NeurIPS 2021 | 基于SE(3) 等变性的自监督类别级物体姿态估计(代码已开源)
以下文章来源于北京大学前沿计算研究中心 ,作者CFCS EPIC
北京大学前沿计算研究中心(Center on Frontiers of Computing Studies, PKU)官方公众号


物体的六维位姿估计是重要的计算机视觉和机器人学课题,目标在于求取物体在三维空间中相对于物体自身坐标系的三维旋转和三维平移。由于六维位姿的定义依赖物体自身的参考系,经典的六维物体位姿估计算法主要处理训练中见过的物体而无法估计未见过物体的位姿。随着对视觉和机器人任务研究的不断深入,AR/VR 及机器人与物体的物理交互等任务都对位姿估计的可泛化性提出了新的要求。
2019年 CVPR oral 文章 NOCS [2] 通过定义类别级物体参考系,开类别级的物体六维位姿估计之先河。这样训练获得的模型不仅仅在见过的物体上有很好的预测性能,对于同一类上的物体也能够去估计,最近以来也产生了不少令人鼓舞的拓展研究。但是相比与其他的任务,类别级的位姿估计一般都需要大量的有标注的数据,而众所周知六维位姿标注繁琐且非常昂贵,使得这一方法很难在推广到数目繁多的物体类别上。
在这篇文章中,我们将探索如何在没有位姿标注的情况下,对物体点云输入进行类别级物体位姿估计,亦即自监督学习。我们的方法基于对 SE(3) 操作等变的点云网络,实现了无需位姿标注、无需物体 CAD 模型、无需多视角输入或监督的类别级物体位姿自监督学习。我们的方法既可以适用于完整点云,也可以适用于单目的深度图点云,并在多个数据集上有良好表现。


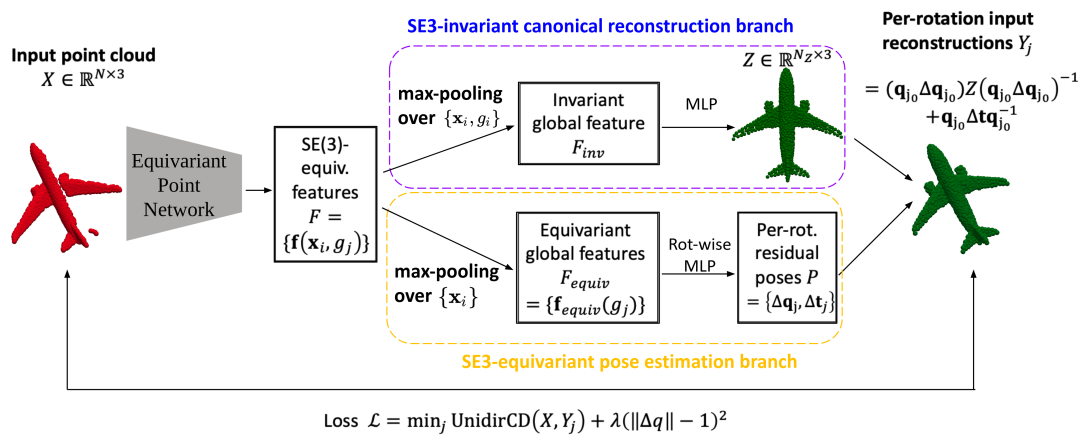
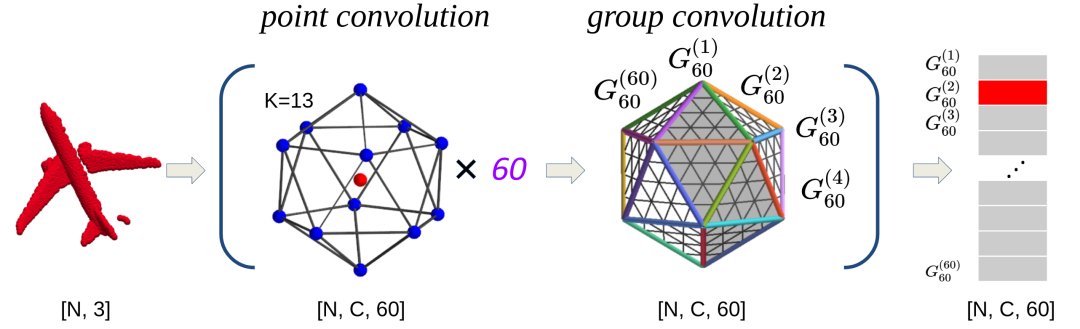
对平移变换严格等变; 对旋转变换在 群的一个60阶有限子群(正二十面体群 )严格等变图; 因此对一般 变换近似等变。
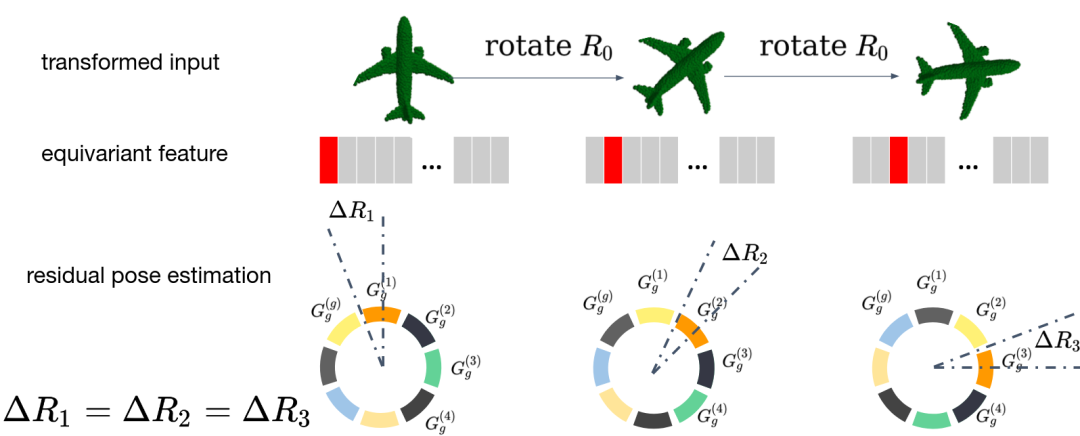
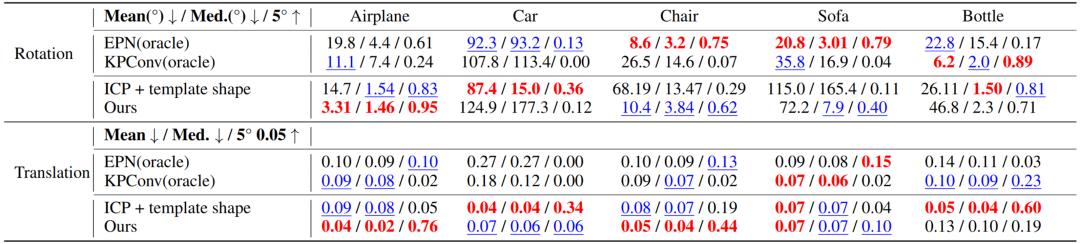
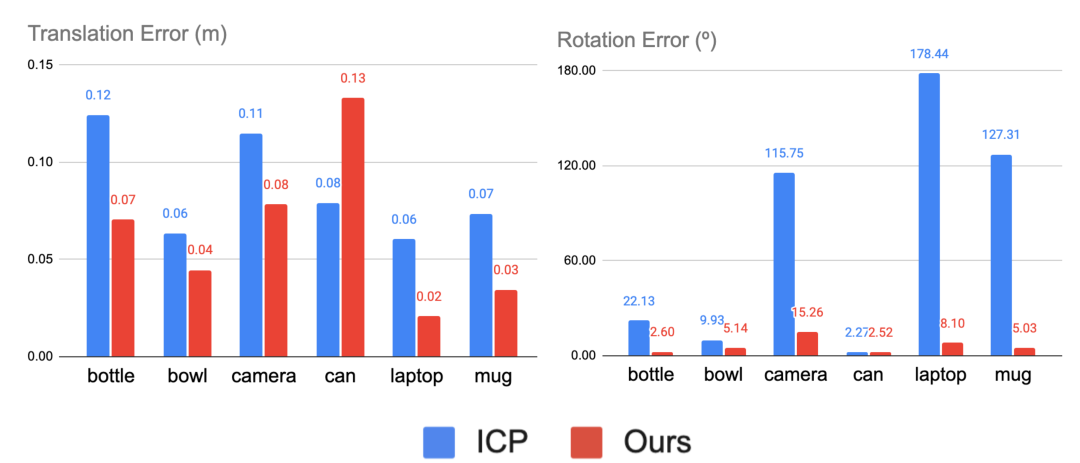
我们的方法在 ModelNet40 的合成数据集以及类级别刚性物体位姿估计真实数据集 NOCS-REAL275 [2] 均进行了测试,效果均超过了作为对照的无监督方法,并且在部分类别上超越了有监督的方法。这里我们列出部分结果和可视化如下。
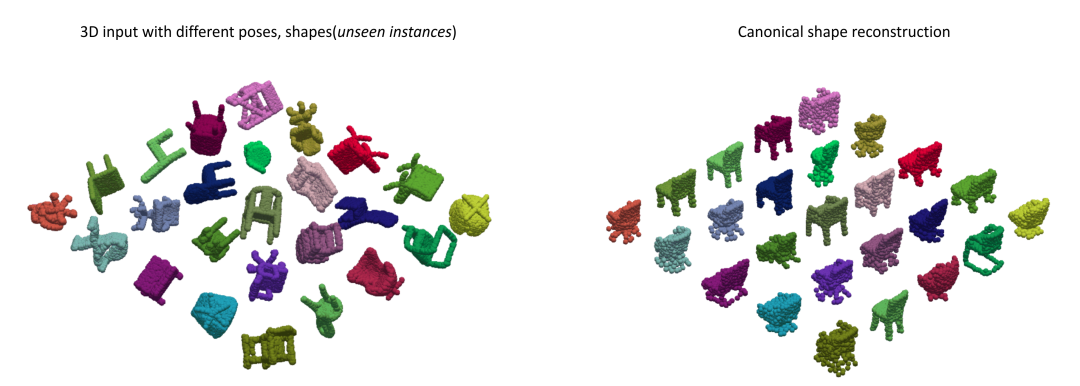
完整点云输入下自监督的正规重建与三维旋转估计:

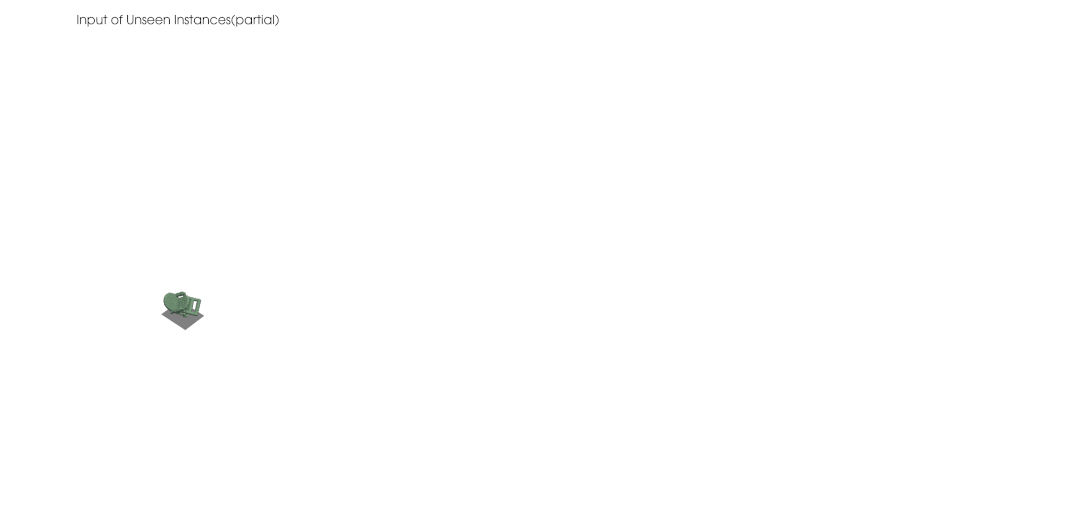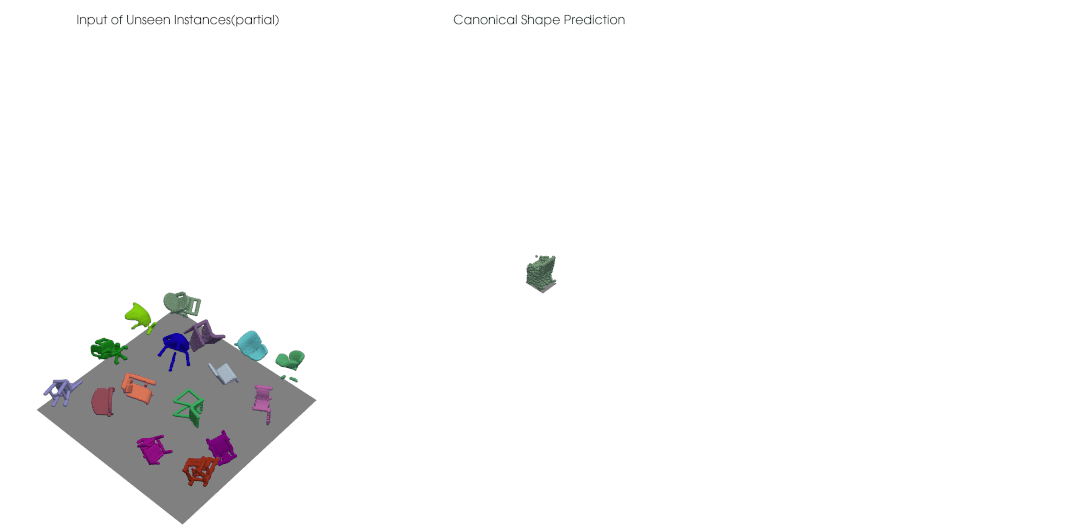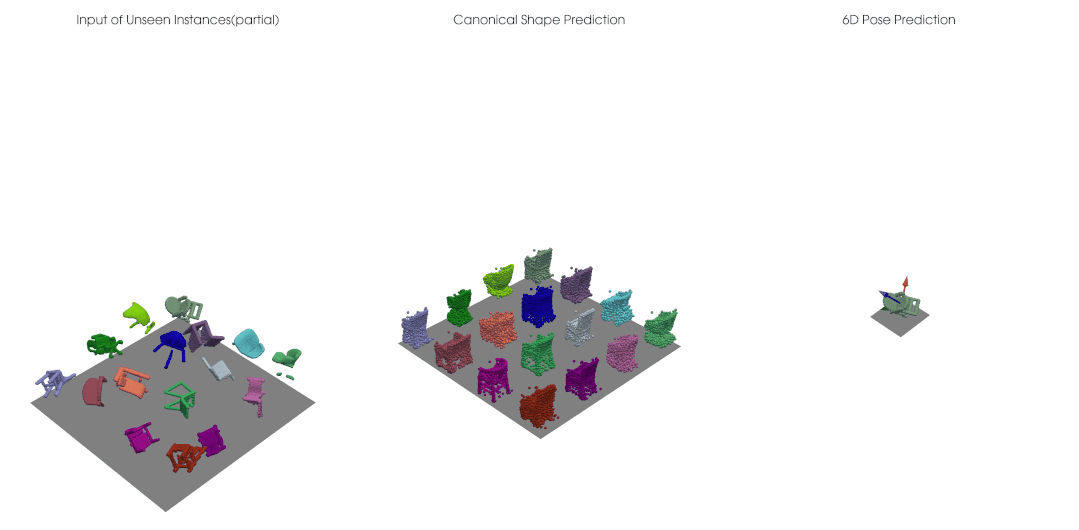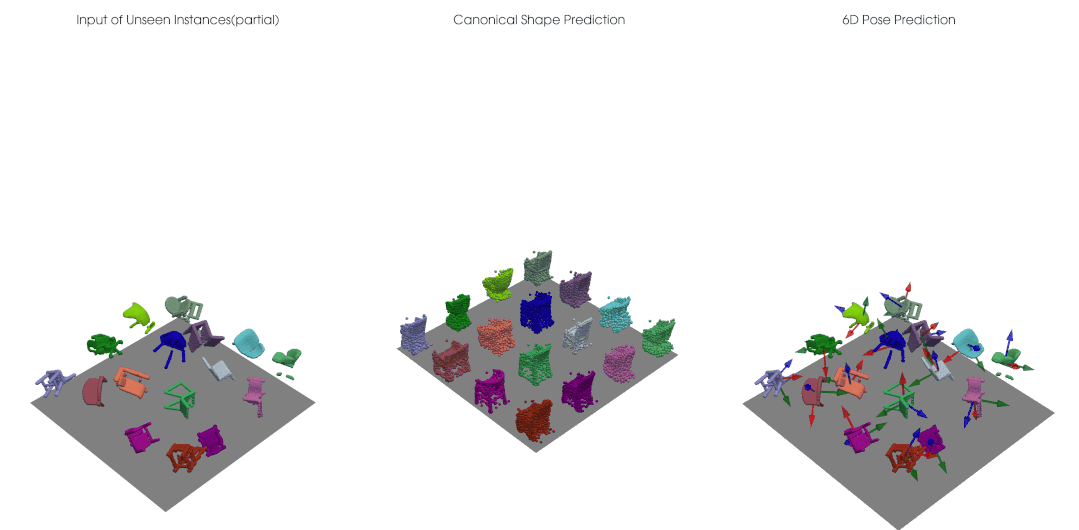
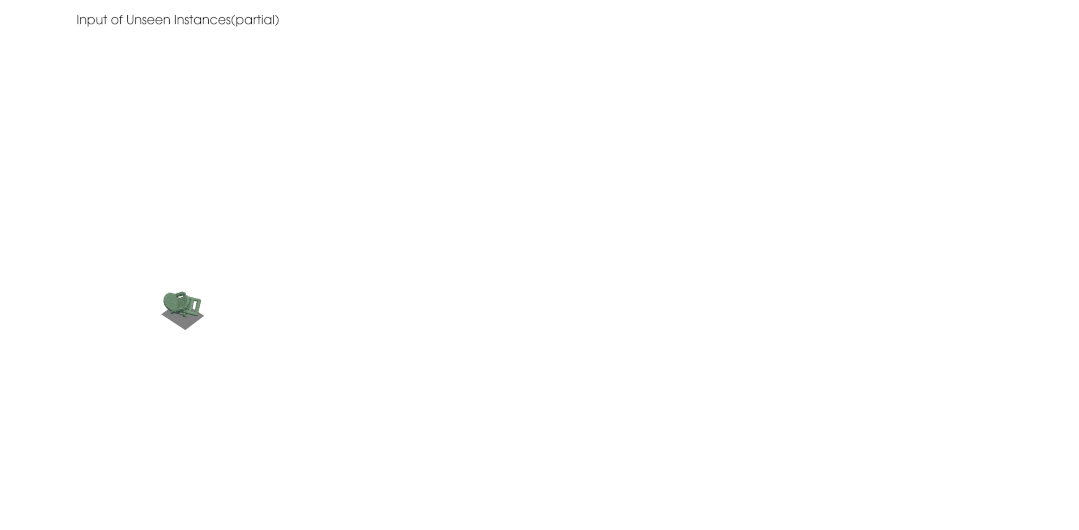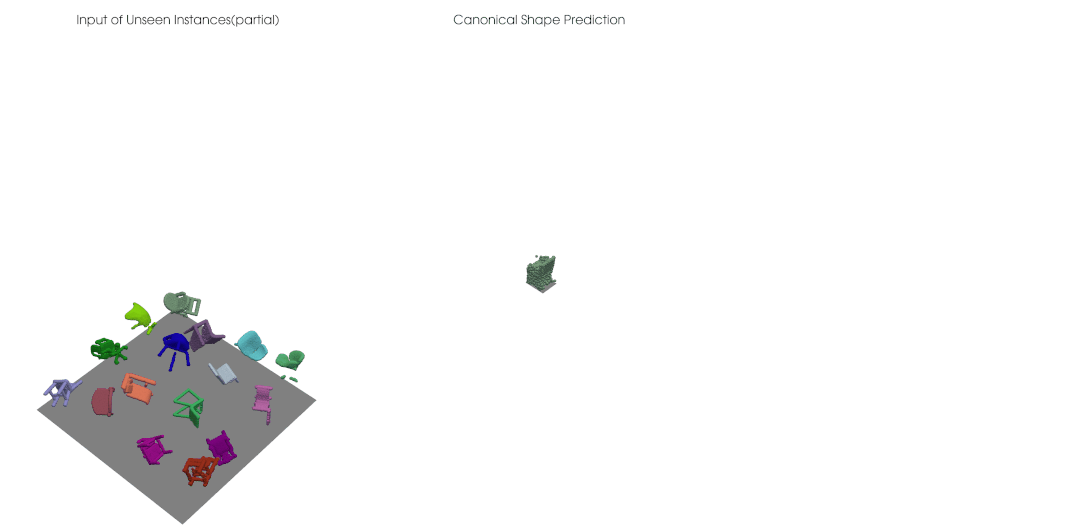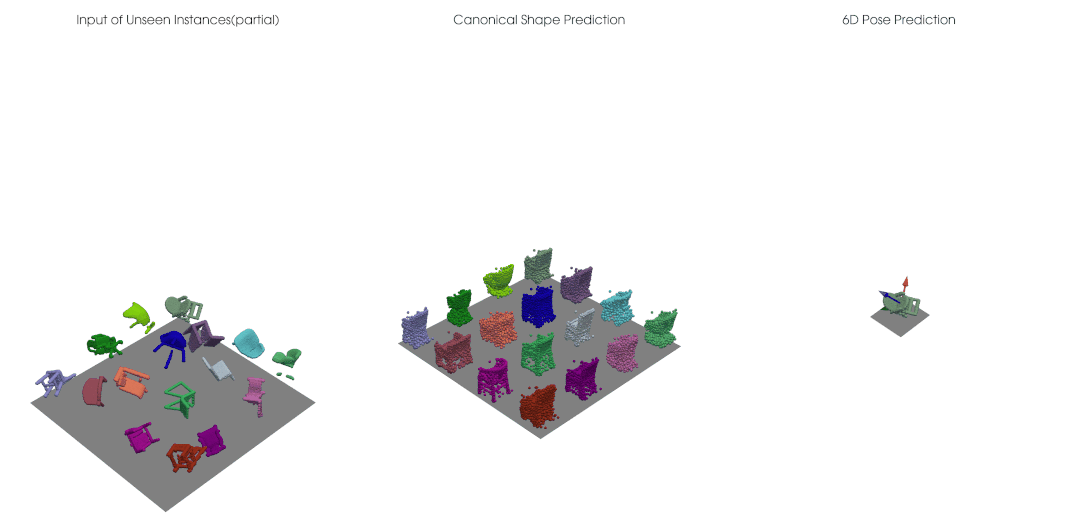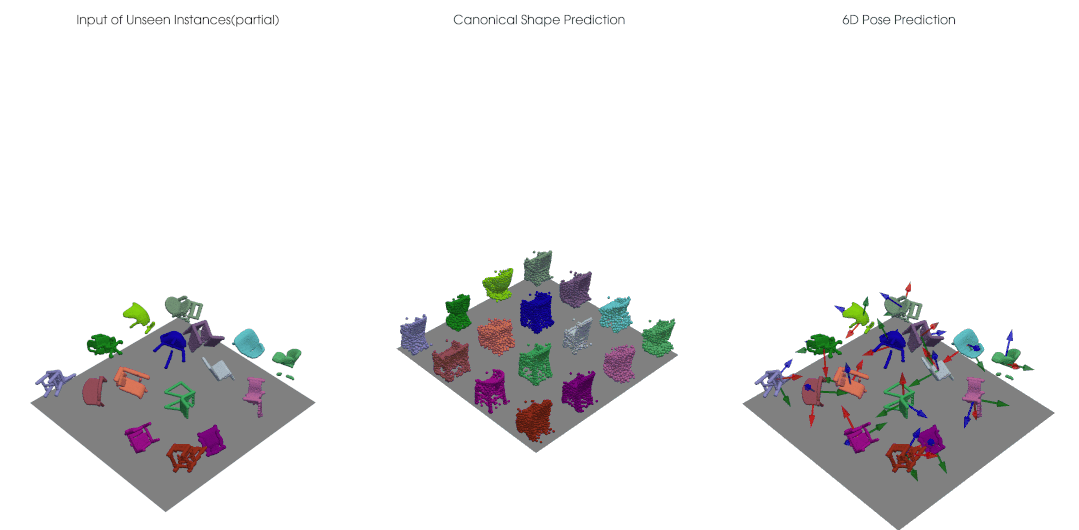
类别级的物体位姿光靠一些输入数据仍是缺乏定义的,我们需要获得跨实例的、具有一致性的类别级位姿参考系; 对于深度图点云,输入物体进行刚性移动时,点云的可见性会发生变换,因此点云并不是简单进行了 的一个变换,还耦合上了可见性的变化,也就是说即使我们的网络是严格等变的,对于深度点云输入,输出也无法保证等变。
我们结合点云等变性的设计可以实现自监督的类别级物体位姿学习,在没有大量标注的情况下仍然获得很好的位姿估计准确度。类别级的物体位姿估计需要有一致性对齐的规范空间中的参考位姿,我们在实验中观测到利用等变网络可以对不同位姿、不同形状的输入有一致对齐的正规重建。对于未来的拓展研究,我们期待有更多将这一自监督框架应用于比如 RGB-D 视频的无监督追踪的研究,或者解决有多个部分、有关节的物体上等等。
参考文献
[1] Xiaolong Li, Yijia Weng, Li Yi, Leonidas J Guibas, A Lynn Abbott, Shuran Song and He Wang. Leveraging SE (3) Equivariance for Self-Supervised Category-Level Object Pose Estimation. NeurIPS 2021.
[2] He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, Leonidas J. Guibas. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. CVPR 2019.
[3] Haiwei Chen, Shichen Liu, Weikai Chen, Hao Li, Randall Hill. Equivariant Point Network for 3D Point Cloud Analysis. CVPR 2021.
[4] Fabian B. Fuchs, Daniel E. Worrall, Volker Fischer, Max Welling. SE(3)-Transformers: 3D Roto-TranslationEquivariant Attention Networks. NeurIPS 2020.
[5] Paul J Besl, and Neil D McKay. Method for registration of 3-D shapes. SPIE 1992.
具身感知与交互实验室 EPIC Lab (Embodied Perception and InteraCtion Lab) 由王鹤博士于2021年创立。该实验室专注于研究三维计算机视觉和机器人学,研究目标是建立和学习面向通用智能体的、可泛化的机器人视觉系统和物体操控策略。
2021-12-10

2021-12-09

2021-12-12

2021-12-12