ACM MM 2021 | VSAL:局部视频拷贝检测中的视频对齐和相似度学习

在本篇文章中,作者提出一种用于局部视频拷贝检测的视频对齐和相似度学习方法(Video Similarity and Alignment Learning on Partial Video Copy Detection)。旨在从给定的查询视频出发,在视频库中找到拷贝的视频并定位出拷贝发生的精确时间片段。VSAL通过自监督学习的方式,联合建模了空间相似度、时间相似度和视频局部对齐。从时空两个维度度量视频的相似度,解决了之前视频相似度过分依赖视频画面内容的问题;同时为了能够定位到局部拷贝片段,VSAL同时学习预测了一个方向图矩阵,通过该图的方向引导,可以方便灵活地进行视频局部对齐。该方法在VCDB核心数据集和自建数据集上均取得最优结果。

论文链接:
https://arxiv.org/pdf/2108.01817

一、任务介绍
为了解决视频版权保护的问题,视频级别的拷贝检测任务(Video-level Copy Detection,VCD) 可以从大规模的视频数据库中通过相似度比对的方式找出对应的拷贝视频。但是在实际的视频版权保护任务中,视频抄袭的攻击模式多种多样,体现在空间上是大量的画面编辑,在时间上则是大量的片段剪辑拼接。因此局部视频拷贝检测任务(Partial Video Copy Detection,PVCD)[1]不仅要建立一种视频相似度的度量方法来区分有拷贝视频和无关视频,还要有能力定位拷贝片段的起止时间,如图1所示。

二、背景介绍
从相似度度量角度看,现有的方法基本上都基于视频关键帧的表征+时序对齐的方案,这些关键帧表征主要聚焦在视频帧的画面上,导致相似度度量是偏向于画面信息的。为了把各关键帧在时序上的连续性纳入度量范围,现有方法通常会增加一个时序对齐的几何验证,例如基于DP的方法、TN或者THV等。时序对齐会通过几何的方式校验匹配帧序列的时序匹配程度把错误匹配的帧过滤掉,然后将剩余匹配帧的相似度聚合在一起,得到视频级别相似度。虽然使用了额外的时序信息辅助校验,但是最终的视频相似度仍然是帧相似度的组合,并没有量化地体现出两个视频在时序上的相似度。例如两段不同新闻的口播视频,画面相似容易误匹配。
另外,目前有一些方法去学习视频本身时空结构的相似性,比如ViSiL[2],采用一种端到端的相似度聚合方案,直接学习去建模视频级别的相似度。但是ViSiL是一个黑盒模型,只能从各帧相似度得到视频相似度,并没有办法定位到拷贝片段,适用于并不适用于PVCD任务。
基于此,本文提出了一个视频相似度和视频对齐的学习方法(Video Similarity and Alignment Learning,VSAL),贡献点如下:
· 从帧对帧的空间相似度矩阵中,学习一个Mask Map(MM),作为时间维度的相似度度量,和空间相似度正交,可以合并成为时空相似度,从而避免最后的相似度度量过程偏向于空间信息的问题;
· 同样从空间相似度矩阵中,学习一个Step Map(SM),作为时序对齐片段定位的指示图,可以很容易地定位到拷贝片段。
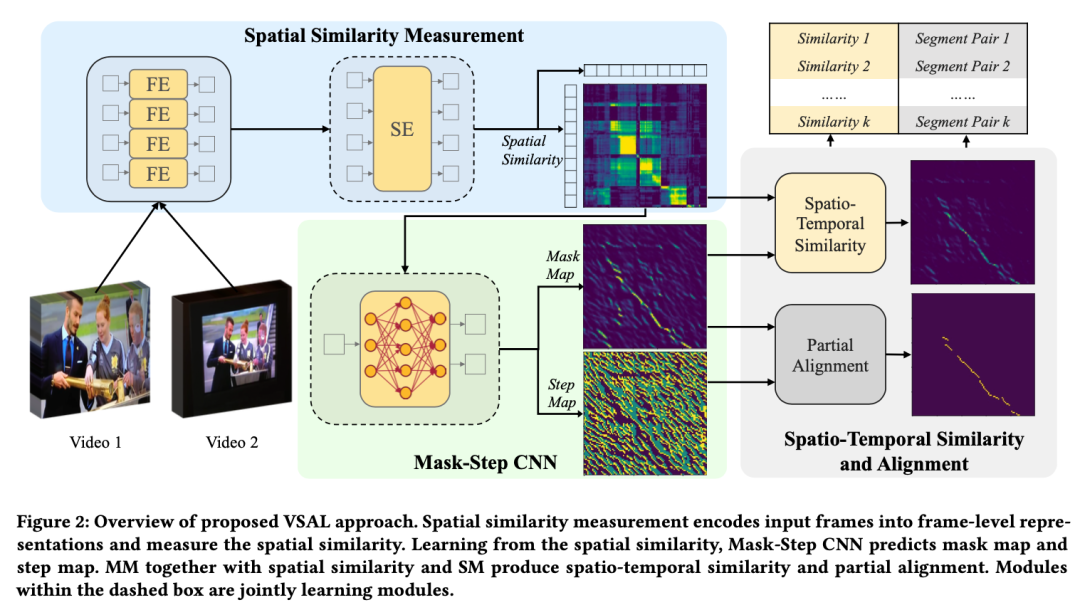
三、方法介绍
3.1 问题建模:
度量两个视频是否匹配,要从一下三个方面考虑,空间相似度
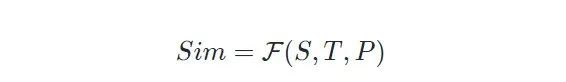
· 首先
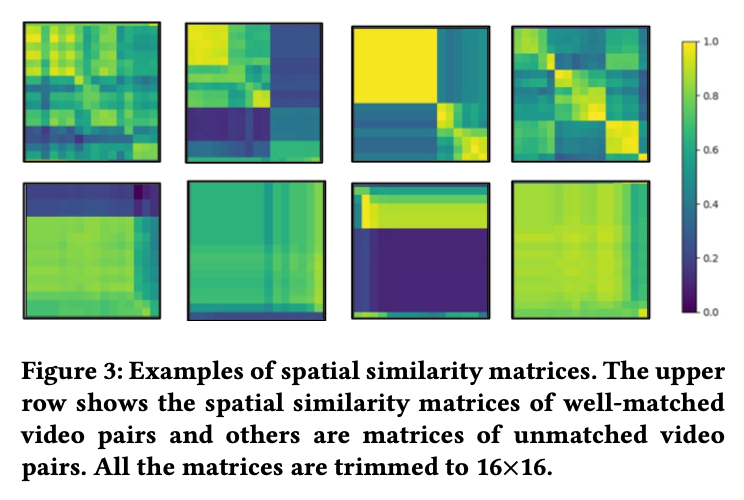
· 另外,从图3可以看出,如果两个视频是匹配的,那么在它们的空间相似度矩阵上,经常会有一条或者多条匹配路径。要定位拷贝片段,就要准确的分离出这些匹配路径。这里定义
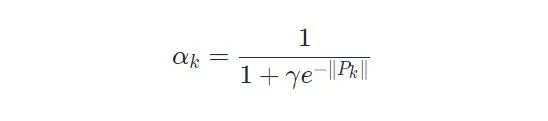
· 时间相似度
· 得到上述三个部分之后,最终的相似度就可以表示为:
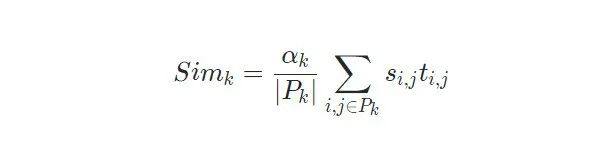
3.2 空间相似度度量
首先对各帧帧进行帧级别编码(FE)和序列级别的编码(SE),对于FE使用是预训练的CNN,SE使用的是Transformer编码器,最后使用余弦距离度量帧对帧的特征,因此这里空间相似度表示为:
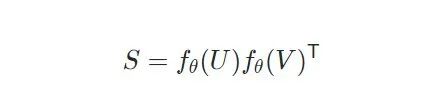
3.3 Mask-Step CNN
3.3.1 模型结构
学习MM和SM使用的是一个两分支的CNN,由主干部分、Mask分支和Step分支组成,结构如表1:

3.3.2 模型训练
训练采用的是自监督的方式,首先对同一个无标签视频进行两种不同的随机空间和时间上的变换,得到数据增强之后的两条视频,他们互为同源视频。经过时间和空间变换之后,可以通过两条输出视频与原始视频的各帧对应关系得到Mask标签和Step标签,如图4:
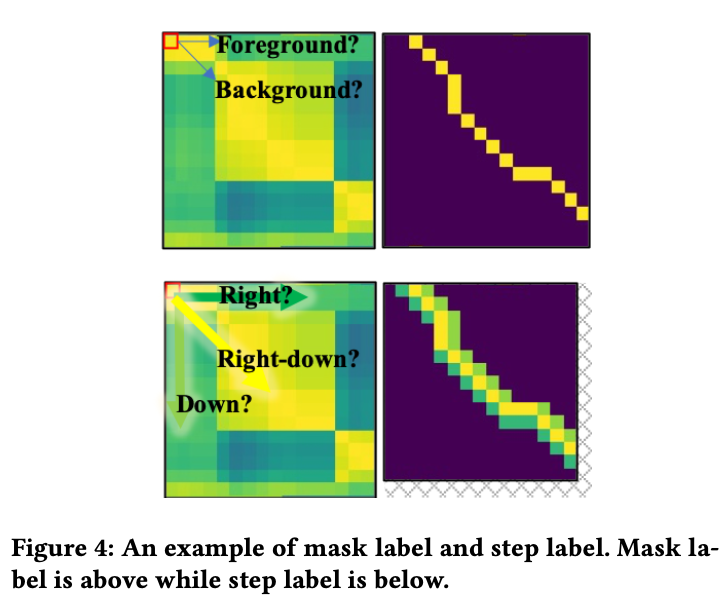
这里,Mask分支学习的是矩阵上各个位置落在匹配路径上的概率;Step分支学习的是矩阵某个位置的下一步的前进方向。所以,Mask标签在匹配帧的位置为1,其余位置为0;Step标签的数值由当前位置的右下、右、下位置上的视频帧是否匹配决定,分别定义右下、右、下的标签为0、1、2.
最后对Mask和Step分支同时多任务学习,全局损失函数:
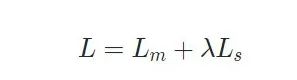
其中Mask损失:
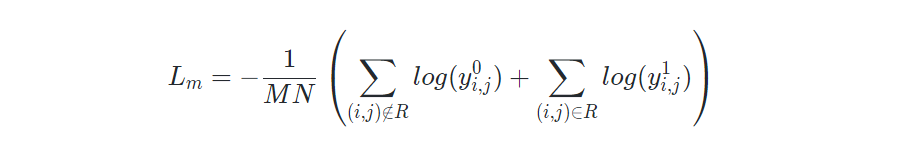
Step损失:
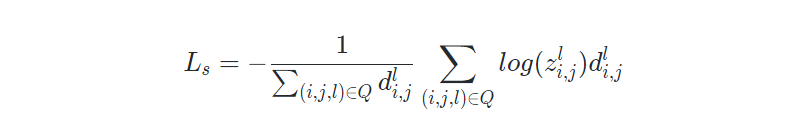
取MM各位置的预测概率作为空间相似度,使用SM中的每个点的方向预测结果决定下一步运行方向是右、下或者右下,从而可以定位匹配片段。
3.4 时空相似度度量和对齐
得到MM和SM之后,按照相似度的大小选取片段的起点,并且定义片段的截止条件之后,很容易沿着SM的方向指示得到

得到
四、实验结果
4.1 SOTA对比
使用无标数据训练,在公开的PVCD基准数据集VCDB core和我们在FIVR-200k数据集[3] 上补充片段级别的标注的FIVR-200k-PVCD数据集上进行实验。
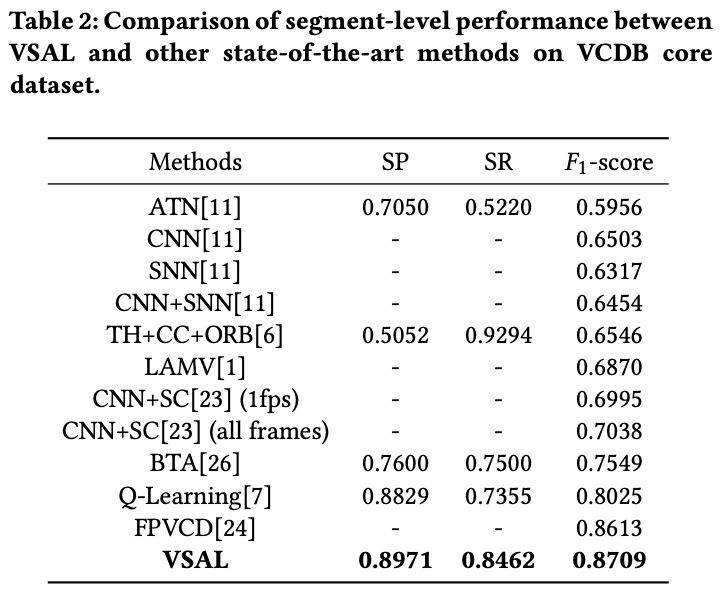
可以看到VASL在VCDB core数据集上得到了最好的效果,说明了其在PVCD任务上的有效性。
4.2 销蚀实验
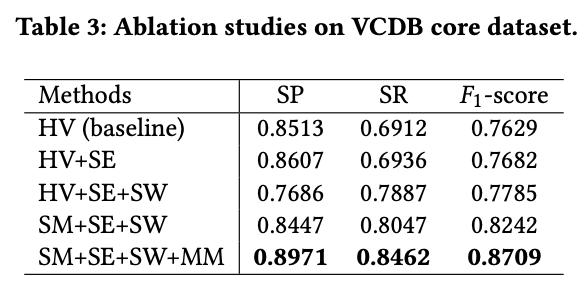
如表3所示,各模块对最终结果都有明显的提升:
4.3 在FIVR-200k-PVCD上的实验
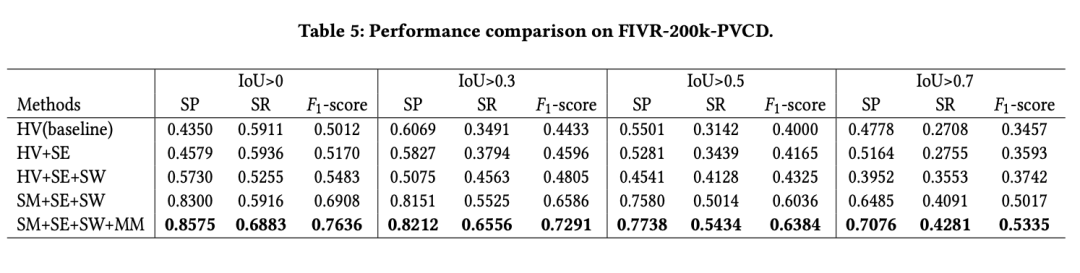
Baseline模型的F1-score相对于VCDB core数据集上有超过25%的下降,这体现了新数据集的难度。VSAL各个模块仍然表现出来和VCDB core数据集上相似的效果提升。
五、可视化分析

可以看到,SM对除最后一列和最后一行的每个位置都预测下一步的行动方向,如果路径的起点选对了,那么基本可以得到正确的对齐路径。MM清楚的表现出了对齐路径的分布。从图像上可以看出,时间相似度与空间相似度并没有直接的关系,有些地方的空间相似度虽然很高,但是空间相似度却比较低。这说明时间相似度表征的是与空间相似度正交的另外一部分信息。
六、结论
本文从将PVCD任务划分为空间、时间相似度和对齐片段来分别得到,在学习过程中联合建模,采用自监督的数据构造方式,得到了目前最好的效果。但是PVCD任务仍然没有被完全解决,难点在更细粒度的视频时间上的剪辑的场景,还有在时长较长的视频下的效率问题。
参考文献
[1] Partial copy detection in videos: A bench- mark and an evaluation of popular methods. TBD 2016.
[2] Visil: Fine-grained spatio-temporal video similarity learning. ICCV 2019.
//
本文作者
韩振
阿里巴巴达摩院·高级算法工程师
-The End-

怀念不如相见!🙋
10.16晚18:00
将门-TechBeat将在上海与大家一起围炉夜话
ICCV线上线下嘉宾连线交流
分享AI道路上的故事集、经验贴

还不知道本次活动详情?
请点击本链接或“阅读原文”查看更多活动信息😏

扫码观看!
本周上新!

关于我“门”
