ACM MM 2021 | HANet:基于层次化对齐网络的视频-文本跨模态检索
本文工作是由阿里达摩院团队与西安电子科技大学联合完成。视频-文本跨模态检索旨在给定文本描述/视频片段,在视频或文本语料库中找到与之对应的视频片段/文本描述。在本文中,针对之前工作在检索过程中对细粒度和局部信息的挖掘不足的问题,我们提出了一种层次化对齐网络(Hierarchical Alignment Net-work, HANet),将视频和文本解析为三个语义层次,即事件(event)、行为(action)和实体(entity)。基于此,我们建立了一种多层次表征和对齐方式,不同语义层次的对齐可以做到从粗粒度到细粒度的层次化信息探究。HANet 在MSR-VTT和VATEX数据集上均达到最优效果。

论文链接:
https://arxiv.org/abs/2107.12059
代码链接:
https://github.com/Roc-Ng/HANet

一、引言
在视频-文本跨模态检索任务中,常见的思路是提取视频和文本的特征作为嵌入向量,将嵌入向量隐射到联合空间中,在此空间内让成对的视频文本的嵌入向量尽可能靠近,不成对的尽可能拉远。现有的大部分工作都是采用这样的思路,提取视频和文本的全局特征作为嵌入向量。但是在视频和文本中都包含着丰富的多粒度信息,单一的全局特征可能无法充分利用局部的细粒度信息,而这些细粒度信息在视频文本匹配检索中具有非常重要的作用。
近两年,部分工作开始关注局部细粒度信息并在视频-文本跨模态检索任务上取得了不错的效果,但仍然存在一些问题,比如JPoSE [1] 只针对单模态局部信息挖掘,只将文本描述拆分成了名词和动词,然后在与整个视频做匹配操作;HGR [2] 虽然尝试挖掘视频局部信息,但只是简单地将视频映射到不同的特征空间中,用帧级别特征与文本的局部和全局做匹配,这样就会造成特征不对齐的问题。
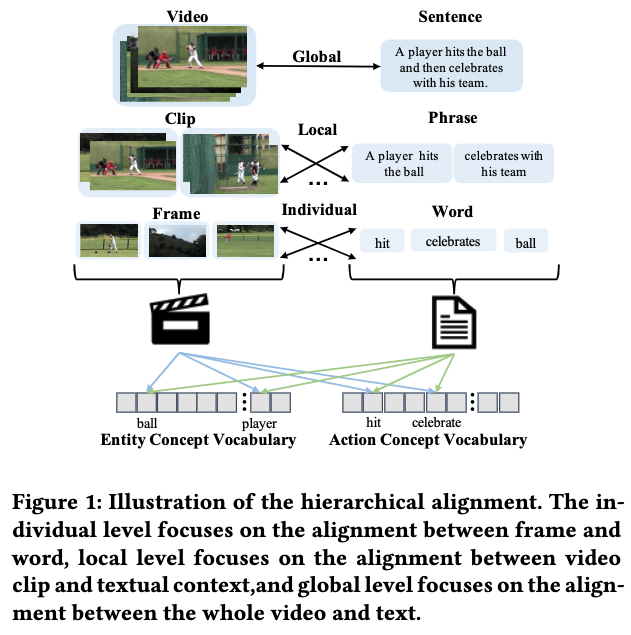
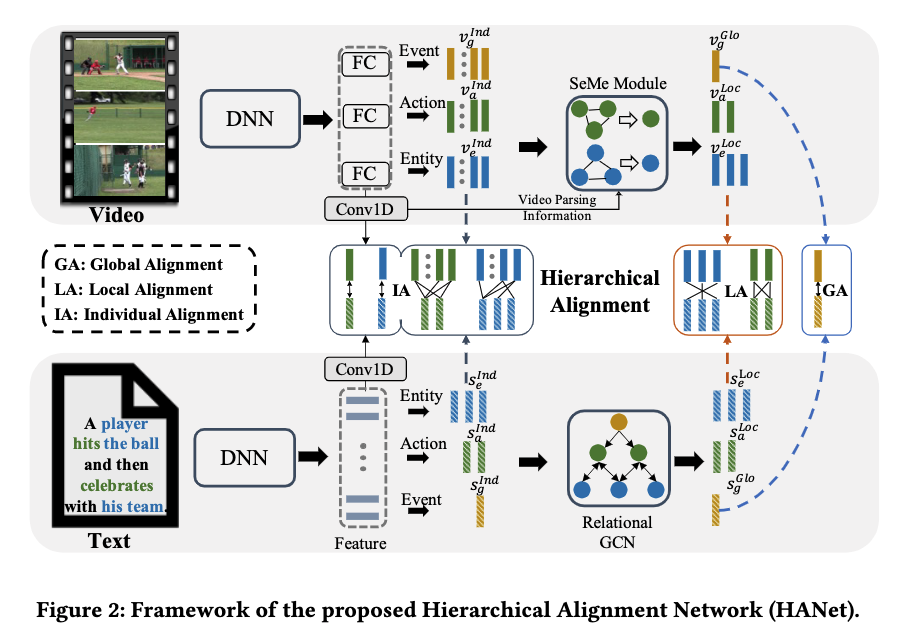
二、方法
2.1 视频和文本解析
视频解析
其中 , 为视频帧数,为预定义的action概念数。
文本解析
2.2 视频和文本特征
视频特征
对于局部级别特征,它是可靠概念上所对应的帧(视频片段)的特征融合,这里的可靠概念是指该视频所对应的概念。我们首先使用多示例学习(MIL)机制在帧级别的概念置信度上获取视频级别的概念置信度,然后采用置信度最高的前几个作为可靠概念,基于可靠概念即可得到对应的视频片段,将对应的视频片段上的特征融合便得到了最终的个体级别特征。
其中基于MIL获取视频级别的概念置信度公式如下所示,(以action(行为)为例)
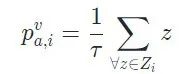
其中为视频级别的针对第 个action概念置信度, 是针对第 个action概念上前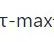 个的帧级别置信度的集合。
个的帧级别置信度的集合。
对于全局级别特征,我们使用注意力机制作用在上文个体级别特征中的全局特征上。
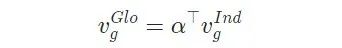
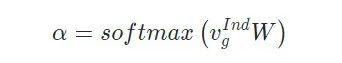
文本特征
对于个体级别特征,我们首先使用bi-GRU来提取特征,然后从中挑选出名词和动词作为个体级别特征。对于局部特征和全局特征,使用relational-GCN网络来捕捉个体特征之间的关系。具体实现可参考原文及代码实现。
2.3 多层次对齐机制
个体对齐
个体对齐针对于个体级别特征,在这里包含两个部分,一部分是个体特征之间计算相似度,这里使用在图文检索中常见的stack cross attention [4] 机制。另一部分是基于个体特征上求得的视频级别概念置信度,我们使用 Jaccard 相似度。其中stack cross attention如下所示:
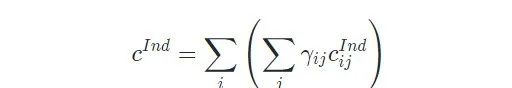
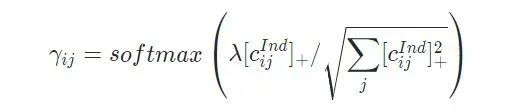
Jaccard相似度如下所示:
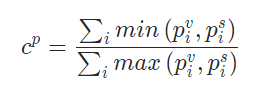
局部对齐
全局对齐
我们在两个公开的常用数据集MSR-VTT和VATEX上开展实验。在MSR-VTT上,我们使用官方的划分标准,即6573个视频用于训练,497个视频用于验证,剩余的2990个视频用于测试。在VATEX上,我们同之前的工作一样,只使用英文的文本描述。
3.1 对比实验
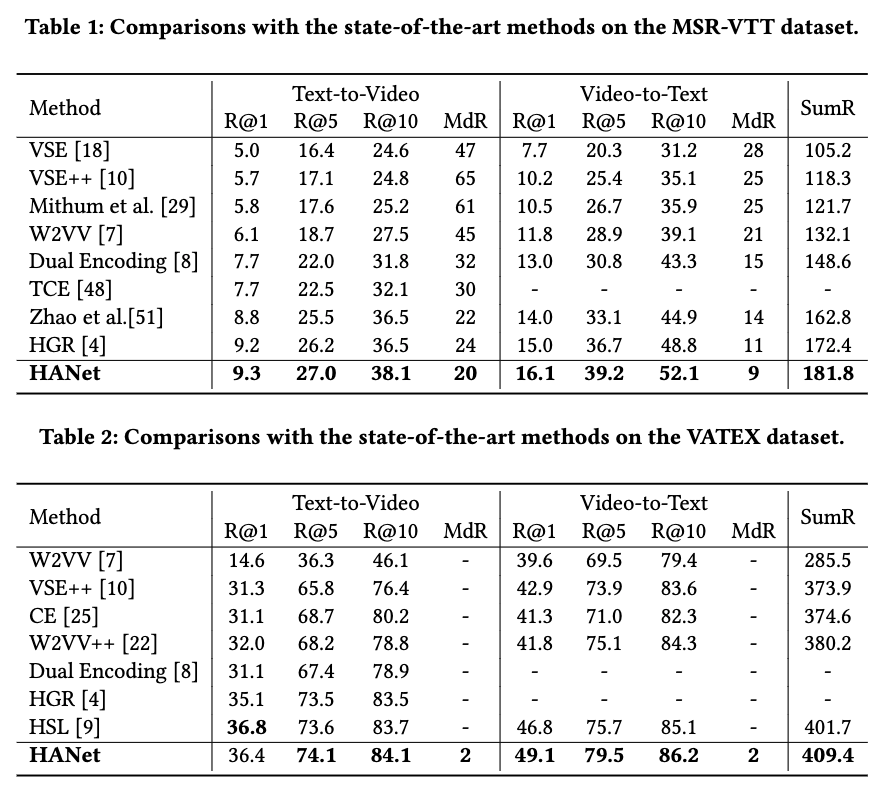
在目前的视频文本检索任务中,对使用的预训练特征没有完全统一。为了保证对比的公平性,在本文中所有的方法都使用相同的预训练特征,即在MSR-VTT上使用2048d的ResNet152特征,在VATEX上使用1024d的I3D特征。表1和表2展示了在两个数据集上的对比结果。可以看出,HANet几乎在所有的标价指标中都明显优于之前的SOTA方法。与也做了细粒度挖掘的方法HGR相比,HANet在全部指标上都取得了领先,这充分说明了我们层次化对齐机制的有效性。
3.2 消融实验
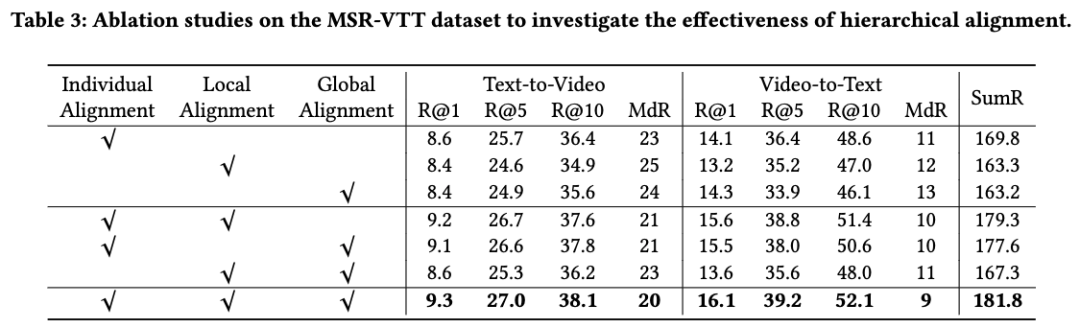
我们进一步做了消融实验来验证层次化对齐机制的有效性。从表3可以看出,基于全局-局部-个体的层次化对齐机制比任意的单一对齐机制都有明显的性能提升,这说明多粒度信息在视频文本检索中确实发挥着重要的作用。
3.3 定性实验
首先我们在图3中展示了几个基于文本的视频检索结果。因为我们方法使用了基于弱监督的概念分类方法来解析视频,为了验证该方法的有效性,我们将部分实验结果展示如下。图4展示了与视频相关的可靠概念,字体越大代表置信度越高。不难看出预测的概念相对都是合理的,这对跨模态的视频文本检索是有帮助的。图5则展示了帧级别的概念置信度,在于概念相对应的片段上,置信度较高,这也说明了该方法有助于提升模型的可解释性。

四、结论
在本文中,我们提出了层次化对齐网络(HANet),以充分利用不同语义级别表示的互补信息解决视频文本检索任务。为此,我们首先分别通过基于概念的弱监督分类和现有的文本解析工具包来解析视频和文本。然后我们引入多层次对齐机制来对齐个体、局部和全局级别的表示,最终综合计算跨模态相似性。在两个常用的文本视频检索基准上的定量和定性结果显著证明了 HANet 的的优势和有效性。在接下来工作中,由于成对匹配相对昂贵,更精确和有效的层次对齐还有待探索。
参考文献
[1] Fine-Grained Action Retrieval Through Multiple Parts-of-Speech Embeddings, ICCV, 2019.
[2] Fine-grained video-text retrieval with hierarchical graph reasoning, CVPR, 2020.
[3] Simple bert models for relation extraction and semantic role labeling, Arxiv, 2019.
[4] Stacked cross attention for image-text matching, ECCV, 2018.
//
韩振
韩振,现就职于阿里巴巴达摩院,2019年硕士毕业于西安交通大学电子与信息工程学院。研究方向包括多模态检索,音视频匹配与序列对齐,自监督学习等。相关工作发表在ACM MM等国际会议。

扫码观看!
本周上新!

“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!
关于我“门”
▼
