IJCAI 2021 | 课程对比图表示学习
以下文章来源于北邮 GAMMA Lab ,作者楚贯一
北邮图数据挖掘与机器学习实验室

题目:课程对比图表示学习
会议:IJCAI 2021论文链接: http://www.shichuan.org/doc/111.pdf 论文代码: https://github.com/BUPT-GAMMA/CuCo

一、引言
图结构数据,如社交网络、蛋白质相互作用机制和金融网络,在现实世界场景中无处不在。最近,人们普遍认识到,图数据的适当表示对于统计或机器学习模型的学习性能至关重要,因此,在学习低维表示模型方面前人已经做了大量的工作。迄今为止,图表示学习在社交网络分析和推荐系统等领域取得了显著的成功。目前大多数图表示学习方法都是针对单个图的节点级表示进行学习。然而,在实践应用中,各种应用需要提取整个图的表示,例如在药物和材料发现中预测分子特性,以及在生物网络中预测蛋白质功能。因此,近年来,图级表示学习也吸引了大量的关注。这些方法设计了一种消息传递和聚合算法来获得节点嵌入,然后使用池化机制以有监督的方式获得整个图的表示。
然而,在许多实际应用中,标签数据是非常有限和昂贵的。例如,在化学领域,标签的获取通常采用昂贵的密度泛函理论计算。因此,以无监督或自监督的方式学习整个图的表示变得越来越重要。最近,在自然语言处理和计算机视觉领域取得巨大成功的背景下,基于自监督对比学习的图级表示学习受到了广泛关注。具体来说,这些方法的基本思想是,使用对比损失将来自同一实例的正样本对映射到彼此接近的位置,而来自不同实例的负样本对嵌入到彼此远离的位置,从而产生强大的可迁移表示。
在将对比学习应用于图时,需要仔细考虑两个关键问题:一个是如何在图上构造正样本对,另一个是如何有效地选择和训练负样本对。这两个因素在本质上决定了图对比学习的成功。目前的大多数工作都集中在如何构造正样本对上,并设计不同的图增广策略,如子图扩展等。然而,在如何有效的负样本选择和训练策略方面几乎没有做出什么进步,而事实上,如何有效地处理负样本对对比学习的泛化性能至关重要。这一要求非常具有挑战性,因为在对比学习环境中,标签信息是未知的,因此不可能采用现有的使用标签信息的负采样策略。目前,大多数对比方法都是在训练过程中随机选取负样本。然而,不同的负样本在训练中发挥着不同的作用,产生着不同的影响。具体来说,对于一个特定的样本,其负样本的难度是不同的,并且这些负样本在不同的训练周期中发挥着不同的作用。例如,较困难的负样本在训练后期起着重要作用。因此,我们需要根据训练过程中的困难考虑采样负样本的顺序,特别是在没有标签信息的情况下,这一问题变得更具挑战性。
在本文中,我们试图解决上述挑战——通过提出一个用于图形级表示的课程对比学习框架来解决这一问题。特别地,我们首先介绍了四种用于构造正样本对的图扩充,并使用评分函数来度量训练数据集中负样本的难度。效仿人类的学习过程,我们在学习新模型时应从简单样本开始,然后逐步学习困难样本。因此,我们将负样本从简单到困难进行排序。此外,我们还设计了一个步长函数来规划如何将负样本引入训练过程。最后,我们利用一个流行的对比损失函数来优化我们的模型。与目前最先进的自监督图级表示学习方法相比,我们的方法不仅取得了更好的整体性能,而且减少了训练时间。
我们的贡献总结如下:
· 我们首次尝试研究了负样本对学习图级表示的影响,这在以前的工作中基本上被忽略了,但对于良好的自监督图级表示学习来说非常实用和重要。
· 我们提出了一种新的基于课程对比学习的图表示学习模型。我们的模型有效地结合了课程学习和对比学习,能够以人类学习的方式自动选择和训练负样本。
· 我们进行了全面的实验,结果表明,所提出的方法在15个数据集上提高了下游任务的收敛速度和泛化性能。
二、模型方法
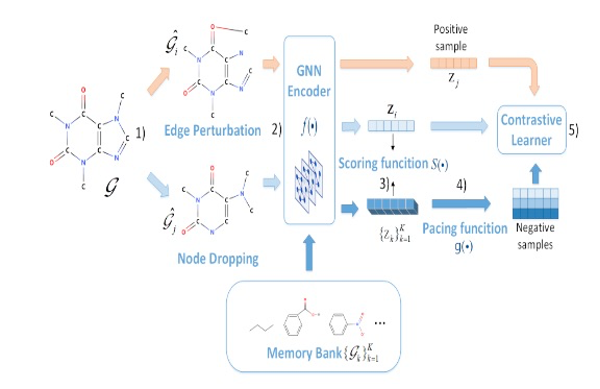
模型纵览
1. 通过图增广得到正样本
2. 得到每个图的嵌入表示
3. 用评分函数对负样本进行排序
4. 用步长函数指定在每一步中使用的memory bank的大小
5. 用梯度下降法优化目标函数
模型的主要目标是训练一个GNN编码器与课程学习为基础的负采样策略。如图1所示,给定一个图 ,我们首先利用图增广技术得到正对 .这里我们使用训练集中除 以外的所有其他图作为负样本 ,称为memory bank。然后我们利用图神经网络分别学习它们的表示 。此后,我们使用评分函数 测量负样本的难度,并将负样本从易到难排序。接下来使用步长函数 规划如何将负样本引入训练过程。最后,利用对比学习器采用梯度下降法来优化GNN的参数。
问题定义。给定一个无向图 其中 表示一组 节点, 表示邻接矩阵,其中节点特征矩阵为 其中是节点 的 维属性向量, 对于自监督图表示学习,给定一组未标记图 我们的目标是对每个图 ,在数据本身的指导下,学习一个 维向量 。
2.1 图增广方法
我们知道,在没有任何数据增强的情况下,对比学习与原始训练损失相比,没有增益,甚至往往更糟。数据增广旨在通过应用某些转换而不影响语义标签来创建新的且合理的数据。我们关注于图级别的增广。具体来说,给定图数据集中M个图 ,我们定义了增广图 满足:,其中 是以原始图为条件的增广分布,代表数据分布的人类先验。通常,有四种基本的数据增广策略来构建正样本对图:
1. 节点丢弃,随机丢弃部分节点及其连接;
2. 边扰动,通过随机增加或减少一定比例的边来扰乱 中的连通性;
3. 属性遮蔽,鼓励模型使用上下文信息恢复被遮蔽的节点属性;
4. 使用随机游走从 中采样子图。
给定的图 进行图数据增强以获得两个相关视图 , 作为正对,其中 , 。此外,尽管训练集中的任何其他图都可以视为与 的负对,但大多数对比方法只是随机选择负样本。然而,如何选择负样本很重要,我们将在第二节讨论。对于图数据集的不同领域,我们策略性地选择数据增广方式。具体来说,对于化学和生物大分子,我们采用两种增广策略:节点删除和子图;对于社交网络,我们使用所有四种数据增广策略。
2.2 图编码器
在我们获得正增强图对后,即 和 ,我们需要学习它们的表示。尽管我们的方法允许网络架构的各种选择而没有任何限制,但在这里我们使用图神经网络(GNN)作为图编码器。接下来我们以 为例介绍基于GNN的学习过程,这个过程和 是一样的。
给定一个无向图 和其节点特征矩阵其中是节点特征矩阵的 维属性向量。考虑一个 层 GNN ,第 层的传播表示为:
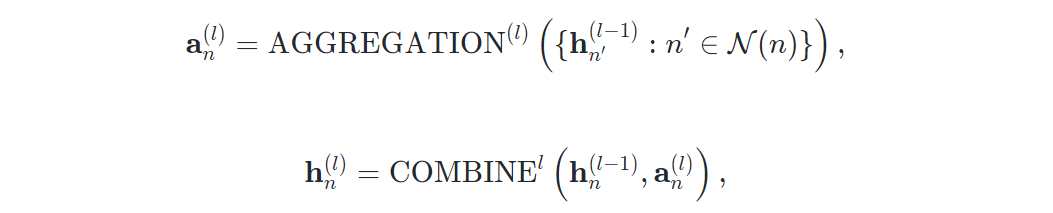
其中 是节点 在第 层的嵌入,且 , 是与 相邻的一组节点,和 是 GNN 层的组合函数。在 层传播之后,对于 ,通过 READOUT函数输出为层嵌入 。之后对与图级下游任务(分类或回归),采用多层感知器(MLP)得到表示:
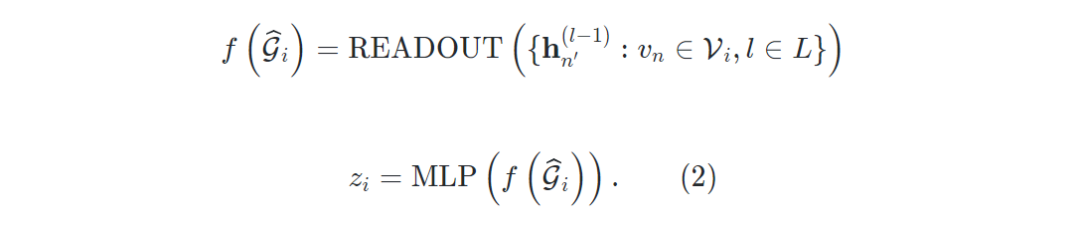
2.3 带有记忆库的对比学习
为了强制最大化正对 ,与负对之间的一致性,我们采用噪声对比估计损失。具体来说,我们定义了一个"记忆库" ,它包含 K个负样本嵌入 对于每个正对 ,然后我们使用相似度度量函数 计算正对,,和负对 的相似度。基于此,损失函数如下:
其中 表示温度参数。最小化Eq.(3)意味着我们强制正对分数高于记忆库中的负对分数。
为了简化计算,我们使用点积作为相似度度量函数。Eq(3)的对数似然函数定义在通过为每个 应用softmax函数创建的概率分布上。设为和其他样本 的匹配概率,则损失函数相对于 的梯度为:

其中
2.3.1 负采样的课程设置
显然,模型需要从模型的记忆库中进行负采样。下面将介绍一种新颖的基于课程学习的负采样方法。主要思想是在训练期间根据难度对负样本进行排序。一般来说,课程学习是通过指定三个要素来定义的:评分函数、步长函数和课程顺序。
2.3.2 评分函数
在这里,在我们的记忆库中,我们有 K 个不同难度的负嵌入 。之后,我们定义了一个评分函数,它将负嵌入 映射到数值评分 ,以衡量这种难度。通常,较高的分数对应于更难的负嵌入。我们可以将评分函数 设置为来返回负嵌入难度的度量,因为根据Eq(3),评分函数值越高,的损失也变高。这意味着 是一个更难的负嵌入。具体来说,我们基于嵌入的相似度,使用两个常见的评分函数:
· 余弦相似度: 它使用两个向量之间夹角的余弦值来衡量相似度。
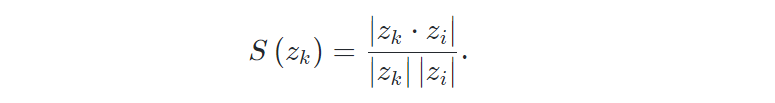
· 点积相似度 : 与余弦相似度相反,点积与向量长度成正比。
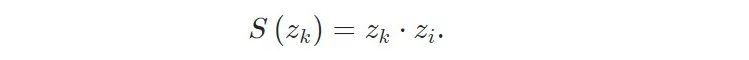
2.3.3 步长函数
在我们获得记忆库中每个负嵌入 的分数 后,我们使用步长函数来调度如何将负样本引入训练过程。步长函数 指定在每个步骤 t 使用的存储库的大小。步骤 t 的存储库由 个得分最低的样本组成。负样本批次从该集合中均匀采样。我们用 K 表示完整的内存库大小,用 T表示训练步骤的总数。这里我们考虑四个常见的函数系列:对数函数、线性函数、二次函数和平方根函数。
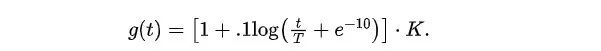

其中 是一个平滑参数,用于控制训练过程中的步长。 分别表示平方根、线性和二次函数。
2.3.4 课程顺序
为了限制使用基于难度级别的评分函数的具体影响,我们指定了课程的顺序(从最低分到最高分排序),反课程(从最高分到最低分排序),或随机。
2.3.5 早停机制
在训练后期,随着负样本难度的增加,与具有相同标签的假负样本的比例会增加,假负样本会损害模型的泛化性能。
为了缓解这个问题,我们设计了一个提前停止机制。具体来说,我们定义了提前停止的超参数p。当损失不再下降时,p 值开始降低。
一旦 p 变为 0,训练就会停止。
2.3.6 模型优化
CuCo训练期间,使用在线更新的图嵌入,我们根据评分函数 按难度对负嵌入进行排序,然后根据步长函数 对负样本进行采样。
在每次迭代中,使用目标函数 通过梯度下降优化 GNN的参数。如果目标不再减少,则值 p 开始在每次迭代时减少 1。一旦耐心值 p变为 0 或 epoch t 达到最后一次迭代 ,训练将停止。
三、实验
在本节中,为了表明我们的自监督模型 CuCo可以快速而良好地学习图表示,我们将我们的模型与无监督和迁移学习中的最先进方法(SOTA)进行图分类任务的比较。
3.1 无监督学习

使用下游图分类任务评估无监督图级表示的结果显示在表2 中。虽然两种图核方法在单个数据集上表现良好,但它们都没有在所有数据集上具有竞争力。我们发现 CuCo 在 7 个数据集中的 6 个中优于所有这些基线。在另一个数据集 NCI1 中,CuCo 仍然具有非常有竞争力的表现。
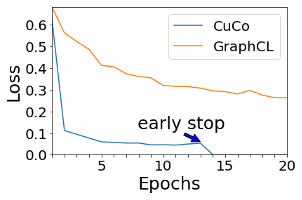
我们还研究了CuCo对收敛速度的增益。为了公平起见,我们将 CuCo 与 GraphCL进行比较,因为我们的方法和 GraphCL 采用相同的图增强和 GNN 架构。由于我们的提前停止机制和有序学习,如图 2所示,我们的方法导致了更快的收敛速度:我们的负采样只需要 13 到 14 个epoch 即可在中达到比 GraphCL 20 个 epoch更好的性能,这将时间成本减少了约40 %。
3.2 迁移学习
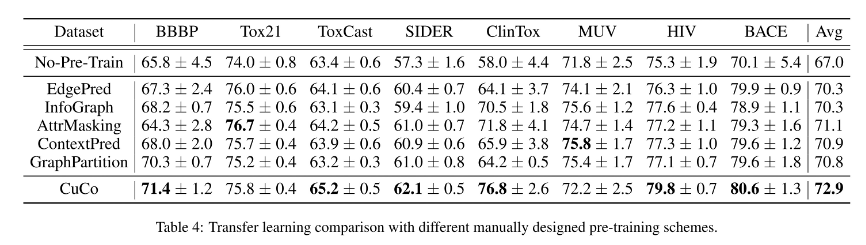
我们对化学中的分子特性预测和生物学中的蛋白质功能预测进行迁移学习,在不同的数据集中对模型进行预训练和微调,以评估预训练模型的可迁移性。我们使用下游任务的一小部分标签对预训练的 GNN 模型进行微调。表4报告了所提出的 CuCo 方法与转移学习设置中的其他工作相比的性能。在所有自监督学习策略中,我们的方法在平均性能上优于所有基线,并在八个数据集中的六个数据集上取得了最好的结果。我们相对于非预训练基线获得了 5% 的性能提升,这很好地表明了我们提出的CuCo 在迁移学习方面的有效性。
四、结论
在本文中,笔者研究了负样本对学习图级表示的影响,并提出了一种名为 CuCo的自监督图级表示的新型课程对比学习框架。笔者研究了使用评分函数和步长函数将难度与负样本相关联的各种调度策略的不同方法,以此将不同难度的负样本引入自监督训练过程。笔者进行了全面的实验,结果表明所提出的方法在 15个数据集上提高了下游收敛速度和性能。
本文来自:公众号【北邮GAMMA Lab】
作者:楚贯一
Illustrastion by Anna Antipina from Icons8

扫码观看!
本周上新!


11.22(周一)
11.23(周二)
11.23(周二)
11.24(周三)
11.25(周四)
11.28(周日)
11.30(周二)
11.30(周二)
淘系技术直播③内容新电商
关于我“门”
▼

点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球