ICCV 2021 | 悉尼大学&京东探索研究院提出:融合邻近帧的全帧视频稳定方法OVS

论文地址:
https://arxiv.org/abs/2108.09041
代码链接:
https://github.com/Annbless/OVS_Stabilization


左:不稳定,中:DUT,右:OVS
为了缓解关键点估计不准确的影响,DUT利用运动的空间局部一致性来对不准确的关键点进行抑制,即对估计出的关键点和光流进行propagation来得到基于网格点的运动。这些基于网格点的运动形成的轨迹被进一步用于平滑来得到每个不稳定的轨迹和其对应的稳定轨迹,并计算出两个轨迹之间的偏移量。偏移量之后被用于估计不稳定视频帧到稳定视频帧之间的变换,并基于此对不稳定的视频帧进行warping,来得到最终的稳定视频。但是这样产生的视频是带有黑边的,这是因为某些需要用于warping的像素在当前帧是无法得到的。
举例来说,如果估计出的变换是当前的不稳定帧过于向下了,需要把它整体向上偏移10个像素,那么在稳定的视频的底部就会出现10个像素的黑边,这是由于这10个像素的内容没有办法在当前帧中找到。这也是目前所有基于warping的稳定方法产生黑边的原因。有没有什么办法来解决这个黑边问题呢?
三、方法原理
OVS的核心思想是通过邻近帧的信息去补全当前帧在防抖过程中缺失的信息,从而实现减小甚至无需裁剪的稳定效果。具体而言,OVS采取了先粗对齐再细对齐的方式(图(1))来对齐邻近帧和当前帧的信息。
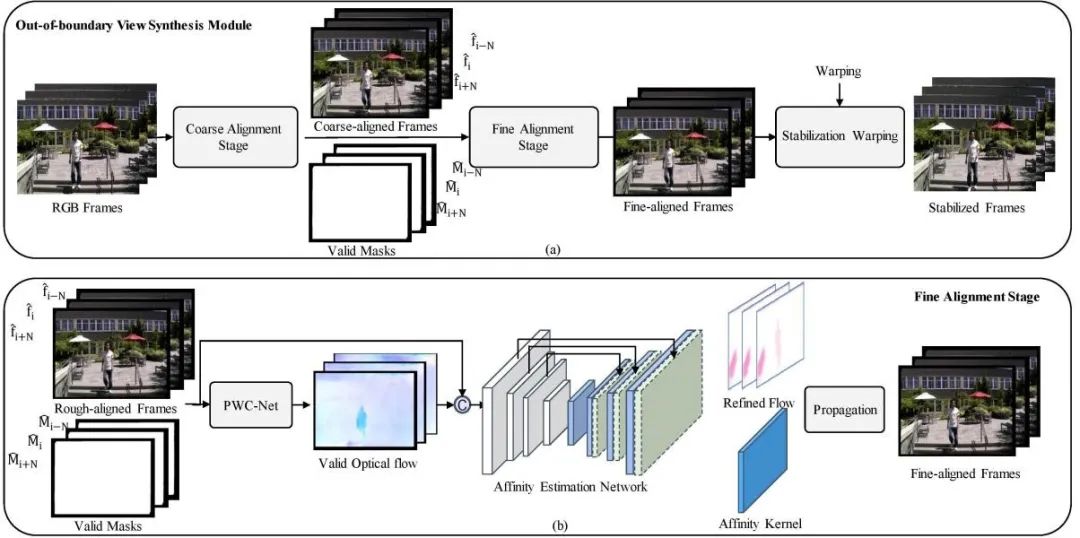
图1 OVS采用的对齐方式
这样一个两阶段对齐的方法比较好的减弱了由于抖动造成的帧和帧之间的距离较大对对齐造成的困难。在粗对齐的过程中,OVS采用了基于网格的单应性矩阵估计的方法,来将周围的帧的信息粗略的和当前帧对齐。通过粗对齐,邻近帧和当前帧之间的距离变得比较小,这为第二阶段的细对齐创造了比较好的条件。
在细对齐的过程中,OVS首先估计了粗对齐的邻近帧和当前帧之间的光流。需要注意的是,这一步光流估计仅仅在邻近帧和当前帧共享的区域中进行估计;对于只在邻近帧中出现的区域,即当前帧中缺失的而防抖过程中需要的区域,研究人员提出通过运动的一致性进行估计,即通过估计像素之间的affinity矩阵,将共享区域的运动估计逐渐传播到只在邻近帧出现的区域,如图(2)所示。

图2 通过运动的一致性对缺失区域进行估计
需要注意的是,OVS在训练中无需使用成对的稳定-不稳定的视频作为groundTruth,而只需要不稳定的视频即可完成训练。具体来说,OVS通过对原始视频进行crop产生网络的输入,并将crop之前的视频作为对齐的帧的最终结果,以此进行网络的训练。
四、实验结果
我们在常用的NUS数据集上验证了提出的OVS方法的有效性。如表(1)所示,将OVS添加到基于变换矩阵的视频稳定器DUT,MeshFlow,PWStabNet,StabNet等方法上后,这些方法都得到了比较好的性能提升,尤其是cropping方面带来了较大的提升。
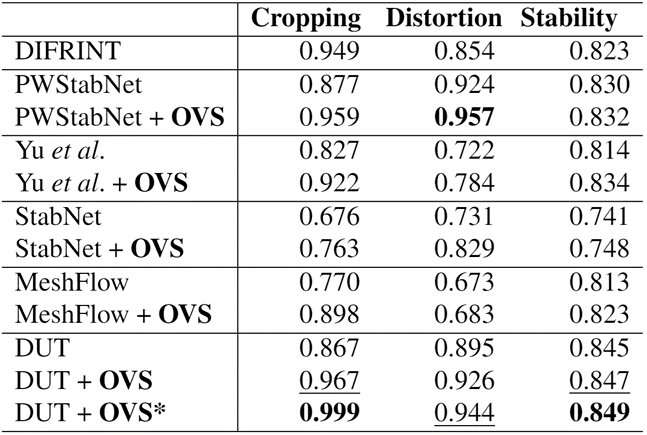
表(1)视频稳定器添加OVS后的性能表现
如图(3)所示,OVS在主观效果上也有比较大的提升。比起以往的全帧稳定方法DIFRINT,OVS取得了较小的失真和相当程度的内容保留(红圈表示出现了失真的地方)。
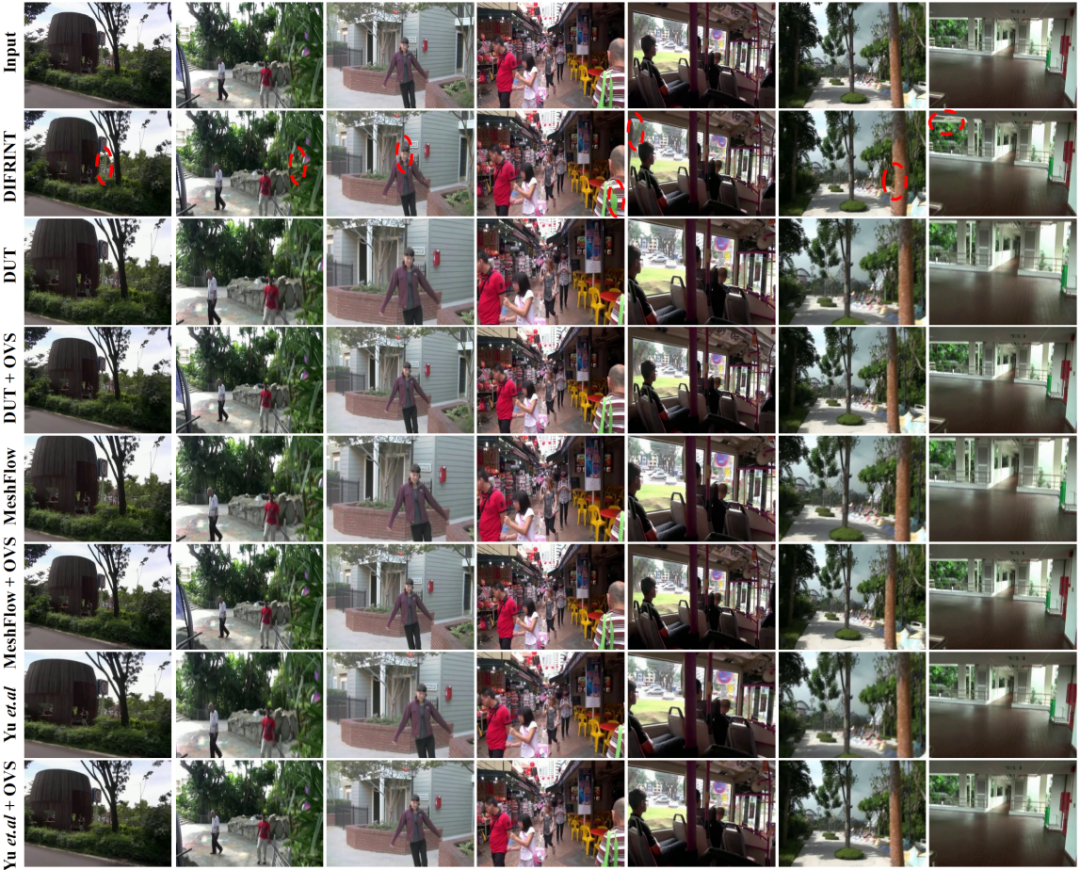
图3 添加OVS后的视频主观效果
此外,我们还针对使用邻近帧的数量进行了消融实验,以及对分别只使用粗对齐和细对齐阶段的效果进行了对比,如表(2)(3)所示,随着使用帧数的增多,稳定后的视频中保留的区域也在逐渐增多;同样,只使用粗对齐或者只使用细对齐也会造成最终稳定结果的下降。
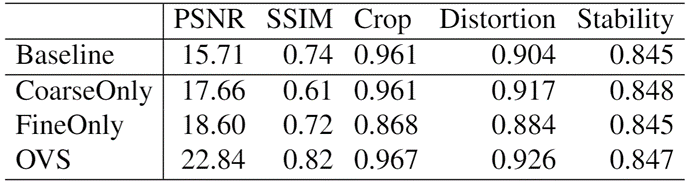
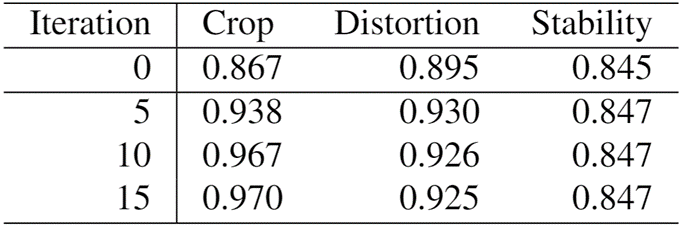
表(3)使用不同帧数的效果对比
五、总结

Illustrastion by Dmitry Nikulnikov from Icons8
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!

本周上新!


扫码观看!
关于我“门”
▼
