网络架构之争:三大主流架构对决,谁是王者?深入思考CNN、Transformer与MLP
以下文章来源于极市平台 ,作者CV开发者都爱看的
专注计算机视觉前沿资讯和技术干货,官网:www.cvmart.net

论文地址:
https://arxiv.org/abs/2108.13002

本文对这些深度神经网络架构进行实证研究并尝试理解他们的利与弊。为确保公平性,我们首先开发了一种称之为SPACH的统一架构,它采用独立的模块进行空域与通道处理。基于SPACH的实验表明:在适度规模下,所有架构可以取得相当的性能。然而,随着网络放大,他们表现出不同的行为。基于所得发现,我们采用卷积与Transformer提出了两个混合模块。所提Hybrid-MS-S+仅需63M参数量12.3GFLOPs即可取得83.9%top1精度,已有现有精心设计的模型具有相当的性能。
二、A Unified Experimental Framework
下图a给出了单阶段SPACH架构示意图,ViT与MLP-Mixer均采用了类似架构,该架构非常简单,主要包含多个Mixing模块与必要辅助模块(如块嵌入、GAP以及线性分类器)。下图b给出了Mixing模块结构示意图,Spatial Mixing与Channel Mixing顺序执行。SPACH的名称则源自Mixing的处理过程:SPAtial and CHannel processing。
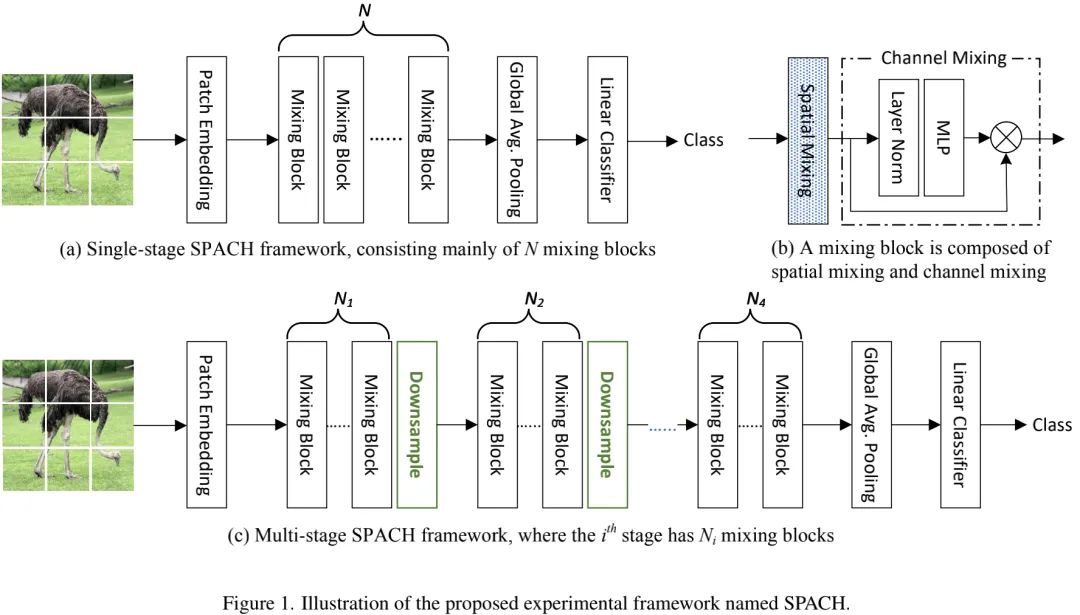
上图c则给出了多阶段SPACH(SPACH-MS)架构示意图。多阶段是CNN网络提升性能非常重要的机制。不同于单阶段SPACH(它对输入图像进行大尺度下采样后在进行处理),它在开始阶段保持高分辨率,然后逐渐下采样。具体来说,SPACH-MS包含四个阶段,下采样比例分别为,每个阶段包含个Mixing模块。由于Transformer与MLP在高分辨率特征上的高计算量,我们在第一阶段仅采用卷积;另外,阶段内部通道维度保持不变,每下采样一次通道数加倍。
表示输入图像,SPACH首先通过块嵌入层变换为(注:p表示块尺寸,在单阶段中为16,在多阶段中为4)。经过多个Mixing模块处理后,在尾部街上分类头进行分类。
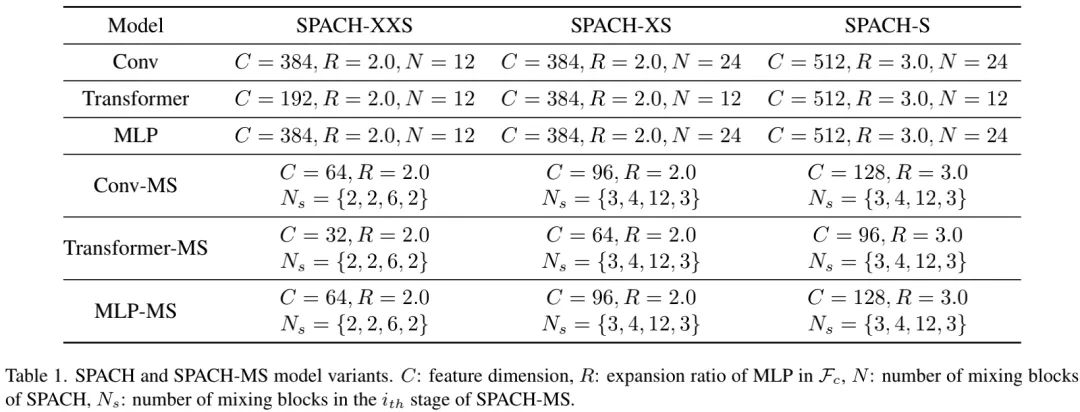
上表给出了不同模型配置的超参信息,通过控制模块数、通道数以及扩展比例一共设置了三个不同大小的模型:SPACH-XXS、SPACH-XS以及SPACH-S。
Mixing Block Design
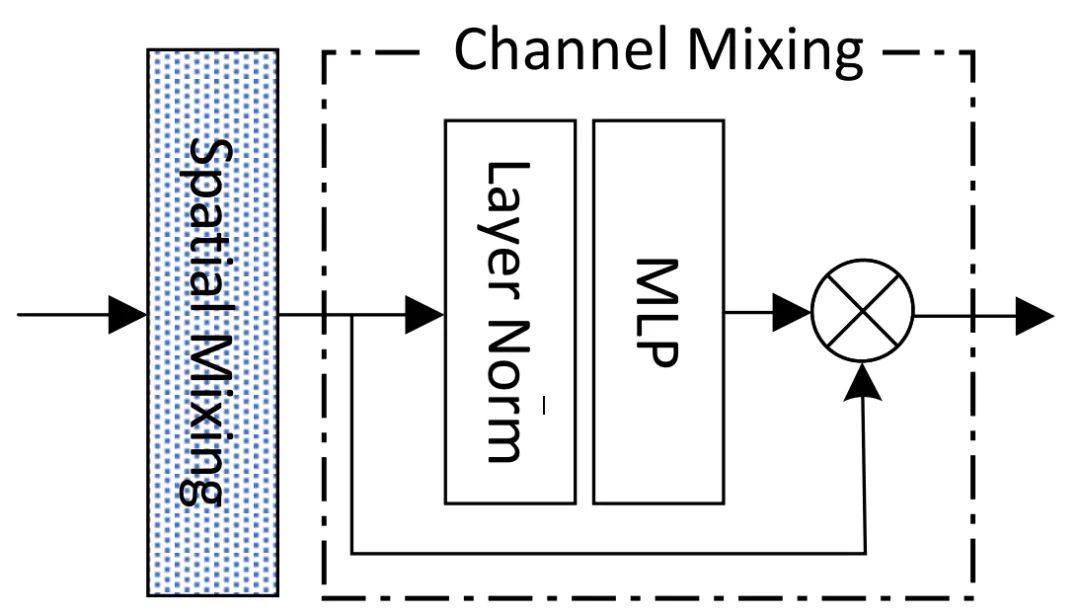
Mixing模块是SPACH架构的关键成分,正如上图所示:输入特征首先经过Spatial Mixing模块处理,然后再由Channel Mixing模块进行处理。其中:聚焦于不同位置的信息聚合,而则聚焦于通道信息融合。假设输出为Y,我们将Mixing模块描述如下:
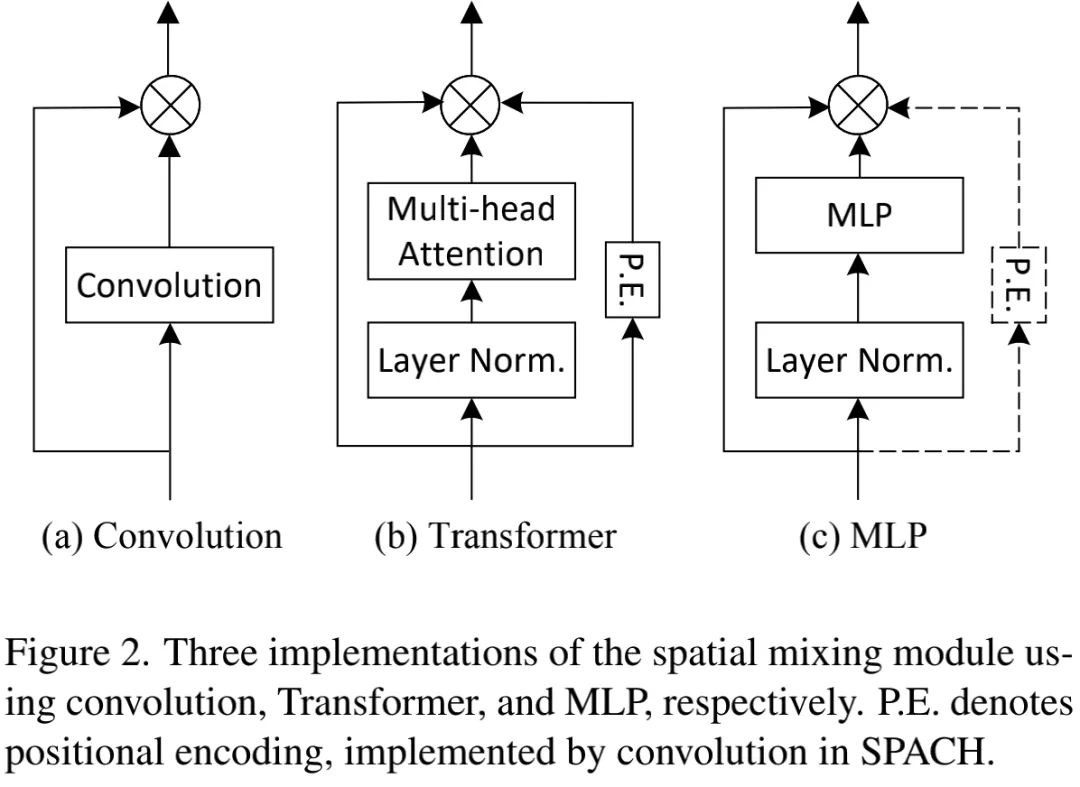
不同架构的关键差异在于Spatial Mixing模块。我们采用卷积、自注意力以及MLP实现了三种架构,见上图。具体来说:
· Convolution:采用深度卷积实现;
· Transformer:采用自注意力+CPE实现;
· MLP:采用MLP+CPE实现。
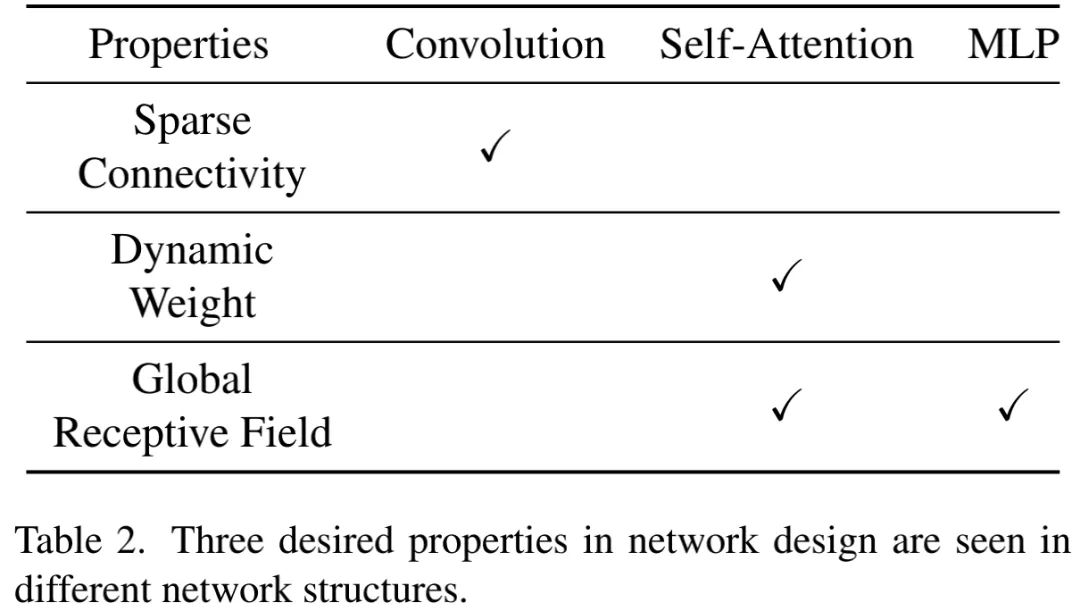
上述三种实现具有不同的特性,见上表。简要描述如下:
· 卷积结构仅包含局部连接,因此计算高效;
· 自注意力采用了动态权值,因此模型容量更大,它同时还具有全局感受野;
· MLP同样具有全局感受野,但没有使用动态权值。
总而言之,上述可见属性对于模型性能与效率有直接的影响。我们发现:卷积与自注意力具有互补特性,因此,很有可能将两者混合以组合所有期望属性。
三、Expirical Studies on Mixing Blocks
接下来,我们将进行一系列可控实验比较上述三个网络架构。
Multi-stage is Superior to Single-stage
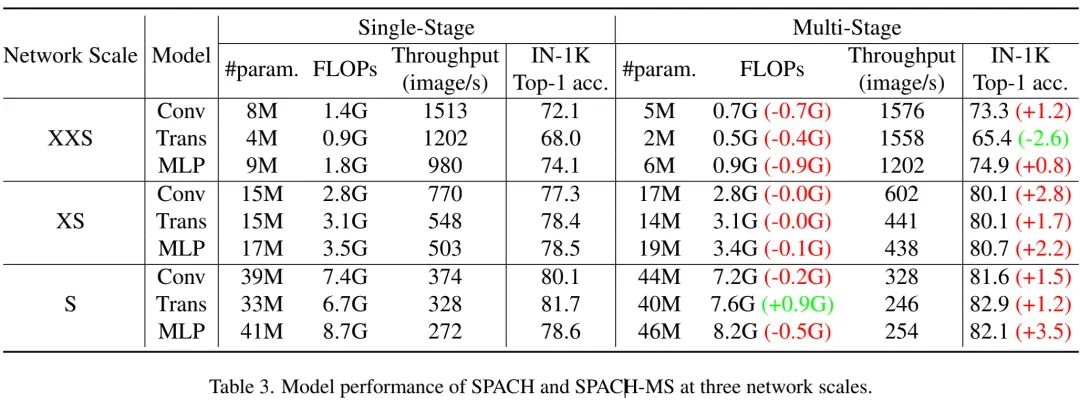
上表比较了单阶段与多阶段SPACH模型在ImageNet分类任务上的性能对比,从中可以看到:对于三种大小网络、三种类型网络架构,多阶段网络均取得了比单阶段网络更佳的复杂度-精度均衡。
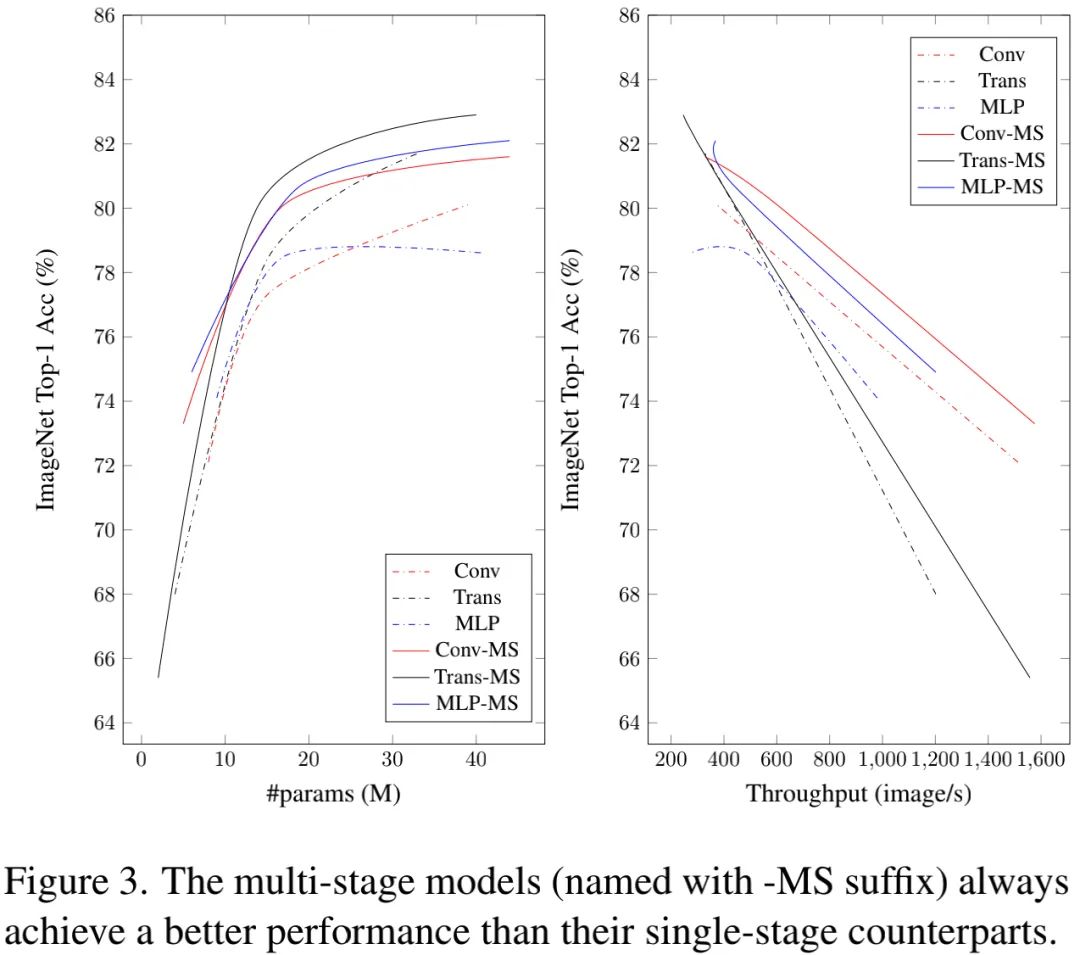
上图比较了图像分类精度与参数朗、吞吐量之间的关系。从中可以看到:多阶段模型总是优于单阶段模型。
上述发现与近期的一些工作相一致,比如采用了多阶段架构Swin与TWins具有显著优于单阶段架构DeiT的性能。我们的研究同样认为:多阶段架构可能是其性能优异的一个重要原因。
Local Modeling is Crucial
从上面的Table3与Figure对比可以看到:卷积架构具有与Transformer相当的性能;而深度卷积仅占模型整体0.3%的参数量与0.5%的FLOPs。
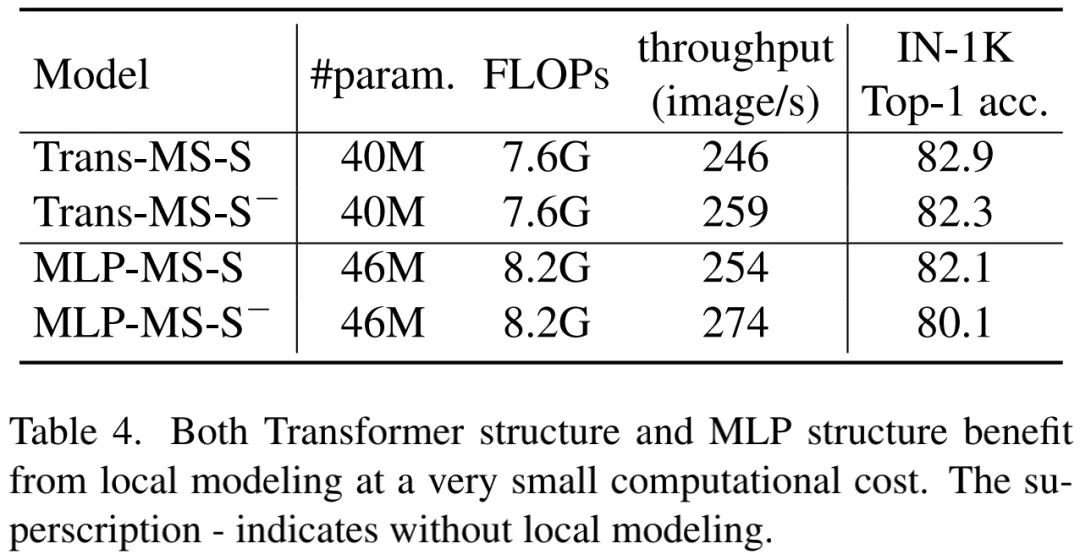
为说明局部建模如何帮助提升Transformer与MLP的性能,将两个结构中的卷积分支(注:卷积分支即CPE分支)移除,结果见上表。从中可以看到:卷积分支仅轻微降低了吞吐量,但大幅提升了两个模型的精度。该实验进一步说明了局部建模的重要性。
A Detailed Analysis of MLP
由于超多的参数量,MLP存在严重的过拟合问题。我们认为:过拟合是阻碍MLP取得SOTA性能的主要枷锁。接下来,我们将讨论两种可能缓解该问题的机制。
Multi-stage Framework Table3中的结果已表明:多阶段可以带来性能增益,对于大的MLP模型更为突出。比如,相比单阶段方案,MLP-MS-S取得了2.6%精度提升。我们认为:性能增益主要源于多阶段框架的强泛化性能。
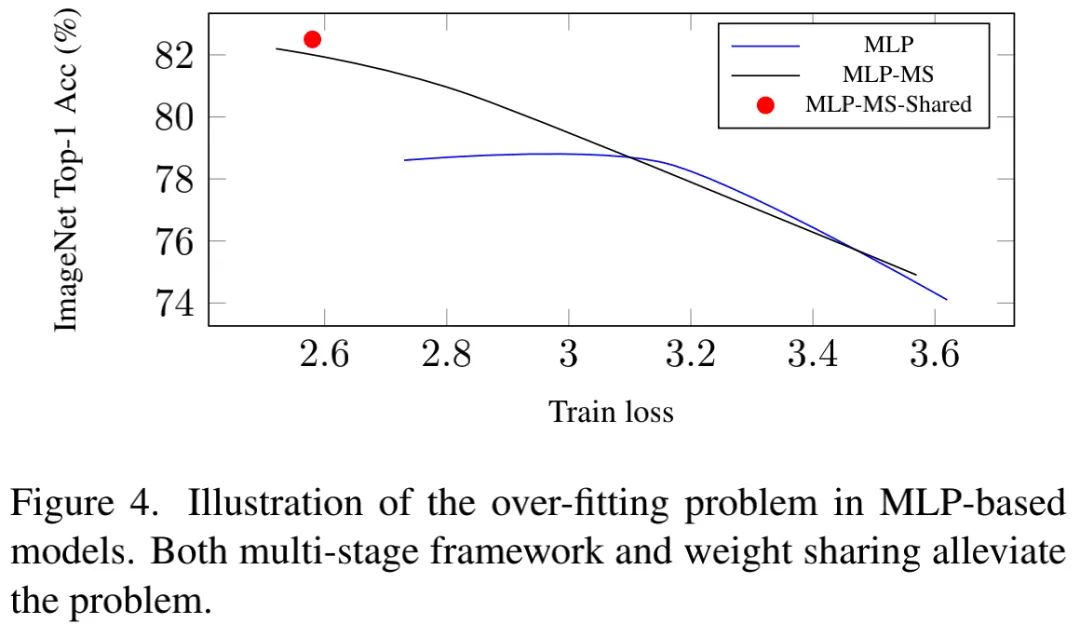
上表给出了测试精度与训练损失的关系图,可以看到:当测试精度趋向于饱和时,过拟合问题出现。而受益于多阶段架构,MLP-MS-S模型取得了比MLP-Mixer高5.7%的精度。
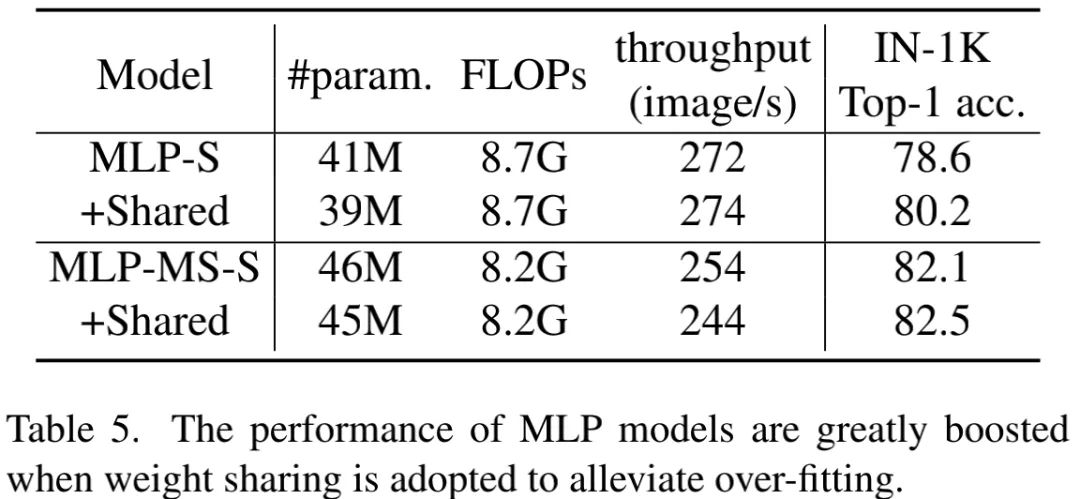
Weight Sharing 我们对Spatial Mixing模块实施权值功能共享。结果见下表,可以看到:MLP架构引入权值共享可以得到显著的性能提升。上面的Figure4同样验证了该结论。因此,如果MLP可以缓解过拟合问题,它仍具竞争力。
Convolution and Transformer are Complementary
卷积架构具有最佳的泛化性能,而Transformer架构具有最大的容量,故我们认为:两者具有互补性。
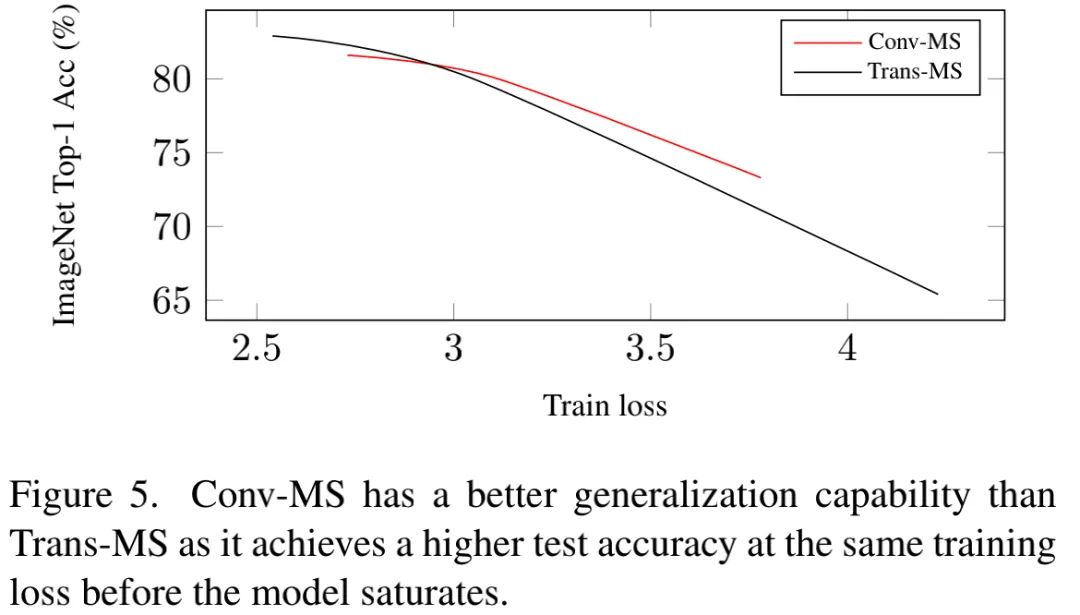
从上图可以看到:在性能饱和前,Conv-MS具有更高的测试精度。这意味着卷积模型具有更好的泛化性能,卷积仍是轻量型模型的最佳选择。
另一方面,Figure3与Figure5结果表明:Transformer可以取得比其他两个结构更高的精度。考虑到上述结构特性,很明显:稀疏链接有助于提升泛化性能,而动态权值与全局感受野有助于提升模型容量。
四、Hybrid Models
基于前述发现,我们构建了基于卷积与Transformer的混合模型:以多阶段卷积模型作为基线模型,采用Transformer层替换某些层。考虑到卷积的局部建模能力与Transformer的全局建模能力。混合模型的替换层选择如下:
· Hybrid-MS-XS:在Conv-MS-XS基础上,将Stage3的最后10层与Stage的最后两层替换为Transformer层。Stage1与Stage2保持不变;
· Hybrid-MS-S:在Conv-MS-S基础上,将Stage2的最后两层、Stage3的最后10层以及Stage的最后两层替换为Transformer。Stage1保持不变。
为进一步释放Hybrid模型的全部潜力,我们LV-ViT中的deep-PEL。不同于default-PEL(它采用卷积),deep-PEL采用四个卷积,卷积核、stride以及通道数分别为。我们将该模型称之为Hybrid-MS-*+。
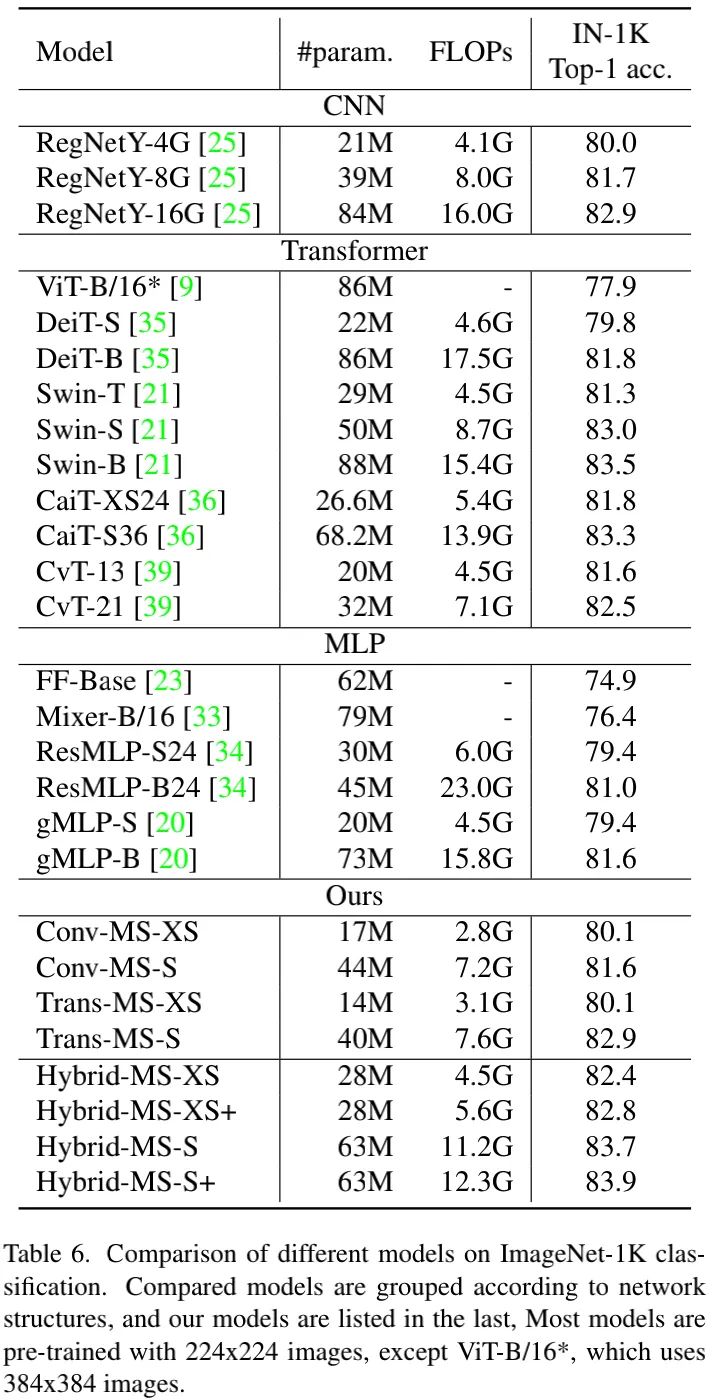
上表给出了所提Hybrid模型与其他模型的性能对比,从中可以看到:
· 相比纯粹的卷积或者Transformer模型,Hybrid模型具有更好的模型大小-精度均衡;
· Hybrid-MS-XS凭借28M参数量取得了82.4%top1精度,优于44M参数量的Conv-MS-S,略低于40M参数量的Trans-MS-S;
· Hybrid-MS-S凭借63M参数量取得了83.7%top1精度,以0.8%指标优于Trans-MS-S;
· Hybrid-MS-S+凭借63M参数量取得了83.9%top1精度,优于SOTA方案Swin-B与CaiT-S36。
· 作者认为:Hybrid-MS-S可以作为未来架构研究的简单且强力的基线。
五、个人反思
事实上,在这篇文章之前,也有一些研究在挖掘卷积与Transformer的融合与互补性。比如以下两篇
· CMT: Convolutional Neural Networks Meet Vision Transformers
· Early Convolutions Help Transformers See Better
但几乎没有文章将三者放到同一水平线上去对比,分析各自的特性以及互补性问题。笔者在前段时间进行Transformer、MLP调研时曾想过:CV领域Transformer与MLP的成功到底是源自什么?它们与Convolution的差异在哪里?相互之间是否有可借鉴性?看完该文,之前的几个问题也许有点答案了...
Illustrastion by Victoria Chepkasova from Icons8
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!

本周上新!


扫码观看!
关于我“门”
▼
