ICCV 2021 Oral | DEAR:面向开集动作识别的深度证据学习
本篇文章解读发表在ICCV 2021的长篇口头汇报 (Oral) 工作:“Evidential Deep Learning for Open Set Action Recognition”。该文章首次将深度证据学习理论,引入到视频动作识别领域,解决开放世界中的动作识别问题。在开放世界中,视频动作千姿百态,如何只利用已见过的动作类别的视频数据,训练一个具有不确定性估计的识别模型,从而达到识别未知动作的终极目标,是本篇文章所要解决的难点。本文提出的DEAR方法已在GitHub开源,以期促进视频理解、不确定性估计、开集识别、OOD泛化等相关领域的研究进展。
本文作者包文韬将在北京时间9月16日(周四)晚8点,于TechBeat人工智能社区分享Talk《DEAR:面向开集动作识别的深度证据学习》,欢迎大家扫描文末二维码,预约观看!

论文地址:
https://arxiv.org/pdf/2107.10161.pdf
代码链接:
https://github.com/Cogito2012/DEAR
项目主页:
https://www.rit.edu/actionlab/dear



一、研究动机
本文主要提出了一种在开放集 (open set) 中进行视频动作识别 (video action recognition) 的新方法。开放集,意味着测试数据中包含有未知类别的样本。开集识别 (OSR) 不同于常见的分类任务,它要求模型不仅能够识别已定义类别的样本,还能够正确拒绝未知的样本[1]。现实AI应用场景中,一方面,开发者无法清晰地定义业务数据的类别,另一方面,上线的模型不可避免地会接收来自从未见过类别的数据。因此,OSR任务非常符合当前AI模型落地所面临的困境,对OSR问题的研究也越来越受到学术界和工业界的重视。
面向图像数据的OSR研究,目前已取得了许多进展[2]。然而,短视频作为当前流行的大数据媒介,却极少有OSR问题相关的研究工作。相比于图像,视频所增加的时序维度,给OSR任务带来的挑战有两个方面。一是视频中的同一类型的动作差异巨大,从而导致有类别定义但处于边际分布的视频动作,与类别未知的动作混淆严重,模型难以区分。二是视频的静景偏差 (static bias) 使模型学到错误的因果关联,比如视频中的背景颜色、无关人物的外观、动作相关人物的特定着装等视频特征,都有可能被模型“投机取巧”地利用,作为识别动作的依据,却忽略了真正的时序动作特征。这两种挑战在经典的识别应用中,问题通常不大,如设计强有力的分类器,过拟合已定义类别的数据即可。然而在开放集里,为了准确判别出视频动作是否未知,解决这两种挑战就十分重要。
二、提出的方法
为了解决上述两方面的难题,本文的思路是将模型已见过的动作类别的视频,当作in-distribution (IND) 数据,而将包含未知动作的视频,视为out-of-distribution (OOD) 数据,即测试和训练的数据的联合概率分布满足
· 首次将基于证据理论的深度证据学习 (evidential deep learning, EDL) 引入视频动作识别领域,有效地建模视频动作的分类不确定性。
· 提出一种新的不确定性校准 (uncertainty calibration) 损失函数 ,以克服现有深度神经网络 (DNN) 的over-confident的问题,进而学到更准确的视频不确定性。
· 提出一个即插即用的证据特征偏差消除 (evidential debiasing) 模块CED,用于辅助模型学习到消除了静景偏差 (static bias) 的证据特征,进一步提升开集识别性能。
本文提出的DEAR (Deep Evidential Action Recognition) 方法十分简单,如图所示。以下将详细介绍本文的三个主要贡献。
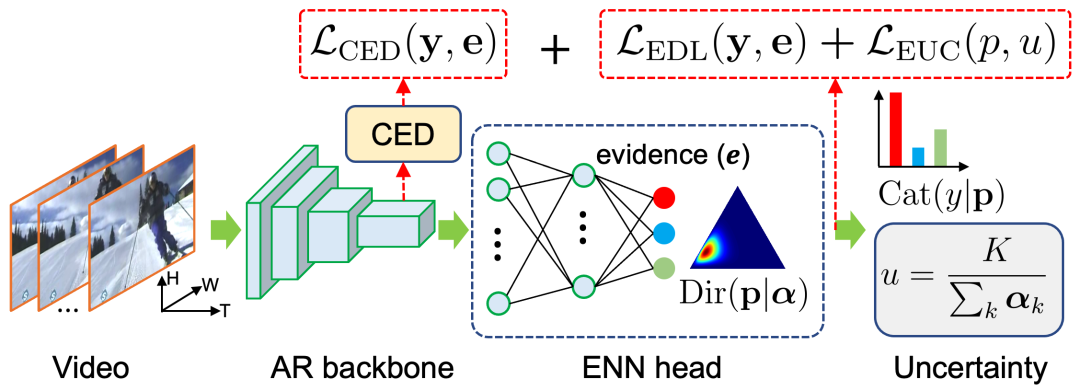
2.1 深度证据学习
本文在调研了现有的深度学习不确定性 (deep learning uncertainty) 相关文献后,认为目前基于证据理论 (evidence theory) 的深度证据学习 (evidential deep learning, EDL)[3],最适合视频识别任务的不确定性建模。相比于更常用的贝叶斯神经网络 (Bayesian Neural Networks, BNNs),EDL方法在建模不确定性时无需复杂的后验概率估计,也无需多次蒙特卡洛采样 (Mento Carlo Sampling),计算效率极高。参考NeurIPS 2018文献[3],本文对EDL做下简单的背景知识介绍。
EDL的基本假设是,认为模型输出的分类概率服从狄利克雷分布先验 (Dirichlet Prior),通过最大化观测数据的概率似然 (likelihood),可以利用深度学习模型得到输出分类概率的后验分布 (posterior)。从概率统计中我们知道,分类概率 (categorical probability) 的似然函数服从多项式分布 (multinomial distribution),而在贝叶斯框架下,狄利克雷先验属于多项式分布的共轭先验 (conjugate prior),也即后验分布 (posterior) 仍然服从狄利克雷分布。因此,EDL方法使用深度神经网络DNN直接学习狄利克雷后验分布的分布参数 ,即 , 类的分类概率 于是被视为从分布 中的采样,即 。这样,EDL模型直接学习到了分类概率的不确定性,一种类似于熵的二阶不确定性。
结合经典的Dempster-Shafer证据理论 (DST) 和主观逻辑 (subjective logic) 的观点,基于狄利克雷假设的分类识别模型,本质上是一种基于证据的 类的分类系统的特例。该特例在于,base rate为 ,于是各类别证据 与分布参数 满足 ,狄利克雷总强度 ,分类概率的期望 ,分类不确定性 。
模型训练。基于上述理论,为了最大化观测数据的似然,EDL训练过程中最小化的损失函数也相当简单。对于输入的视频样本 ,模型 输出各类的分类证据 ,类别标签为 ,其损失函数的最终推导形式为:
最小化这一损失函数,等价于最大限度地收集证据以支持正确的分类。其中需要注意的是,证据 的每一项非负,所以DNN的输出神经元不再采用常见的softmax,而是exp (或者relu, softplus)等激活函数。
模型推理。在测试阶段,对于输入的视频 ,EDL模型输出证据 ,输出类别 ,分类概率的期望为 ,分类的不确定性为 。如果不确定性很高,视频将被拒绝分类,作为未知类 (unknown) 输出,而如果不确定性很低,则接受 的分类结果。
2.2 不确定性校准
理论上,上述EDL方法已经可以实现开集动作识别。然而实际上,由于EDL的目标是一种最大似然估计,具有较高的过拟合风险。在不确定性估计方面,过拟合体现为无论样本是否未知,模型都过于信任分类结果 (over-confident)。因此,一个好的不确定性分类模型,其不确定性应当具备的特性是:准确分类的样本具有较高的可信度(低不确定性),错误分类的样本具有较低的可信度(高不确定性)。由于本文的不确定性来自于狄利克雷后验,而 类别的狄利克雷分布可以通过 维的单纯形 (simplex) 来表示狄利克雷概率密度。按照分类的准确性与不确定性,可以有四种组合,以 为例,其二维单纯形概率密度如表1所示:
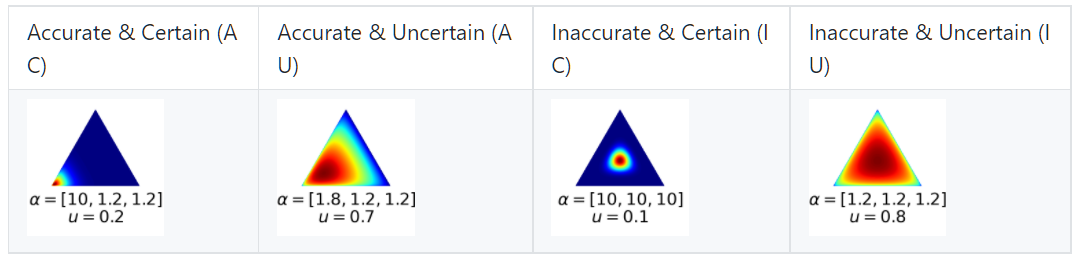
表1 四种不同类型的二维狄利克雷单纯形图
于是,为了鼓励模型学到更好的不确定性,样本的输出应当包含更多的AC和IU,更少的AU和IC。基于此,本文受现有的基于贝叶斯神经网络的不确定性校准工作[4]启发,提出了一种新的不确定性校准损失函数:
公式右边第一项惩罚准确分类但高不确定性 (AU) 输出( ),第二项惩罚错误分类但低不确定性 (IC) 的输出( )。两项分别用分类置信度(分类概率的期望的最大值) 和 进行加权。其中,还考虑了与训练进程有关的退火系数 ,定义为 ,其数值随着训练迭代次数 (由1到 递增)以指数速率从 增加到1.0。其背后的动机是,模型训练训练初期被错误分类的样本主导,应更多地惩罚IC分类结果,而训练后期被正确分类的样本所主导,应更多地惩罚AU分类结果。
2.3 证据特征偏差消除
不同于图像数据,视频中存在的静景偏差 (static bias) 容易使模型在训练过程中“走捷径”,错误地拟合这些有偏差的特征与视频动作类别之间的映射关系,而忽略了最能区分动作类型的时序动态特征。由于我们的训练数据不可避免存在静景偏差,在开集测试时,新的未知动作类别就会被错误地识别为已知类。因此,针对视频的开集动作识别,本文受近期ICML 2020中的ReBias[5]方法启发,在EDL框架下提出一种基于证据特征的偏差消除模块(如图所示)。
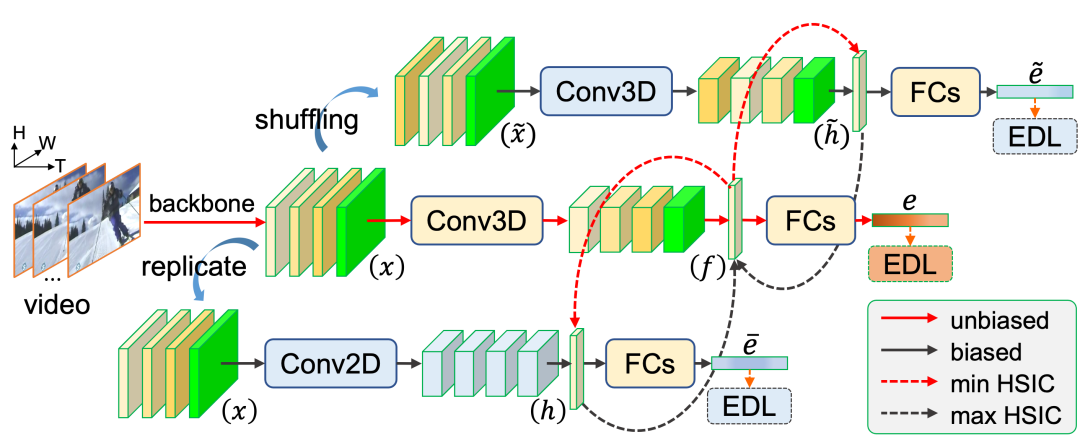
图2 证据特征偏差消除模块CED
该模块采用三条并行的特征提取分支,图中的上下两个分支分别采用时序混排 (shuffling) 后的时空特征输入以及2D卷积模块 (Conv2D),提取丢失了时序特性的特征作为有偏差的特征 (biased feature),用于引导采用3D卷积 (Conv3D) 的中间分支提取无偏差的特征 (unbiased feature)。因此,中间的无偏特征学习分支的损失函数为:
其中第一项为基于EDL的动作分类目标,第二项最小化希尔伯特-施密特独立性准则 (HSIC),促使特征 远离两种有偏特征 ,从而消除 的静景偏差。
同时,为了使得上下两条分支学习到有效的有偏特征,它们的总损失函数为:
其中第一项EDL分类目标保证特征 有足够的分类判别力而非随机的特征表示,第二项最大化HSIC使 靠近无偏特征 ,从而使得 有偏化。因此,当我们在训练中交替优化 和 后, 将成为极具分类辨识力且无静景偏差的特征。在实验中,我们发现联合优化上述两个损失函数,可取得相对更好的实验结果。
三、实验结果
本文的实验利用常用的UCF-101作为动作识别训练数据,该数据集定义了101类常见的视频动作。测试过程中,分别采用HMDB-51和Moments in Time (MiT) v2数据集作为小规模和大规模的未知类视频数据,与UCF-101验证集构成开放集 (Open Set)。
与现有方法比较。图3直观地展示了本文提出的DEAR方法以及对比方法,结合四种当前主流的视频动作识别模型,在上述两种规模的开放集上的测试结果。
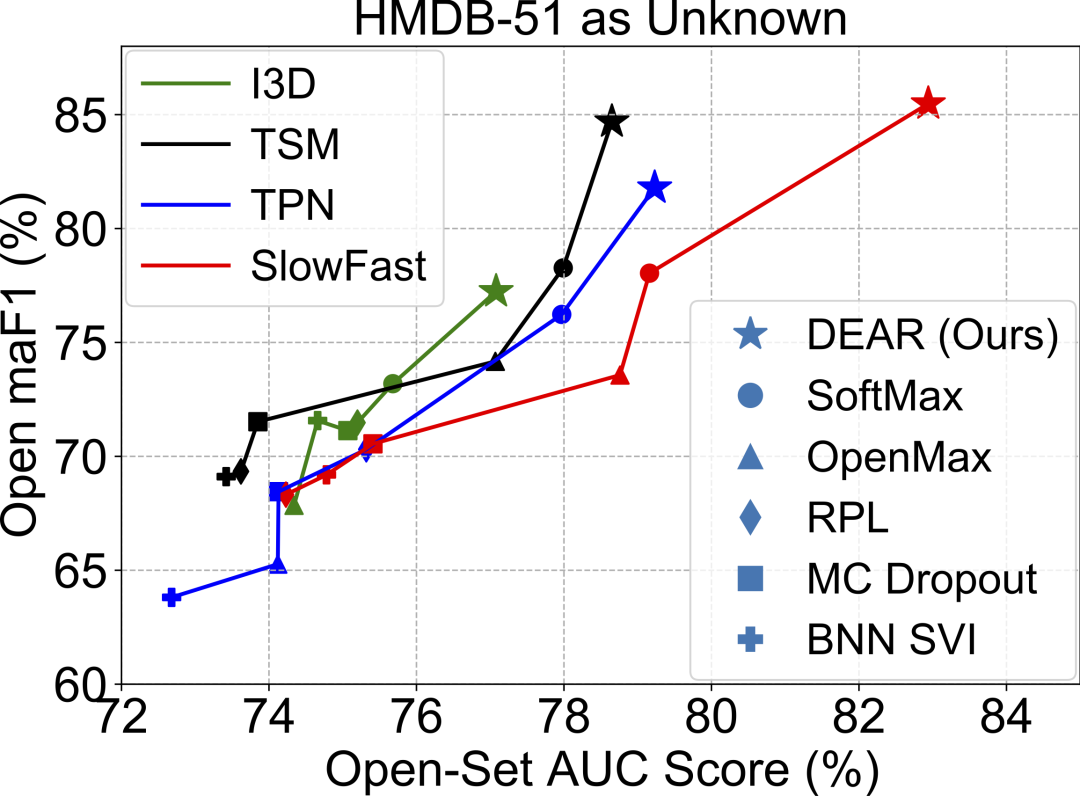 | 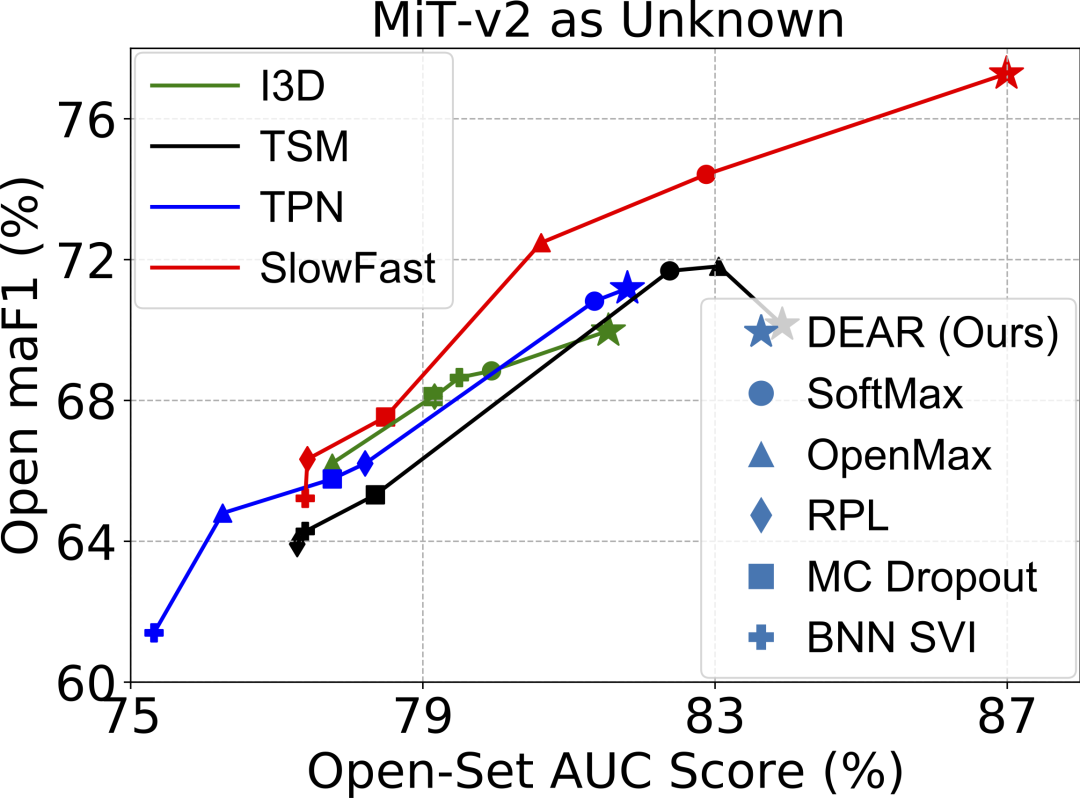 |
图3 主要实验结果
图中横轴Open Set AUC表示区分已知类和未知类的二分类能力,纵轴Open maF1表示将未知类视频与K个已知类数据一起评判模型的(K+1)类macro-F1指标,即同时考虑了各类的精度和召回。可以看到,本文DEAR方法基本处于图的右上方,表明DEAR显著优于其他对比方法,并且在SlowFast基础模型上的提升效果最显著。
OOD检测效果。图4展示了DEAR方法与其他两种基于深度学习不确定性的方法,在Out-of-Distribution (OOD)检测任务上的对比结果。实验中,UCF-101验证集作为in-distribution (IND)数据,MiT-v2作为OOD数据,I3D作为基础动作识别模型。可以看到,基于EDL的DEAR方法学习到的不确定性分布更加“平坦”,能够更好地将OOD数据与IND数据分开。
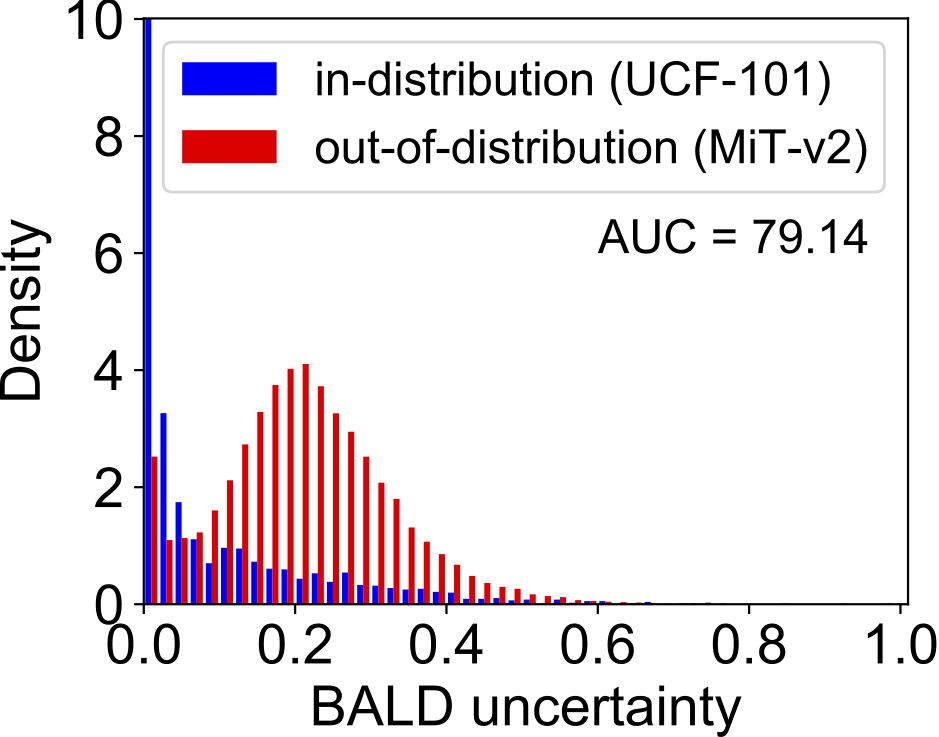 | 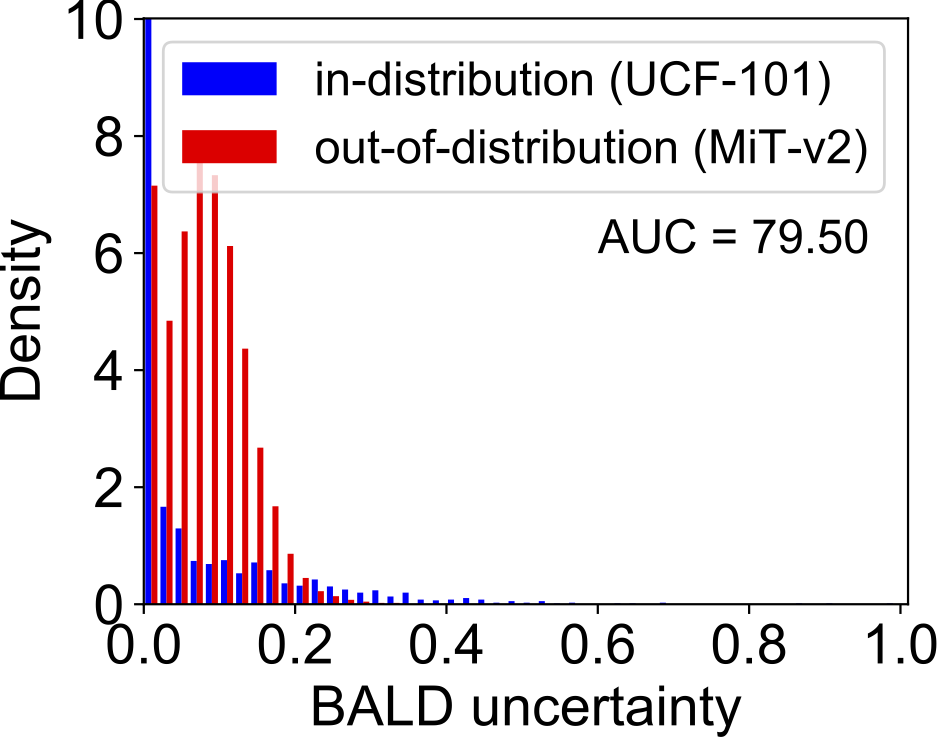 | 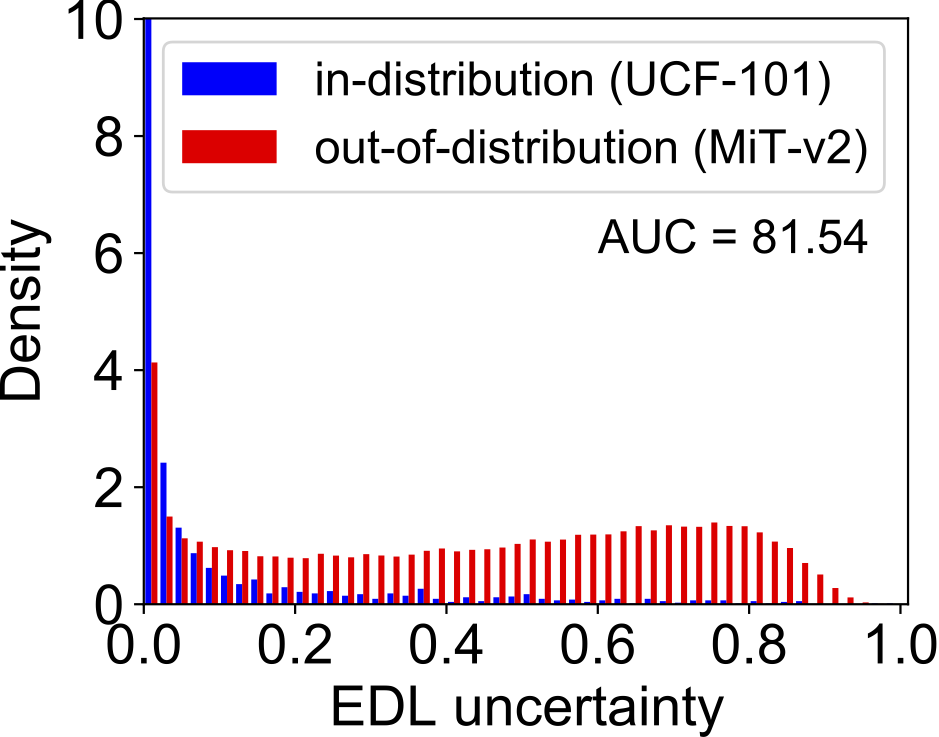 |
图4 OOD检测结果对比
消融实验。为了验证本文方法,消融实验中考虑了提出的不确定性校准损失 ( )、证据特征偏差消除模块 (CED)、以及CED的联合优化训练策略等三种控制变量,验证它们的有效性。表2可以看出,上述三个方面对开集识别性能的提升,均有显著作用。
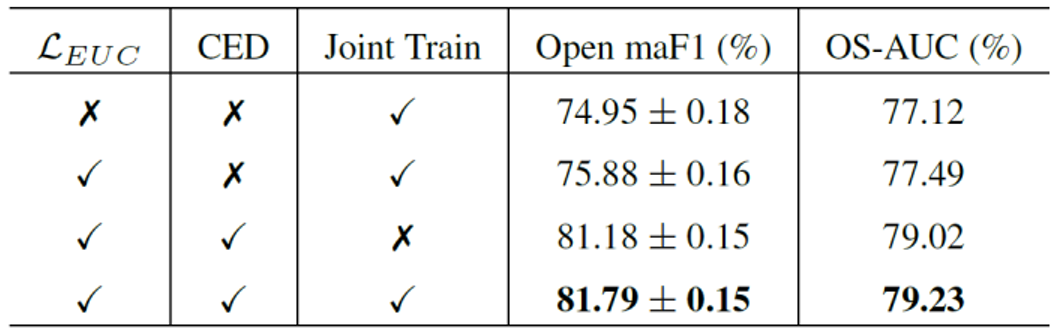
表2 消融实验结果
损失函数 的有效性。为了进一步验证所提出的 损失函数,是否可以有效改善不确定校准效果 (Uncertainty Calibration),本文采用了常见的Expected Calibration Error (ECE)指标,衡量模型的校准效果,ECE数值越小表明模型越好。表3表明本文提出的 无论在开集还是闭集测试中,均取得了一定的校准效果,且该效果在开集测试中更为明显。

表3 验证 LEUC 的不确定性校准能力
证据特征偏差消除CED的有效性。同样,为了验证提出的CED模块去除特征偏差的能力,文章采用kinetic数据集的一个10个类别的子集,作为有静景偏差的训练集和测试极,用定义了相同类别的Mimetics数据集子集作为相对于Kinetics无偏差的测试集。表4结果表明,当模型在有静景偏差的Kinetics训练集上训练后,虽然能在其对应的测试集上取得超过91%的top-1识别精度,但在缺乏场景偏差的Mimetics数据集上,top-1性能跌至26%左右。而使用本文提出的CED模块后,该性能可保持在34%左右,提升近8个百分点,并且同时保持相当甚至更好的Kinetics测试性能。
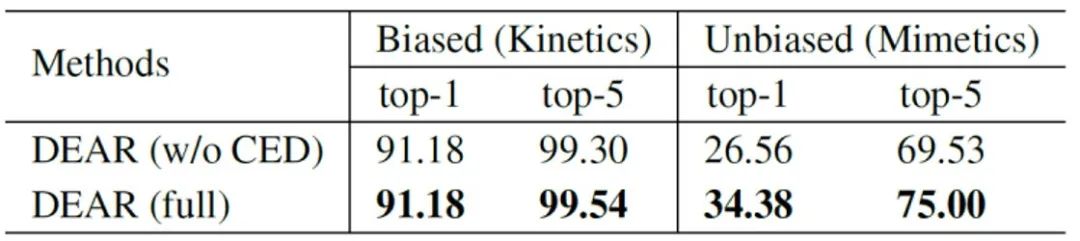
表4 验证CED去除特征偏差的有效性
关于本文的实验,在论文中还有大量十分有意思的实验结果,请参考本文实验部分和附件内容。
四、总结与展望
本文提出了一种新的开集动作识别方法,简称DEAR。该方法首次将深度证据学习引入到大规模视频理解任务中,实现视频分类不确定性建模,可以有效地识别在开放集中未知的视频动作。除此之外,本文提出的不确定性校准损失函数、证据特征偏差消除模块,可进一步提升开集动作识别效果。DEAR方法目前已在GitHub完全开源。本文的深度证据学习方法,可有效提升大规模视频理解模型的泛化能力。我们相信,这一方法在计算机视觉、多媒体理解、通用人工智能等更大领域有十分广泛的研究和应用潜力。
[1] Walter J Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance E Boult. Toward open set recognition. IEEE TPAMI, 35(7):1757–1772, 2012.
[2]. Geng, Chuanxing, Sheng-jun Huang, and Songcan Chen. “Recent advances in open set recognition: A survey.” IEEE TPAMI, 43(10):3614-3631, 2021.
[3]. Sensoy, Murat, Lance Kaplan, and Melih Kandemir. “Evidential deep learning to quantify classification uncertainty.” In NeurIPS, 2018.
[4]. Ranganath Krishnan and Omesh Tickoo. Improving model calibration with accuracy versus uncertainty optimization. In NeurIPS, 2020.
[5]. Hyojin Bahng, Sanghyuk Chun, Sangdoo Yun, Jaegul Choo, and Seong Joon Oh. Learning de-biased representations with biased representations. In ICML, 2020.
TALK预告
美国罗切斯特理工大学在读博士生—包文韬
《DEAR:面向开集动作识别的深度证据学习》
长按识别二维码,一键预约TALK!


Illustrastion by Tatyana Krasutskaya from Icons8
-The End-
“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!

扫码观看!
本周上新!

关于我“门”
▼
