EMNLP 2021 | 字节火山翻译:嫁接BERT与GPT的多语言机器翻译
 本文是针对上周字节跳动算法工程师孙泽维的Talk视频——连接BERT与GPT的多语言机器翻译的工作解读,欢迎阅读文章并观看Talk视频~
本文是针对上周字节跳动算法工程师孙泽维的Talk视频——连接BERT与GPT的多语言机器翻译的工作解读,欢迎阅读文章并观看Talk视频~

论文地址: https://aclanthology.org/2021.findings-emnlp.233
代码地址:https://github.com/sunzewei2715/Graformer Talk解读:
https://www.techbeat.net/talk-info?id=611

试想,一个完全不会德语和法语的人,光靠德法双语的词典和教科书,就要将一篇德语文章翻译成法语,一定很困难。但如果让一个德国人和法国人来共同完成这个任务,即便他们都只会一种语言,练上一段时间,也能完成得不错。
脑洞更大一些,如果是外星人要学习地球语言的相互翻译,即便给他们联合国文件的平行语料,也困难重重。但如果是各个国家的母语者联合起来,通过一些对齐的语料学习翻译,应该比外星朋友们有优势多了。
机器翻译的训练依赖双语平行数据,但这种数据相对稀少,且不易获得,因此如何利用好海量单语数据是机器翻译领域的重要课题。
近年来,一系列预训练语言模型,如 BERT[1]、GPT-2[2] 等都在 NLP 领域取得了令人瞩目的性能,刷新了一大批 SOTA 数据。其自监督训练的方法能在大规模单语数据上获取强大的知识与表示,帮助下游任务提升表现。预训练语言模型最典型的两个工作 BERT 与 GPT ,其结构刚好分别对应 Transformer 模型的 Encoder 与 Decoder,也对应自然语言的理解 (Understanding) 与生成 (Generation)。
一个很直接的问题就是:我们能否通过嫁接一个强大的预训练 BERT 与一个强大的预训练 GPT ,合成一个 Transformer 模型,完成 Seq2seq 任务呢?
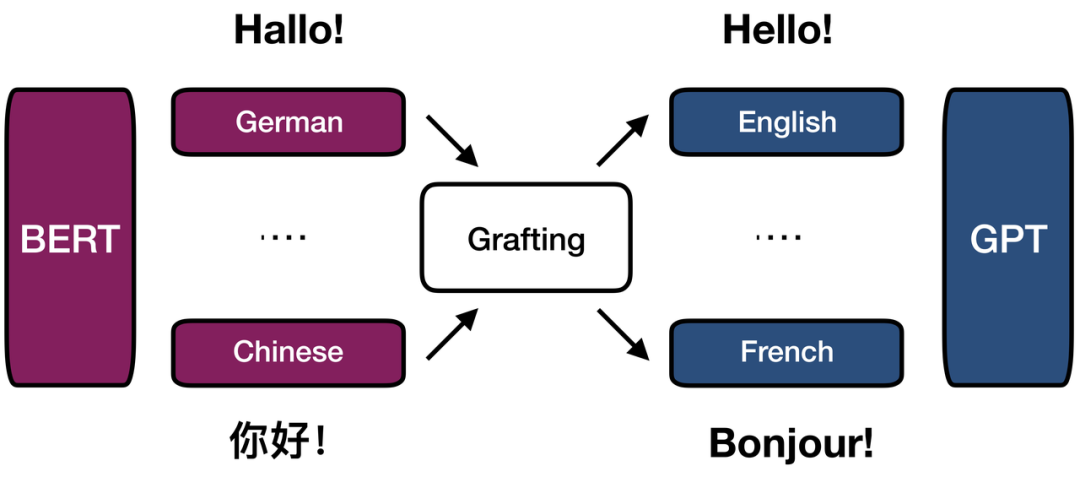
例如,我们能否嫁接中文 BERT 与英文 GPT,通过对中间部分模块的 tuning,获得一个中英翻译模型呢?甚至更进一步,如图1所示,如果我们有一个多语言 BERT 和多语言 GPT,能否通过简单的 tuning 获得一个强大的多语言模型呢?
二、问题难点
这个思路很直接,但有一个比较棘手的问题。虽然 BERT-like pretrained model 与 Transformer Encoder 的结构基本一致,但GPT-like pretrained-model 与Transformer Decoder存在模型结构上的差异。
如图2所示,预训练语言模型只有两个模块:Self Attention 与 Feed-forward Network。而Transformer Decoder中间还有一个子模块:Cross Attention,用于捕捉源端的context。BERT/GPT类的模型由于是在单语进行预训练,没有这个模块。这个结构的差异给载入相关参数带来了障碍。
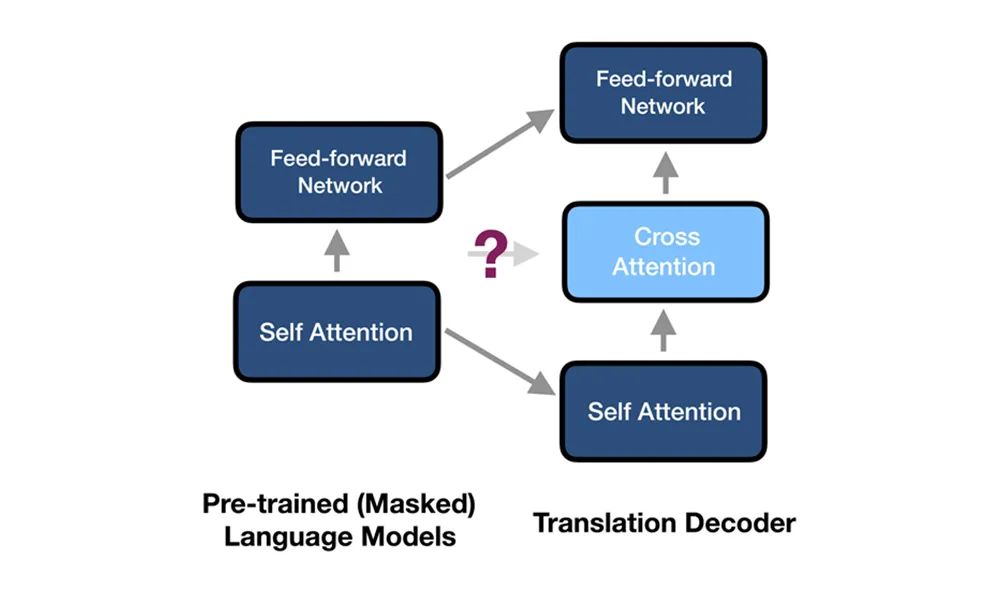
图2:预训练语言模型与翻译模型的结构差异
有相关的工作[3,4]尝试解决这个问题,大致思路就是保留 Cross Attention 的模块(相当于在 BERT/GPT 内额外插入),之后要么只载入 Self Attention 与 FFN 的参数,Cross Attention 的部分随机初始化,然后整体重新 tune。部分工作还会增加 adapter 的模块[5]。
然而这样的操作,改变了预训练语言模型的原始架构(如图3所示,实线path变成了虚线path),使得预训练好的 BERT/GPT 被打破重组,必须重新tune。在下游的翻译任务中,这很容易导致预训练知识的遗忘 (Forgetting),限制了最终的性能提升。
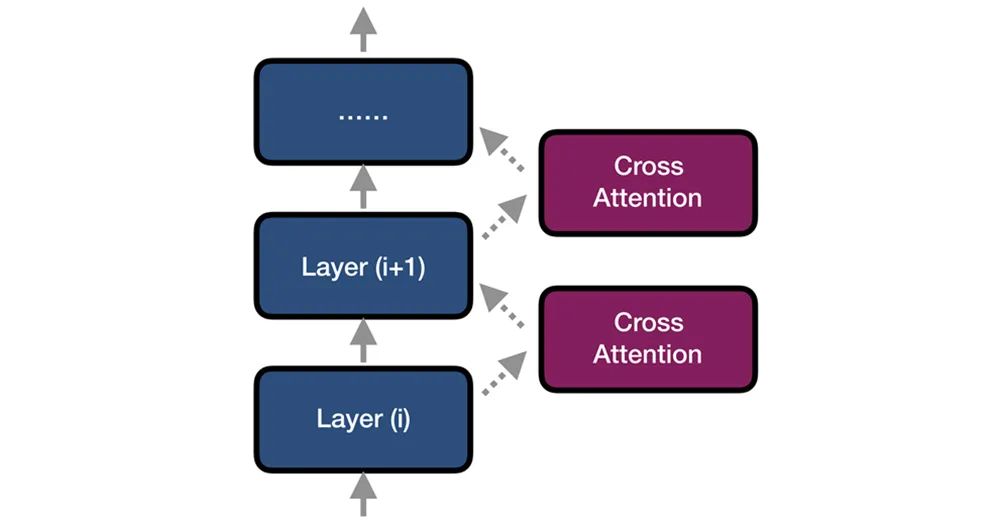
图3:额外的 Cross Attention 对模型结构的改变
三、方法
对此,我们提出了与以往研究不同的思路,不将 Cross Attention 模块插入到预训练语言模型的内部,而是叠加在其上层,如图4所示。
我们将这种拼接 BERT、GPT,并叠加 Cross Attention 的方法称为 「嫁接」(Grafting),将整个模型称为 Graformer (Grafting Transformer)。
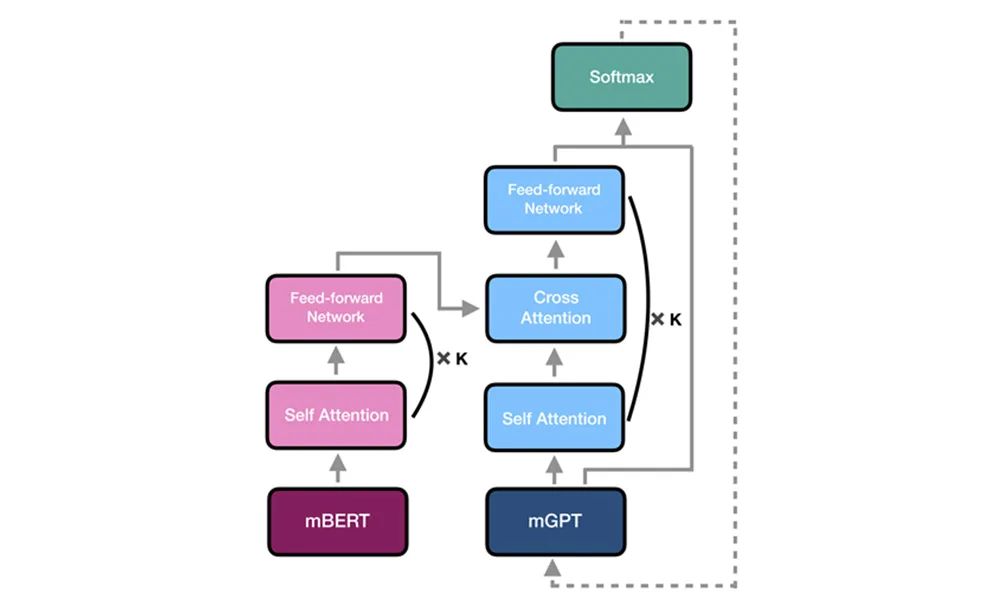
图4:Graformer 的结构示意图
我们在多语言翻译的任务上设置了 many-to-many translation 的实验。
主实验
如表1,2所示,我们在x–>en的语向上平均取得了5.8个 BLEU 的提升,在en–>x的语向上取得了2.9个 BLEU 的提升。我们同时也比较了 mBART[6],一个知名的预训练方法。我们使用了其1/5的预训练数据,但取得了比它更高的性能。
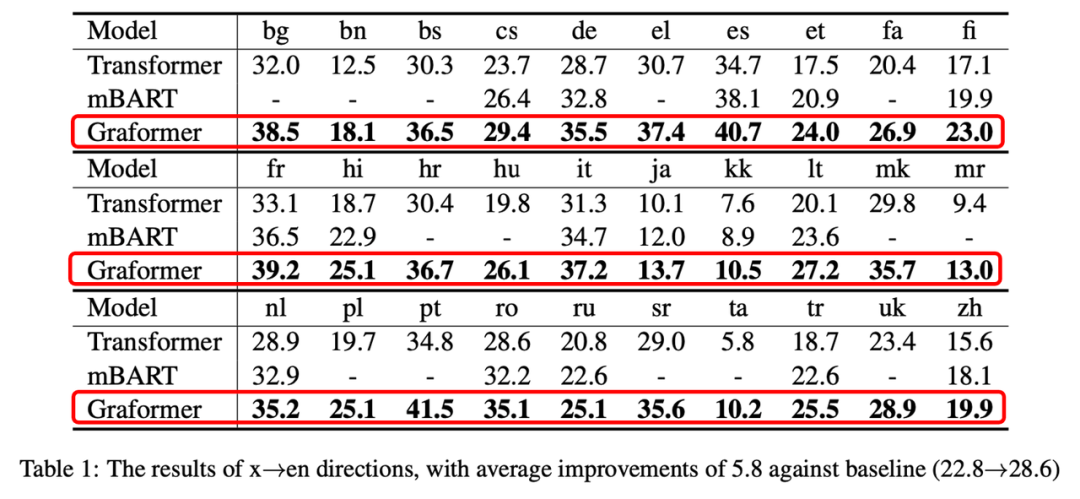
表1:Graformer在x–>en语向上平均提升5.8
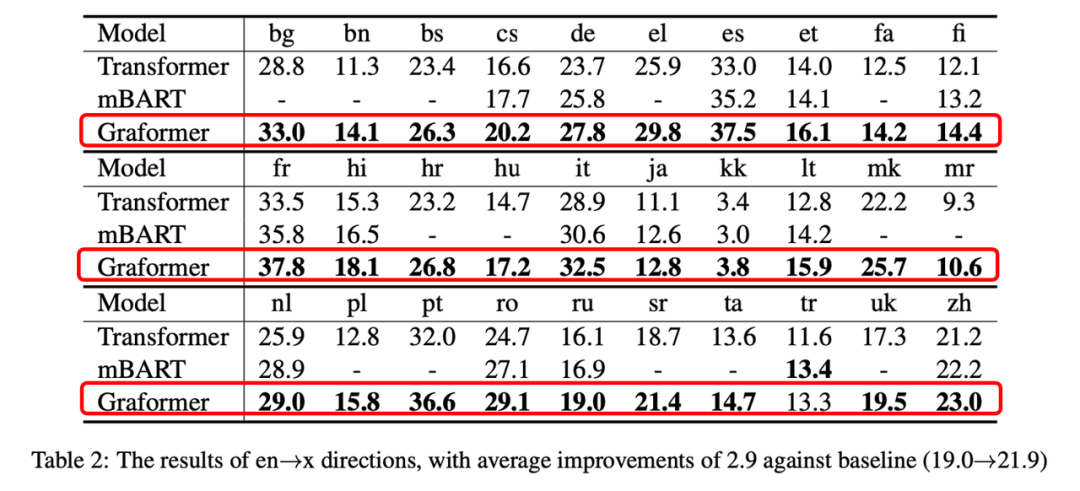
表2:Graformer在x–>en语向上平均提升2.9
对比实验
我们也对比了其他几个相关的工作,如图5所示,可以得到两个结论:
1. 比起两个相关工作[3,5](人工插入Cross Attention类方法),在同等层数与参数量的前提下,Graformer 能取得更高的提升,说明了我们保留预训练语言模型完整的重要性。
2. 将 pre-trained GPT 结果与翻译模型结合的 Residual 操作能进一步提升模型能力,也说明了预训练生成模型对翻译的正面影响。
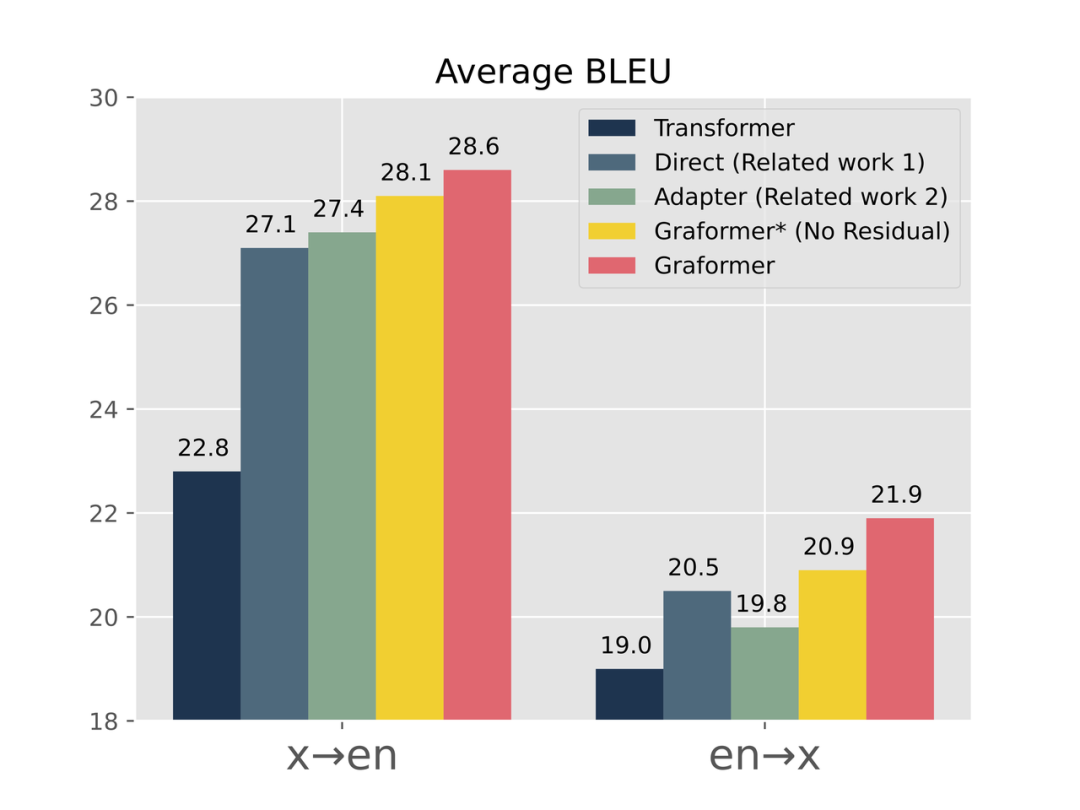
图5:Graformer在BLEU上显著好于其他工作
同时,我们也查看了模型的Perplexity,如图6所示,依旧能得到两个类似的结论:
1. Graformer 因为保留了更完整的GPT,在生成的文本上更加通顺(Perplexity低)。
2. Residual 的操作的确能让GPT的生成能力帮助到最后的结果。
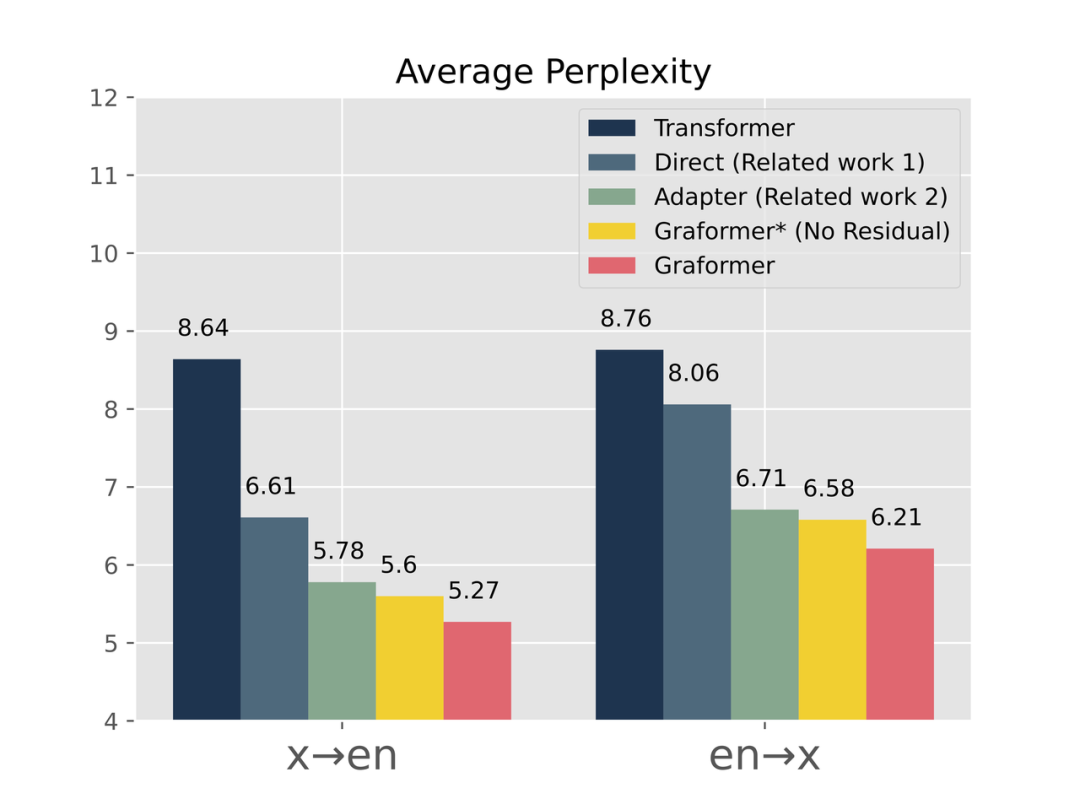
图6:Graformer在Perplexity上显著优于其他工作
消融实验
我们还做了一些Ablation Study,有关对预训练语言模型部分是否 tuning 的实验,如图7所示,我们可以得到三个结论:
1. Pre-trained Encoder 需要 Tuning。
2. Pre-trained Decoder 需要 Freeze。
3. Pre-trained Decoder 比 Pre-trained Encoder 更加重要些。
其中的2和3再次说明了保持Pre-trained GPT完整的重要性。
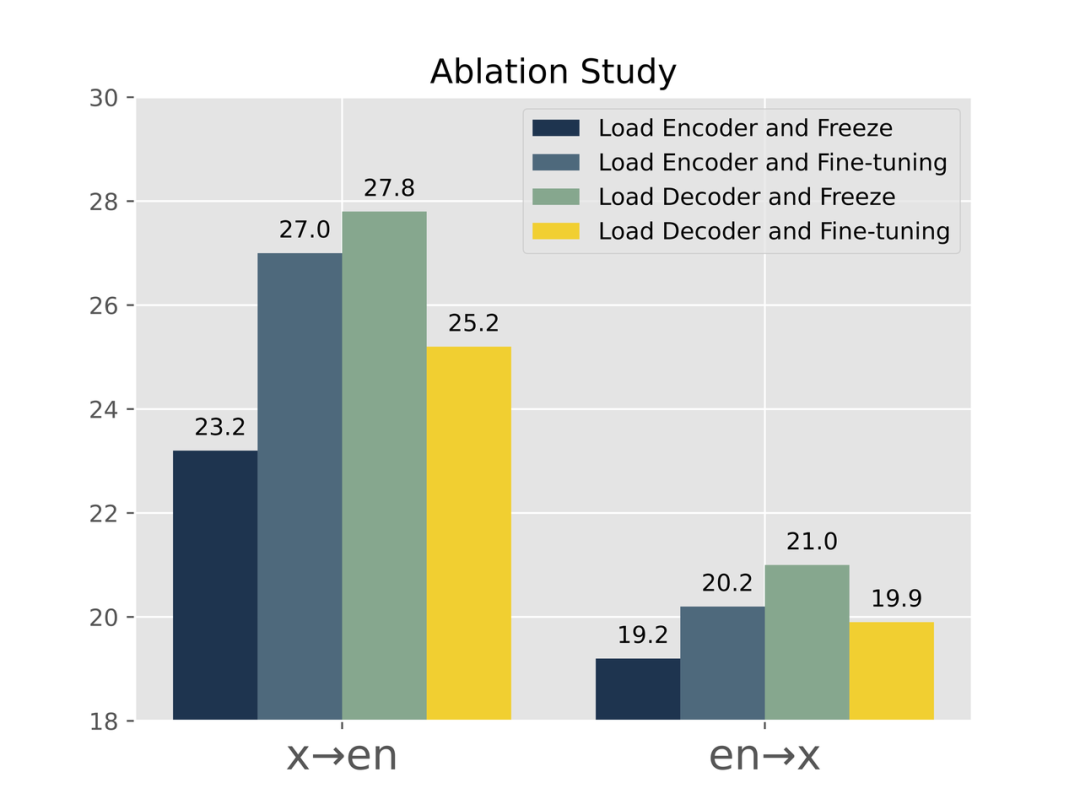
图7:对Pre-trained encoder & decoder的消融实验结果
少资源翻译
我们还研究了 Few-shot Translation 的场景。如图8所示,横坐标是翻译训练的数据量,随着数据量的减少,Baseline 的模型有个显著的下降,而 Graformer 仍能维持在相对较高的水平。
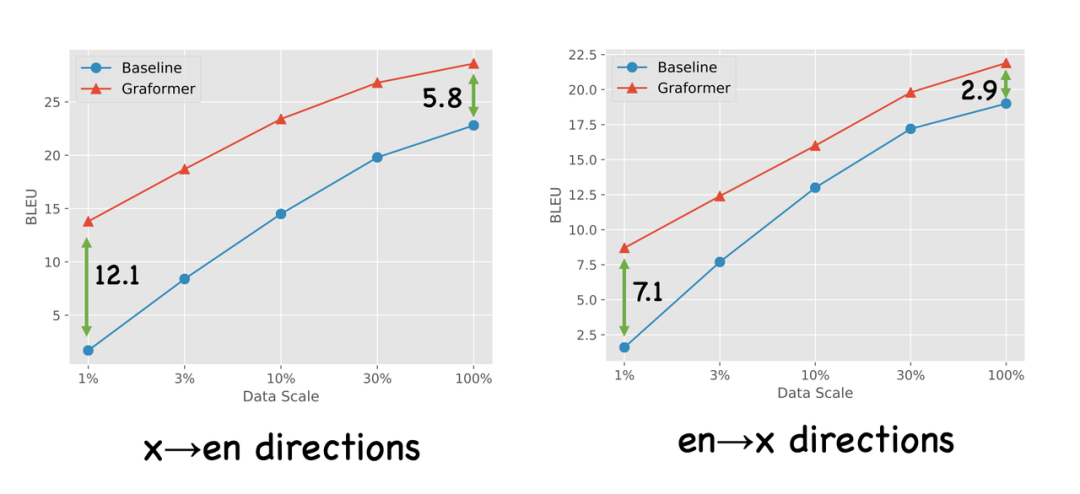
图8:Graformer在Few-shot场景下优势明显
另一个有趣的实验如图9所示,每个点代表一个语种(en–>x的x),横坐标是其「预训练单语量」与「翻译训练双语量」的比值,纵坐标是相对Baseline的提升。
可以看到,相对双语的单语量越大,模型的提升量越大。这充分说明了 Graformer 的潜力,因为我们可以获得海量的单语语料。
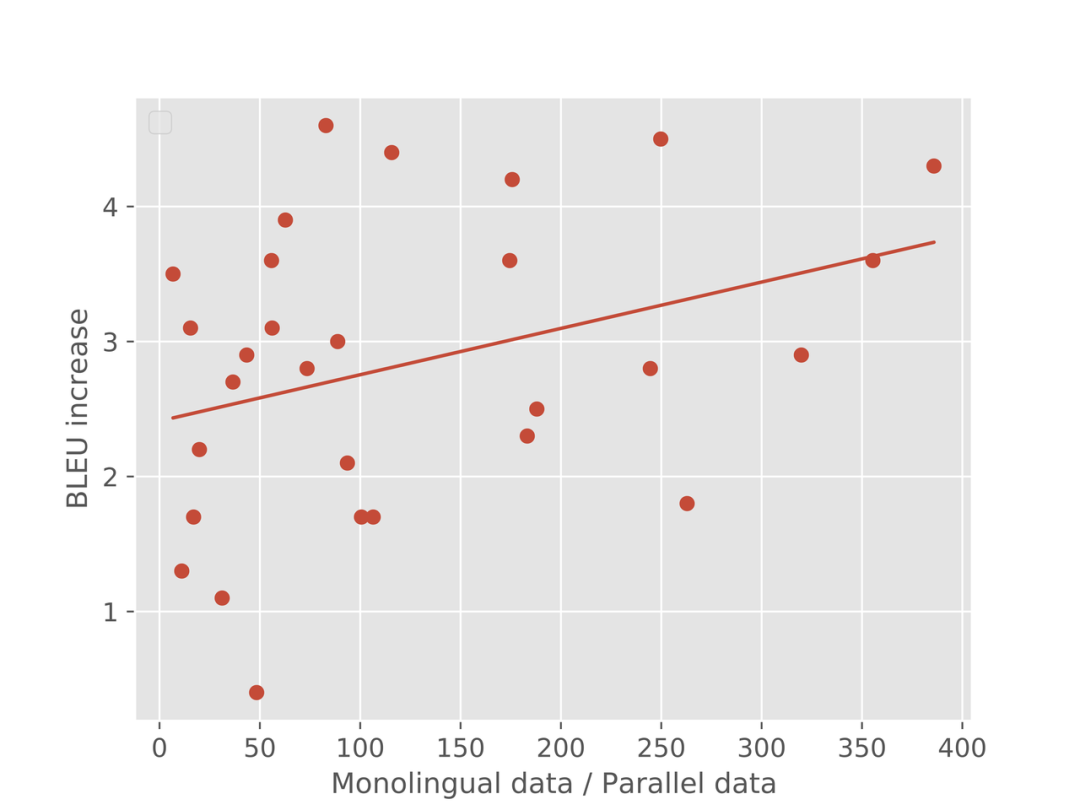
图9:随着单语相对量越大,BLEU提升越大
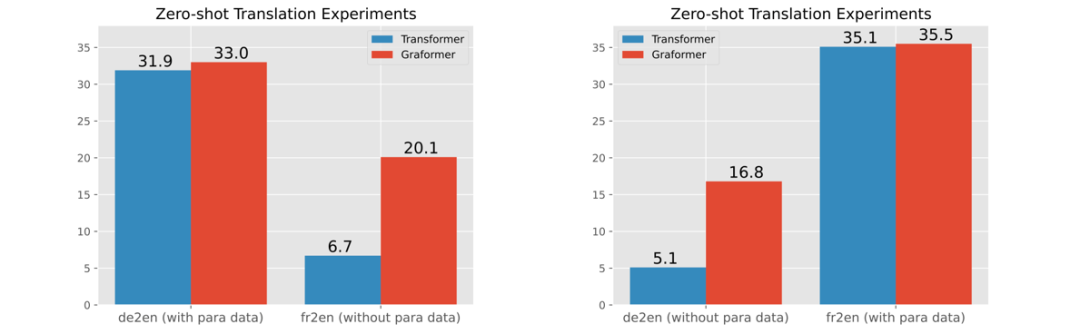
零资源翻译
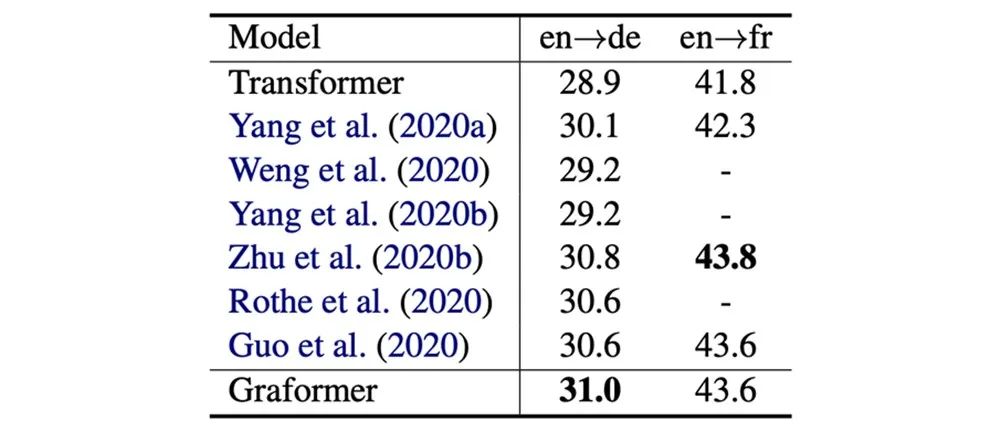
1. 我们提出了嫁接式模型Graformer,利用 BERT/GPT 等预训练语言模型,在多语言翻译等多个翻译场景取得了显著的提升。
2. 我们通过各类实验论证了:完整保留预训练语言模型、充分利用预训练得到的表示与知识,是很重要的。
//

孙泽维
参考文献
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT.
[2] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners.
[3] Sascha Rothe, Shashi Narayan, and Aliaksei Severyn. 2020. Leveraging Pre-trained Checkpoints for Sequence Generation Tasks. TACL.
[4] Shuming Ma, Jian Yang, Haoyang Huang, Zewen Chi, Li Dong, Dongdong Zhang, Hany Hassan Awadalla, Alexandre Muzio, Akiko Eriguchi, Saksham Singhal, Xia Song, Arul Menezes, Furu Wei. 2020. XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders. arXiv preprint arXiv:2012.15547.
[5] Junliang Guo, Zhirui Zhang, Linli Xu, Hao-Ran Wei, Boxing Chen, and Enhong Chen. 2020. Incorporating BERT into Parallel Sequence Decoding with Adapters. In NeurIPS.
[6] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual Denoising Pre-training for Neural Machine Translation. TACL.
作者:孙泽维
Illustrastion by WOOBRO LTD

扫码观看!
本周上新!


12.14(周二)
12.15(周三)
12.15(周三)
12.16(周四)
12.16(周四)
关于我“门”
▼

点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球