ICCV 2021 | GLiT:一种更适合图像任务的transformer网络结构

作者单位:悉尼大学,商汤科技,百度美国研究院,牛津大学
论文链接:https://arxiv.org/pdf/2107.02960.pdf
代码链接:https://github.com/bychen515/GLiT
1分钟视频讲解:https://www.bilibili.com/video/BV1BU4y1E7zx/
5分钟视频讲解:https://www.bilibili.com/video/BV1nP4y1s7UK/
10分钟视频讲解:https://www.bilibili.com/video/BV1XL4y1e7Ri/

方法亮点
1.本文是与ICCV相关文章同时出现的第一批通过网络结构搜索算法来进行vision transformer网络结构探索的算法。通过网络结构搜索,得到了在相同训练设置下优于ResNet和ResNext的vision transformer变种。
2.将局部模块引入至vision transformer的搜索空间中,提升了网络针对计算机视觉任务中至关重要的局部信息建模的能力。
3.针对引入局部模块后巨大的搜索空间,提出了简单而有效的分层级的网络结构搜索算法,有效地提升了搜索结果。
下面将从论文动机,方法细节和实验结果三分方面对该方法做一个简单的介绍。
一、论文动机
Vision transformer如ViT[1], DeiT[2]是近两年最受关注的计算机视觉网络结构之一。Vision transformer的好处是可以通过self-attention建模全局图像信息。而在近几十年的CV领域中,最常用的CNN最大的特点之一可以看作是共享的局部信息建模(local)。本文希望将局部信息引入至vision transformer中,并探索如何自动学习二者在网络中的分配比例。同时,本文也将自动学习配置Transformer中其他模块的算力配比,比如卷积核大小和每个子模块的通道数。
二、方法细节
1. Transformer中局部信息引入
卷积层(convolutional layers)是一个简单且高效引入局部信息的方法。本文通过将self-attention中某些head替换为卷积层的形式来引入局部信息。
传统的Transformer: 以multi-head数目为3的Tiny模型举例,图1左边展示的是传统的Transformer结构,一个网络由M个模块(Block)组成,在Transformer中用的都是全局注意力,所以我们称这些模块为全局模块(Global Block,简称G-Block)。每个G-Block由self-attention模块(红色框,一般使用multi-head的形式,在图中,head的数量为3,即G=3)和前向传播网络(FFN,由几个全连接层组成)两个模块构成。
引入局部信息的Transformer: 我们将G-Block中multi-head中的部分head替换为卷积层来引入局部信息。如图1右边中蓝框所示。在图1的例子中,3个head中的两个被替换为卷积层。替换后,原来的G-Block就变成了全局-局部模块(Global-Local Block, GL-Block),而我们最后的网络GLiT便是由一些GL-Block构成的。
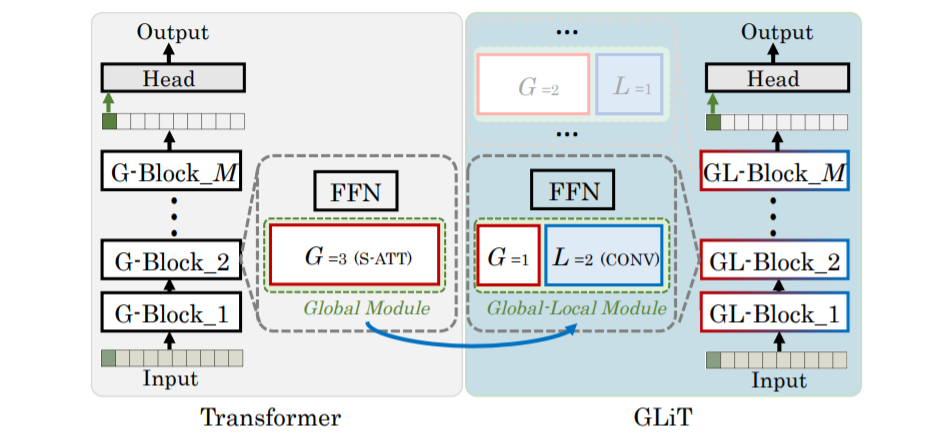 图1 全局及局部注意力模块
图1 全局及局部注意力模块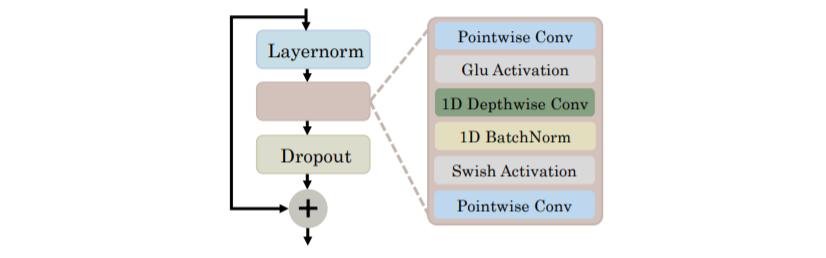
图2 1D 局部注意力机制模块
对于使用卷积建模局部信息的局部模块,也就是上图中蓝框所示的部分,我们采用了Conformer[3]中的模块,具体结构如图2所示。
2. 基于全局及局部的分层NAS方法
局部信息的引入是重要的。然而接下来的问题是:每个模块引入多少全局/局部信息? 手工设计并验证最优解这一过程对于计算的要求过大,因此本文利用网络结构自动搜索(NAS)的方法(这里以SPOS [4]为基础)来解决这个问题。对于NAS,定义搜索空间和搜索方法是很重要的两个方面,以下将分别介绍。
· 搜索空间:
本文的搜索空间(针对Tiny模型)主要包括两个维度,一个是全局和局部信息在整个网络的分布(如表1第一行High-Level, 其中G,L分别代表一个GL-block中全局和局部模块的数量),另外一个是全局和局部模块里面的超参(表1中Low-Level,这部分跟大部分NAS方法关注的网络超参是类似的,包括了卷积层中卷积的大小K (即kernel size),expansion ration (E), self-attention中特征的维度 和FFN中全连接层的expansion ratio。
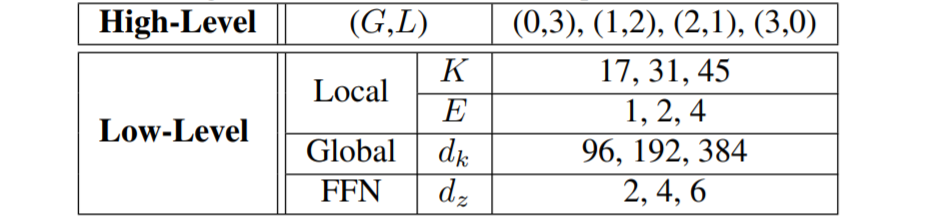
表1:全局局部Transformer 搜索空间
· 对于搜索方法:
假设我们的网络总共包含12个block,按照上述搜索空间,一共有
本文中我们采用分层搜索的方法的来解决这一问题。简单来说,分两步搜索:
1.先搜索全局和局部模块的分配(High-Level),
2.再搜索全局和局部模块的细节(Low-Level)。
这样就可以将原本大的搜索空间拆分成两个小的搜索空间,整个算法流程图如图3所示。在每一个小空间里,我们采用SPOS[4]的方法来搜索网络结构。

图3 分层搜索示意图
三、实验结果
1. ImageNet 上同其他CNN和Transformer的比较
DeiT是本文方法的基准模型(baseline)。表2中给出了利用本文算法得到的三个不同大小模型的性能,包括GLiT-Tiny, GLiT-Small和GLiT-Base。其中,GLiT-Tiny是搜索出来的模型,其他两个模型是按照DeiT中的方法对GLiT-Tiny模型进行比例放大之后得到的(如果重新搜索可以获得更好的结果)。从表2可以看到,我们的模型具有不错的性能表现,特别是Tiny模型,相比于baseline提高了4%。
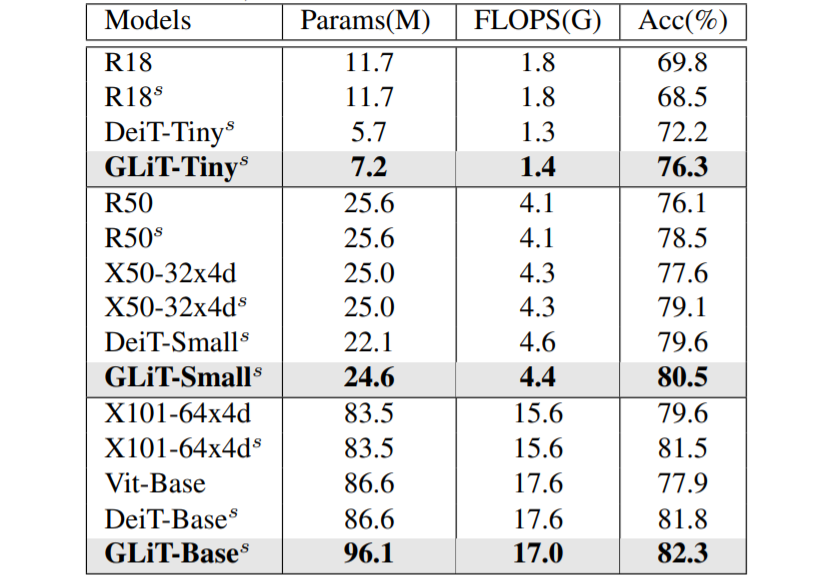
表2:ImageNet分类效果
2. 搜索空间
我们的对比实验验证了全局局部模块的分配和它们自身的结构超参对于模型性能的影响,如表3:可以看出如果只搜全局局部模块的分配(第二行),相比于基准模型(第一行)提高了超过3%,在此基础上搜索其他网络超参,进一步提升了约1%。证明两部分空间的搜索都是有效的。
同时,表3也验证了在不引入卷积时,只针对transformer的qkv维度与mlp ratio进行搜索,在这一搜索空间下(NLP-NAS),网络的性能只有1.2个点的提升,在不引入局部卷积信息时,针对transformer的搜索提升十分有限。证明本文将局部全局同时搜索是提高精度的最重要因素。
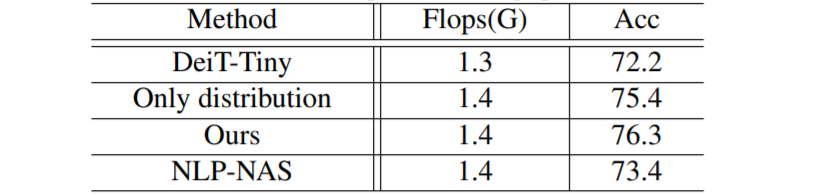
表3:不同模型性能对比
 表4: 不同搜索方法效果对比
表4: 不同搜索方法效果对比
3. 搜索方法
五、总结
本文在Vision Transformer的基础上引入了共享的局部信息建模,探索了基于全局与局部注意力的Vision Transformer网络结构,进而实现了更好的分类效果。本文构建了新的基于全局与局部注意力的网络搜索空间,并针对新构成的较大的搜索空间提出了分层级的网络搜索算法以有效地进行网络结构搜索。
[1] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[2] Touvron, Hugo, et al. “Training data-efficient image transformers & distillation through attention.” International Conference on Machine Learning. PMLR, 2021.
[3] Gulati A, Qin J, Chiu C C, et al. Conformer: Convolution-augmented transformer for speech recognition[J]. arXiv preprint arXiv:2005.08100, 2020.
[4] Guo, Zichao, et al. “Single path one-shot neural architecture search with uniform sampling.” European Conference on Computer Vision. Springer, Cham, 2020.
[5] Selvaraju R R, Cogswell M, Das A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE international conference on computer vision. 2017: 618-626.
[6] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” arXiv preprint arXiv:2103.14030 (2021).
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!

扫码观看!
本周上新!

关于我“门”
▼
