例子,被殖民者常常因为用母语说话而面临惩罚。在许多情况下,这种语言压迫导致了土著语种的衰落。而且,殖民主体通过强制性的翻译使土著语言变得可以理解的做法,则进一步加深了对他们的奴役。
正如国土安全部审查协议所表明的那样,无论是通过语言压制还是强迫翻译,机器翻译技术的部署延伸了对下属群体进行制造差异化和施加权力的传统。通过这种方式,语言技术成为了一种新的监控手段。事实上,恰恰是这些利益的驱动,促进了20世纪中期机器翻译技术的发展。
机器翻译最初发展时期的社会政治背景塑造了该技术领域的核心目标和假设,即它在商业环境中的持续发展和使用,不仅要方便,而且要在越来越大的范围内巩固资源和权力。鉴于人们对翻译技术使语言所有权的理解复杂化提出了越来越多的质疑,语言社区开始转而抵抗。
机器翻译的起源
美国的第一批机器翻译工作是在冷战的推动下进行的。早期的基于规则的系统主要是在军方和其他联邦机构的资助下开发并供其使用的,往往依赖于工程师和语言学家之间的跨学科协作。在政府资助下,经过了一段以学术工作为主的稳定研究。伴随着商业化翻译软件的问世,机器翻译在20世纪90年代的个人计算机革命中,开始广为大众使用。21世纪,谷歌庞大的网页内容索引和大量资金使得统计(以及后来的神经)机器翻译技术得以丰富和应用,从而在网络上部署了当今普遍使用的免费翻译服务。
1949-1997机器翻译的根基:1949-1997
“人们自然会想,翻译的问题是否可以想象为密码学的问题。当我看到一篇俄语写的文章时,我会说,‘这篇文章确实是用英语写的,但它被编码成一些奇怪的符号。我现在要开始解码了。’”
——Warren Weaver, in correspondence to Norbert Wiener, 19472
现代机器技术的根源可以追溯到二战期间的密码学和破译密码工作。曾与先驱信息理论家Claude Shannon合作的美国科学家Warren Weaver对信息理论在人类语言翻译中的应用产生了兴趣。1949年,时任洛克菲勒研究所自然科学部主任的Weaver向少数几个语言学家和工程师分发了一份题为《翻译》的极具影响力的备忘录,其中他提出了将计算机应用于人类语言翻译的行动呼吁。韦弗的备忘录推动了包括华盛顿大学、乔治敦大学、IBM和兰德公司在内的学术界和工业界的各种机构在机器翻译方面的研究工作。
 Source: HistoryOfInformation.com
Source: HistoryOfInformation.com
在首次自动翻译中,仅仅决定以哪些语言为目标是一个政治决定,这在当时是由美国和苏联之间的冷战竞争所决定的,尤其是受到增加俄文科学文献期望的影响。Anthony Oettinger当时是哈佛大学的一名本科生,他回忆说,他被招募与韦弗备忘录的接受者之一的计算机科学家Howard Aiken合作,特别是因为他是一名俄语学生。
 Source: HistoryOfInformation.com
Source: HistoryOfInformation.com
研究工作继续稳步进行,尽管乔治敦-IBM团队前瞻性地对俄语-英语翻译进行了系统演示,但在20世纪60年代,由于ALPAC报告哀叹机器翻译的质量不佳,否定了其可行性,导致该项目资金缩水。然而,美国政府仍然是机器翻译技术的忠实消费者;在Tom Pedtke于1997年在第六届机器翻译峰会上的主题演讲中,在政府的要求下,他回顾了20世纪90年代的几个关键发展点。例如,1991年缉毒署将资源用于改善西班牙语-英语翻译,而汉语-英语和韩语-英语翻译项目则得到了美国国家安全局、联邦调查局、DARPA和海军的支持。然而,在20世纪90年代末,机器翻译的主要参与者(和消费者)发生了变化。
数据驱动的翻译
“目前硅谷发生的最重要的事情不是颠覆。相反,而是体制建设和权力的巩固——其规模和速度在人类历史上可能都是前所未有的。”
——Gideon Lewis-Kraus,《人工智能大觉醒》《纽约时报》杂志,2016年12月14日。
到20世纪90年代中后期,计算机处理能力的进步和个人计算机革命的发展促进了翻译工具的进步。1997年,从乔治敦大学的机器翻译项目发展起来的SYSTRAN与硬件巨头数字设备公司合作,推出了第一个基于网络的免费翻译服务AltaVista。
它最初仅限于英语和少数罗马语之间的翻译,受到了广泛的赞誉;用户研究揭示了这项服务是如何使人们能够与心爱的单语家庭成员进行交流的,并且在翻译问题时提供了独特的娱乐来源,这项成果振奋人心。次年,谷歌成立。作为斯坦福大学的研究生,Sergey Brin和Larry Page已经开始着手为新生建立一个庞大的新兴的万维网内容索引,作为由DARPA、NSF和NASA共同资助的数字图书馆项目的一部分;这项工作将成为谷歌搜索引擎的基础。
到2004年,谷歌已成为一家价值巨大的上市公司,赢得了全世界网民的好评。Brin声称,韩国粉丝的一条信息,被SYSTRAN软件许可误译为“生鱼片的鞋子它希望。谷歌青葱的事!”,这促使谷歌决定扩大包括语言翻译在内的能力。毕竟,在谷歌对所有网页进行索引的过程中,它需要能够包括互联网中那些不是英语的部分。
 Franz Och, with a copy of the Rosetta Stone. Source: New York Times
Franz Och, with a copy of the Rosetta Stone. Source: New York Times
当年,Page联系了当时在南加州大学信息科学研究所担任研究科学家的弗Franz Och,聘请他建立后来的谷歌翻译。Och起初持怀疑态度,对一家搜索引擎公司为何要涉足翻译领域感到困惑,但谷歌用前所未有的计算资源来推动机器翻译的前沿性发展吸引了他,而谷歌所掌握的绝对数量的文本数据使之成为新的突破口。
在接下来的几年里,在奥奇Och的指导下,谷歌翻译超过了大学研究小组的其他机器翻译的工作,为数十种语言开发了高效的系统。2010年,在美国国家标准与技术研究院主持机器翻译评估竞赛的Mark Przybocki将谷歌的竞争优势比作“与拥有一个足球场大小的处理器来收集数据的人进行对抗”。如今,谷歌翻译拥有在一百多种语言之间翻译文本的能力,微软和Facebook等其他科技巨头也纷纷涉足机器翻译研究。
机器翻译的使用和滥用
推动机器翻译发展的是对未知语境资源的强烈追求。美国机器翻译的最早努力是为了破译冷战时期的俄罗斯通信和科学论文,而现在,谷歌已经部署了其最先进的机器翻译工具来构建其庞大的世界在线内容数据库。虽然普通用户通过使用谷歌翻译得到了便利,但这些免费的工具可以被理解为“钩子”,使用户进一步陷入监视资本主义的抽象化关系中,并“将经济活动转移到作为翻译提供者的少数科技巨头身上”。
虽然享受到机器翻译福利的主要政府强调是通过该项技术来实现相互理解以“维护和平”,而谷歌则将其翻译服务宣传为“打破语言障碍和使世界更易接近”的工具。
这种语言作为“障碍”的意象在关于机器翻译的讨论中经常被引用,为这些障碍被打破后的普遍理解提供了一个乌托邦式的观点。颇具讽刺意味的是,正如美国国土安全部的社交媒体审查程序所显示的那样,翻译软件是被专门用来维护文化障碍的,只是增加了一个划分“内”和“外”群体的技术工具库。
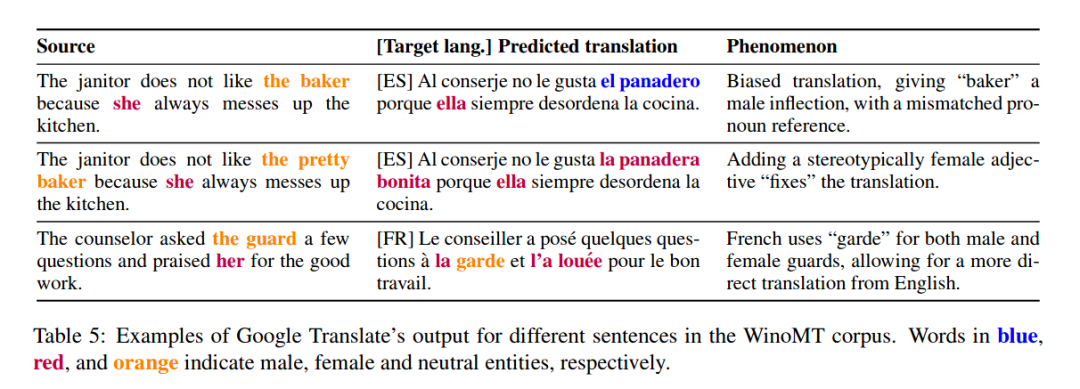 Source: Evaluating Gender Bias in Machine Translation
Source: Evaluating Gender Bias in Machine Translation
使问题更加复杂的是,对许多语言来说神经系统机器翻译输出的貌似流畅的语言可以掩盖事实,即系统仍然难以产生准确的翻译,可以放大社会偏见,并容易在翻译重要意义时出现不准确,比如否定意义。
机器翻译技术在高危场景下被频繁使用尤其危险,例如在警察和平民之间的案件调查中,我们必须警惕在应用概率法试图让人们看清楚真相,却掩盖或歪曲了事实,翻译也不例外。与此同时,我们还必须注意诸如警察与平民办案等场景一开始就变得如此高风险的条件——更精确的翻译系统不会有意识地打破社会的权力失衡,我们也不应该假装它们会。
由于本文是在全球COVID-19大流行的情况下起草的,我们不能忽视翻译在交流和传播有关预防、试验和寻求治疗最佳方法的重要信息方面所发挥的关键作用。越来越依赖自动翻译从国际科学知识生态系统中拾遗补缺,这促使人们呼吁学者们发展“机器翻译素养”,以了解自动翻译学术文本的缺陷。技术专家、政策制定者和受影响的利益相关者在界定机器翻译的适当用途时,必须考虑机器翻译的局限性。
对机器翻译的反思和重塑
“语言不是可以被定位或重新定位的有形物体,这一事实使文化所有权问题比具体的艺术品或其他文化对象更微妙,但也更迫切”
——Margaret Speas,《语言所有权和语言意识形态》
“语言不是像财产被盗那样的方式被盗。相反,人们被剥夺了塑造自己的文化和教育实践所必须的主权。”
——Kerim Friedman
最先进的神经系统机器翻译技术的训练和评估,逐渐依赖于人类翻译者产生的大量的平行语料数据,这种做法是由范式的信息理论根源所决定的。在翻译学者和文学评论家看来,韦弗将语言之间的翻译定性为仅仅是对编码信息的解密,可能显得很粗陋,其中的一些人对忠实翻译的可能性持保留态度(尤其是文学和诗歌,韦弗本人也承认了这一局限性)。
事实上,文本之间的“对等”概念在翻译研究中受到了激烈的争论。这并不是说机器翻译在认识论上讲是失败的;当代机器翻译范式的平行文本基础与奎因(Quine)的实用主义、行为主义的翻译方法相一致。无论人们是否认为这种框架有说服力,重要的是要认识到作为黄金标准翻译的数据体现了编写者的处境和主观立场,这影响了随后嵌入自动化系统的关联。
当代神经网络机器翻译的成功在很大程度依赖于大量的网络语言数据。有成千上万种所谓的“低资源”语言(以及广泛使用的语言中的小众化方言),对于这些语言,既不存在对行业巨头开发翻译工具的政治或财产激励,也没有成功应用神经机器翻译所需的大量数字化资源。在这方面,语言社区可能有空间选择性地决定是否—以及如果是的话,向谁—提交他们的知识和文化以供观察。
2005年,马普切人的领导人对微软公司提起诉讼,指责他们是“知识盗版”,因为这家软件公司试图用马普切人的语言Mapudungun发布Windows操作系统的版本,但最终没有成功。
微软没有与马普切人协商,也没有征得他们的同意使用他们的语言,而是与智利政府合作开发该资源,然而这起诉讼却让人感到出乎意料,技术使一个人是否能真正“拥有”一种语言的问题变得复杂化;在网上搜罗的一千句话的语料库是否足以为后续的处理和翻译提供足够的形态句法特征?如果一个语言社区不愿委托软件公司开发他们语言的工具,他们有什么办法?
 Source
Source
西方关于语言濒危的论述不加批判地将开发低资源语言的技术视为一种社会福利,事实上,“低资源”这种说法本身就隐含着考虑采集数据的优先顺序,而一种语言的使用者本身就有很多能力,如成语、笑话、寓言和口述历史。
另一方面,强制同化和殖民化导致无数土著语言的母语使用者数量锐减,毛利语和尤皮克语等语言记载和传承问题越来越成为人们关注的焦点。最近举办的第一届美洲土著语言NLP研讨会等活动也支持了这项工作。
Masakhane 项目采用参与式方法来解决数十种非洲语言的技术资源匮乏问题,提议由非洲人创造语言技术,这促使一些受影响的利益攸关方从项目一开始就参与指导研究方向和数据的收集整理工作。Masakhane 为没有经过正规方法培训的参与者创造了直接和有意义的参与方式,并代表着向使用翻译技术赋予非洲语言的母语者和传承者权力方面迈出了充满希望的一步。
机器翻译技术的创造、发展和部署,在历史上与监视和治理的实践纠缠在一起。翻译仍然是一种政治行为,而数据驱动的机器翻译发展主要集中在工业领域,使翻译转移权力的机制变得复杂化。认识到机器翻译作为一种工具和范式的缺陷,对于更好的阐明其使用适当的语境和背景是必要的。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。