Fine-tune时代结束?清华P-Tuning v2大幅提升小模型性能,NER也可promp tuning了!
以下文章来源于高能AI ,作者JayJay
高能量的AI算法集散地、转运站!
近日,清华大学发布P-Tuning v2版本,其重点解决了Prompt tuning在小模型上效果不佳的问题(如下图所示),并将Prompt tuning拓展至更复杂的NLU任务,如MRC答案抽取、NER实体抽取等序列标注任务。

论文题目:
P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks
论文地址:
https://arxiv.org/pdf/2110.07602.pdf
论文源码:https://github.com/THUDM/P-tuni

笔者注:本文将论文《GPT Understands, Too》[1]中的Prompt tuning称为P-tuning v1。
一、P-Tuning v1回顾

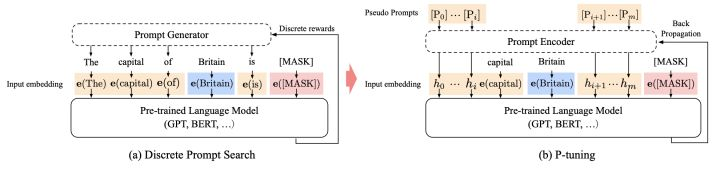
在知识探测任务(Knowledge Probing)上,相比人工提示(离散)方法,P-Tuning v1显著提升效果:

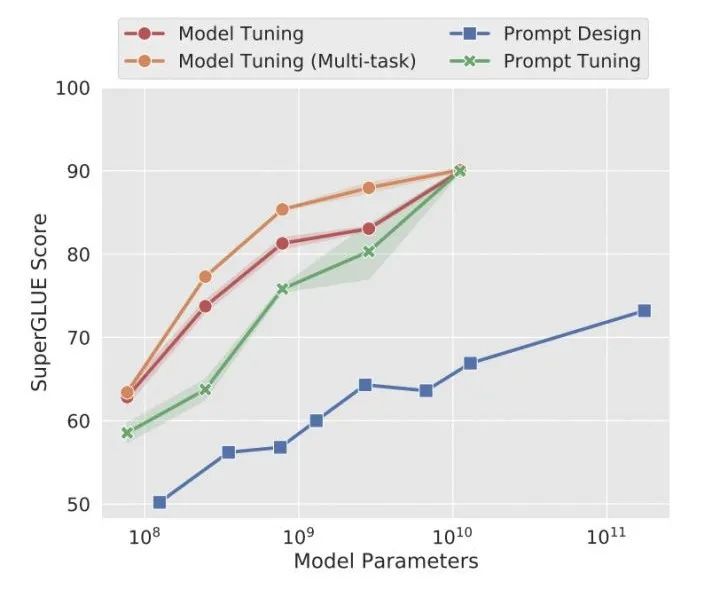
最近的一篇论文《The Power of Scale for Parameter-Efficient Prompt Tuning》发现(如上图):随着模型参数的增加(达到10B级),Prompt Tuning才能与Fine-tuning效果相比肩,而在小模型上性能不佳。
二、P-Tuning v2关键所在:
引入Prefix-tuning
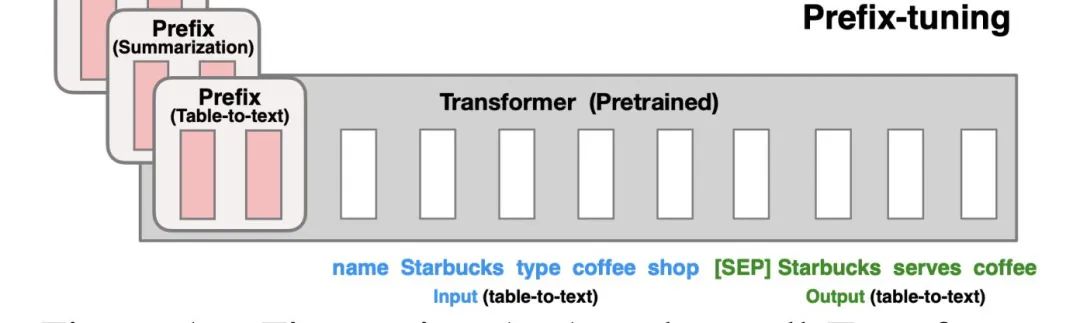
Prefix-tuning(前缀微调)最开始应用在NLG任务上,由[Prefix, x, y]三部分构成,如上图所示:Prefix为前缀,x为输入,y为输出。Prefix-tuning将预训练参数固定,Prefix参数进行微调:不仅只在embedding上进行微调,也在TransFormer上的embedding输入每一层进行微调。
P-Tuning v2将Prefix-tuning应用于在NLU任务,如下图所示:
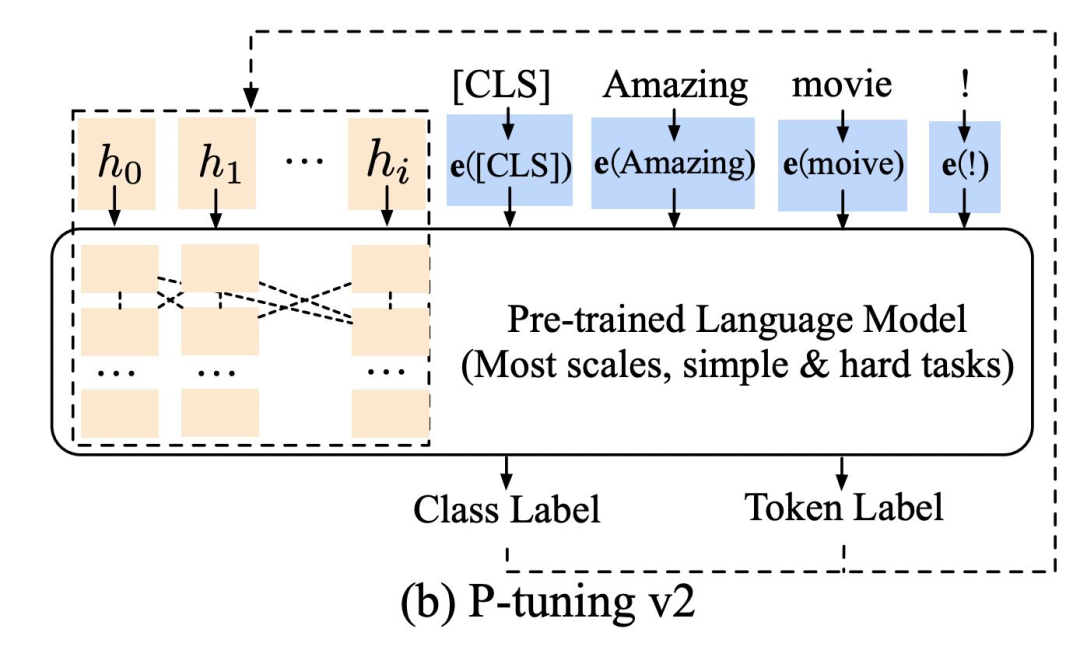
那么,P-tuning v2哪些参数需要训练?
三、P-Tuning v2实验结果
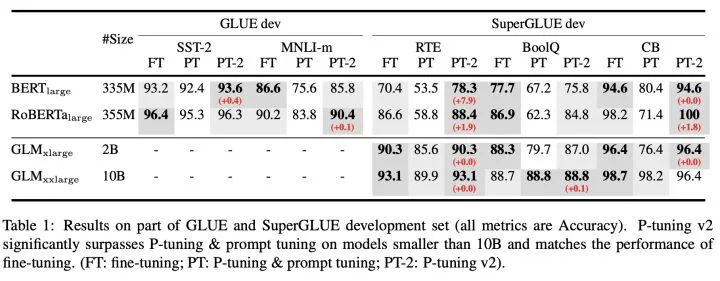
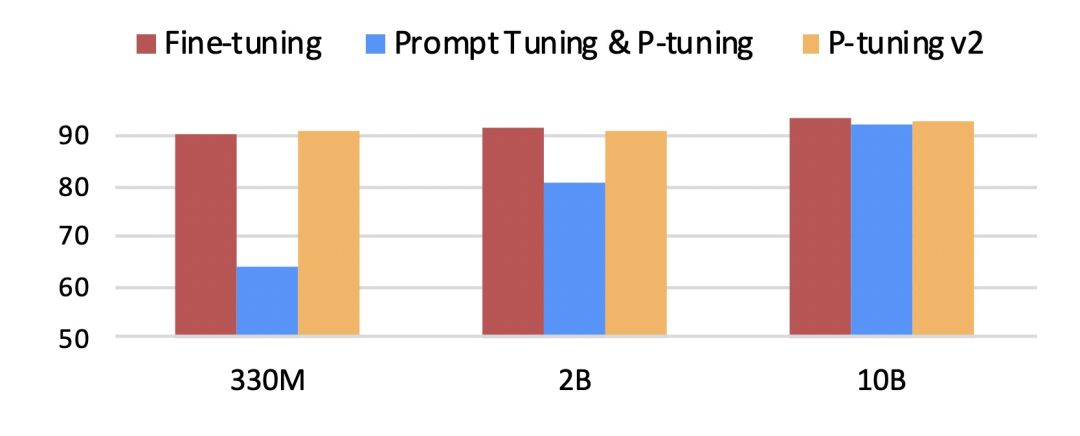
在不同规模大小的LM模型上,P-tuning v2能与精调(Fine-tuning)方法的表现比肩,有时甚至更好。
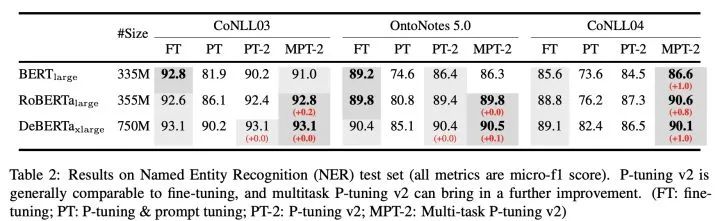
本文介绍了一种“优化升级”的Prompt Tuning方法——P-tuning v2,其主要贡献是:
看完上述解读后,不难发现(划重点):P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。
此外,P-tuning v2还未在few-shot上验证性能,有待进一步验证。
参考资料
[1] GPT Understands, Too: https://arxiv.org/pdf/2004.13454

扫码观看!
本周上新!

“AI技术流”原创投稿计划
TechBeat是由将门创投建立的AI学习社区(www.techbeat.net)。社区上线330+期talk视频,900+篇技术干货文章,方向覆盖CV/NLP/ML/Robotis等;每月定期举办顶会及其他线上交流活动,不定期举办技术人线下聚会交流活动。我们正在努力成为AI人才喜爱的高质量、知识型交流平台,希望为AI人才打造更专业的服务和体验,加速并陪伴其成长。
投稿内容
// 最新技术解读/系统性知识分享 //
// 前沿资讯解说/心得经历讲述 //
投稿须知
稿件需要为原创文章,并标明作者信息。
我们会选择部分在深度技术解析及科研心得方向,
对用户启发更大的文章,做原创性内容奖励。
投稿方式
发送邮件到
chenhongyuan@thejiangmen.com
或添加工作人员微信(chemn493)投稿,沟通投稿详情;还可以关注“将门创投”公众号,后台回复“投稿”二字,获得投稿说明。

>> 投稿请添加工作人员微信!
关于我“门”
▼

点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球