本文将解读蚂蚁集团图学习团队在ECML PKDD 2021上发表的论文 《Inductive Link Prediction with Interactive Structure Learning on Attributed Graph》 。该论文提出的路径感知图神经网络PaGNN主要探索了在链接预测任务中如何将节点间的复杂网络结构学习集成到传统GNN的计算范式中,从而提高链接预测的准确率。目前,PaGNN已成功应用于蚂蚁集团多个数字金融业务场景中。
https://2021.ecmlpkdd.org/wp-content/uploads/2021/07/sub_635.pdf
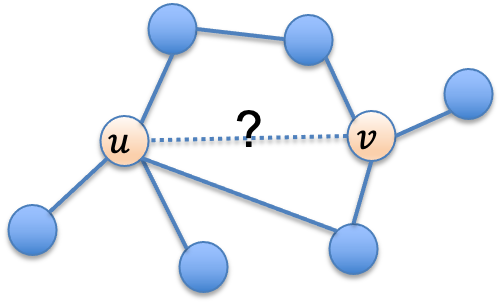
一、引言 链接预测任务通常需要判断两个节点之间是否存在某种特定的关系。比如,在推荐场景中,预测一个用户是否会购买某一件商品,社交场景中,预测两个用户之间是否存在朋友关系,这些任务都可以抽象为判断图中的两个节点之间是否存在某种特定的关系,如下图所示:
图1 链接预测任务
之前学术界关于链接预测的方案主要可以分为三类: 启发式方法(Heuristic Methods),Network Embedding的方法和图神经网络方法。
启发式方法(Heuristic Methods) 主要考虑利用两个节点之间一些预先定义的特征来衡量节点之间的相似度,比如,节点的共同邻居(Common Neighbor),Jaccard相似度,Katz Index等,这样的方法假设存在边关系的节点之间存在某种特定的结构特性,但这样的假设不一定对任意网络都有效。
Network Embeddings 方法使用基于游走的方法得到经过某个节点的多条路径,再通过Skip-Gram和CBOW的方式,对路径上mask的节点进行预测。这样的方法,没有直接将链接预测任务嵌入到有监督学习的流程中,并且无法较好的利用用户的节点属性,无法达到较好的预测精度。
图神经网络(graph neural network,GNN) 的方法也主要分为两类,节点为中心的图神经网络模型(Node-centric GNN)和边为中心的图神经网络模型 (Edge-centric GNN) 。
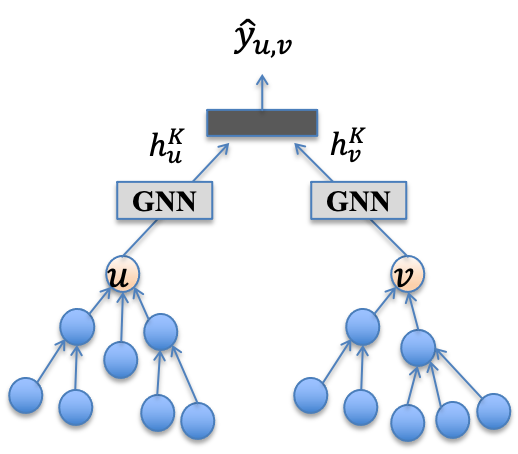
Node-centric GNN 分别对需要预测边上的两个节点的邻域信息进行聚合。例如在PinSage中,针对推荐问题,提出了一种基于双塔的结构召回模型,该方式分别对用户和商品节点邻域进行表征,再通过一个matching layer预测用户点击该商品的概率,整个模型结构如下所示。Node-centric GNN模型的不足在于,生成节点表征时,仅仅考虑对两个节点的邻域节点属性独立地进行聚合,忽略了对节点之间的交互结构建模。
Edge-centric GNN 不仅考虑聚合节点的邻域信息,也考虑两个节点之间的连接,例如在SEAL中,使用Node labeling编码标注邻域节点的角色,GIL(Graph Inference Learning)框架使用两个节点之间之间的路径可达性(如random walk相似度)辅助链接预测任务学习,GraIL使用graph-level的readout函数进行子图结构的表征。现有的Edge-centric GNN将结构信息和属性信息分开建模,无法抽取到高阶结构和属性的融合信息,如在社交网络中,无法建模“A和B之间校友关系的共同好友数量”这样的pattern。 针对上述方法的主要问题,本论文提出了 一种路径感知的图神经网络模型(Path-aware Graph Neural Network,PaGNN) ,通过一个传播操作和一个聚合操作,将节点之间的交互结构和属性信息聚合集成到GNN模型中,并提出了一种基于缓存的策略对Inference阶段进行加速,最终在不同领域的数据集上,证明了PaGNN模型超过了现在的state-of-the-art模型,同时,缓存策略相比其他的edge-centric模型有较大提速。 二、 方法 2.1 PaGNN概述
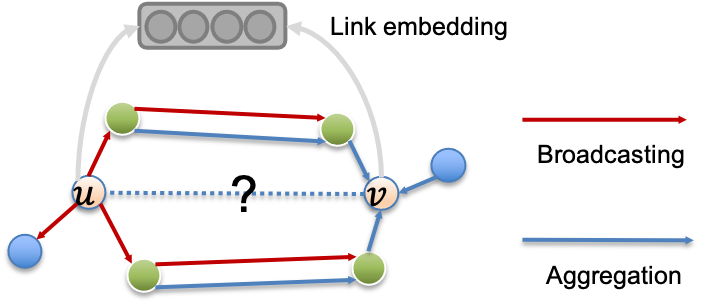
PaGNN模型包含两个主要的操作:broadcasting操作和aggregation操作。第一步,对于需要预测的链路中的两个节点,broadcasting操作从其中一个节点出发,将节点特征传播到与其相连的直接邻居,并融合直接邻居和传播边上的信息。第二步,通过aggregation操作,将邻居信息聚合到链路中的另一个节点中,与之前GNN的aggregation操作相比,除了需要聚合邻居本身的信息,还需要聚合之前broadcasting操作生成的信息。PaGNN模型整个流程如下图所示。
图4 PaGNN流程
2.2 Broadcasting操作
定义了节点u的H步ego-subgraph,且 , 和 分别是节点u的ego-subgraph的节点集合和边集合。Broadcasting操作在第k步迭代中维护了一个出发节点集合 和一个到达节点集合 , 为 节点的一步邻居节点。在每次broadcasting操作中, 中的节点将自身信息传播到 节点上,通过一个基于attention算子的ATT_OP操作(算法第7行)和一个基于LSTM算子的LSTM_OP操作(算法第8行),将信息聚合到对应的目标节点。整个broadcasting算法流程如下图所示。 算法1 Broadcasting操作
在如上算法1的第5行中,通过 计算得到本轮迭代的 。其中,ATT_OP函数的设计利用了attention机制,解决 多个节点会传播信息到某一个相同的节点的情况,此时ATT_OP将不同的节点信息进行汇聚,ATT_OP具体计算形式如下
对于所有 中的节点,LSTM_OP函数使用LSTM算子,将ATT_OP聚合得到的表征,结合节点上一次迭代的broadcasted embedding,得到新一次迭代的broadcasted embedding: ,对不在 中的节点来说,broadcasted embedding等于上一轮迭代的结果(如上述算法的10到12行所示),LSTM_OP的操作具体实现如下:
整个broadcasting操作和图中的广度优先搜索比较相似,每次从一些节点出发(源节点),访问这些节点的直接邻居(目标节点),并将该轮迭代的目标节点作为下一轮迭代的源节点(算法1,13行)。经过H轮迭代后,对于 中的每个节点p的broadcasted embedding 将会作为之后aggregation操作的输入。
图5 Broadcasting操作
整个broadcasting的过程如上图5所示,图中的公示分别表示 : source nodes in k-th iteration, : destination nodes in k-th iteration, : broadcasting edges (from to )。 2.3 Aggregation操作 相比于之前GCN模型的聚合操作,在PaGNN中,不仅需要聚合中心节点的邻域信息,也会聚合之前broadcasting操作得到的broadcasted embedding。例如需要预测 <u,v> 之间是否存在某种关系,需要从一个点开始传播信息,另一个节点接受信息。不失一般性,我们假设对节点u进行broadcasting操作,然后对节点v进行aggregation操作。在从节点u做broadcasting之后,可以计算得到 上每个节点的H步broadcasted embedding ,再对 上的节点向v做aggregation操作,对于 的节点来说,初始向量由节点自身的初始特征 和 拼接得到,具体计算如下所示:
如上公式中,由于节点u只能broadcast到 上的节点,只有满足 的节点p,才存在broadcasted embedding ,对于 ,默认 为0向量。通过这样的形式,从节点u出发的broadcasted embedding,可以通过 这样的“bridge nodes”,传播到节点v上,经过aggregation操作后,节点v的embedding会包含 中邻域节点的信息,以及通过bridge nodes传播过来的路径信息。节点具体的聚合形式,和基于空间的GCN模型相同,即: 最终信息从u传播,并聚合到节点v的H步迭代结果 可以作为节点v的表征。整个aggregation操作的过程如图6所示。 图6 Aggregation操 作 2.4 边表达学习 PaGNN首先通过从节点u做传播并将信息聚合到v,得到节点v的表征 ,再从节点v做传播并聚合到节点u,得到节点u的表征 ,最终将u和v的表征拼接得到最后边<u,v>的表征:
同时,使用cross entropy作为最终的损失函数: 2.5 缓存策略
相比Node-centric的方法,Edge-centric方法需要在两个目标节点构成的子图上操作,以抽取节点之间的高阶交互信息,计算过程更加耗时,为了提升模型Inference阶段的效率,本论文中提出了一种缓存机制来加速PaGNN模型的打分。
图7 缓存策略动机 通过上面对broadcasting操作和aggregation操作的描述,可以看出对于节点u来说,另一个节点v的位置并不会影响节点u的broadcasted embeddings,如下图7所示,对于<u, v>和<u, v'>两条边来说,节点u的邻居节点p的broadcasted embedding 相同。基于这样的性质,可以在计算得到节点u的broadcasted embeddings之后,对这些表征进行缓存,最终在第二次打分时直接使用缓存的 broadcasted embedding。 时间复杂度分析
Broadcasting过程的整体时间复杂度为 ,Aggregation过程的时间复杂度为 ,所以PaGNN的时间复杂度为Broadcasting过程和aggregation过程的复杂度加和,为 ,而由于Cache Strategy缓存了broadcasted embeddings,只需要一次aggregation操作,最终的时间复杂度为 。 总结来说,使用Cache Strategy的PaGNN模型在理论上有50%的提速。
三、实验 3.1 数据集
本论文在几个公开数据集上进行了实验,其中Facebook数据集描述了好友关系,PubMed和Collab描述了文献引用关系,SupChain数据集描述了企业之间的上下游关系。数据集的统计特性如下表所示。
表1 数据集统计特性 3.2 Baseline 实验中使用的baselines主要分为以下几个类别。 启发式方法(Heuristic Methods) 选择了共同邻居(Common Neighbors,CN)和Jaccord; Network Embeddings 方法的选择了DeepWalk和Node2Vec两种; Node-centric GNN 使用了PinSage提出的双塔GNN的模式,根据聚合函数的不同分别表示为 和 ; Edge-centric GNN 使用基于节点标注的SEAL模型和子图级别readout函数的GraIL模型; 同时,该论文也进行了多个消融实验,来验证PaGNN模型设计中不同模块的有效性。 使用单路的Broadcasting操作 ,即 ;将broadcasting操作中的lstm算子换成向量拼接操作 ,只进行aggregation操作而不使用broadcasting操作 ,即对所有u的邻居p使得 。 3.3 模型性能 从表2的结果可以看到,相比现有不同类型的模型,PaGNN在所有数据集上都有较大提升,并且消融实验验证了PaGNN每一个模块的有效性。 表2 模型性能 对比 同时论文分析了不同参数的敏感度来分析邻居阶数,训练步数以及表征向量的大小对模型性能的影响,如上图所示。 图8 参数敏感度 论文对Facebook好友关系预测的数据集结果分析,如上图所示,边上的数值为该关系的attention值,可以看出,Node-centric的GNN模型 无法判断哪些节点在两个节点之间路径中,几乎所有关系的attention值都相同,而Edge-centric的模型发现在预测好友关系时,连通两个节点之间的节点对于预测更重要,同时PaGNN模型输出的路径上节点重要度要大于GraIL模型。 图9 模型实例分析 从图10可以看出,两个节点之间的共同路径越多,两个节点更有可能存在特定的关系,而PaGNN能够更好的学习到这样的pattern。 图10 路径条数和标签的关系 该论文进一步分析了不同类型模型的性能,从图11 (a)可以看出,在训练过程中,Edge-centric的模型相比Node-centric的模型更加耗时,主要原因是Edge-centric模型的计算需要在每一条边关联的子图上完成,而Node-centric只需要对每个节点独立进行聚合,可以减少部分重复运算,同时随着邻居的阶数H的增加,模型的耗时也进一步增加。图11 (b)展示了在Inference节点模型的效率,可以看出尽管PaGNN模型更加耗时,但在使用了缓存策略之后,耗时低于其他Edge-centric的模型,当H=5时,实际测试有30%左右的加速,证明了Cache Strategy的有效性。 图11 模型效率对比 四、总结 本论文聚焦于“使用一条边上两个节点之间的交互结构来提升链接预测任务的准确率”, 提出了一种路径感知的图神经网络PaGNN模型 ,将broadcasting和aggregation操作集成到传统GNN模型中,从节点自身的邻域和他们之间的复杂结构中,学习属性和结构信息,学习到和关系预测强相关的邻域和交互高阶结构信息。同时提出了一种缓存机制来加速PaGNN在Inference阶段的性能。论文在现实世界的数据集上,进行了全面的实验来证明了模型的有效性和性能。
Illustrastion b y Iconscout Store from iconscout
关于我“门 ”
▼
将门 是一家以专注于 发掘、加速及投资技术驱动型创业公司 的新型 创投机构 ,旗下涵盖 将门创新服务 、将门技术社群 以及将门创投基金 。 将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。 如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务, 欢迎发送或者推荐项目给我“门”: 点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球



 算法1 Broadcasting操作
算法1 Broadcasting操作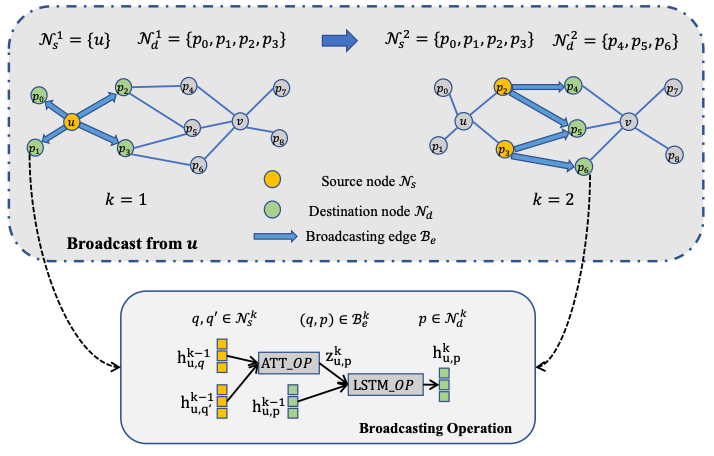
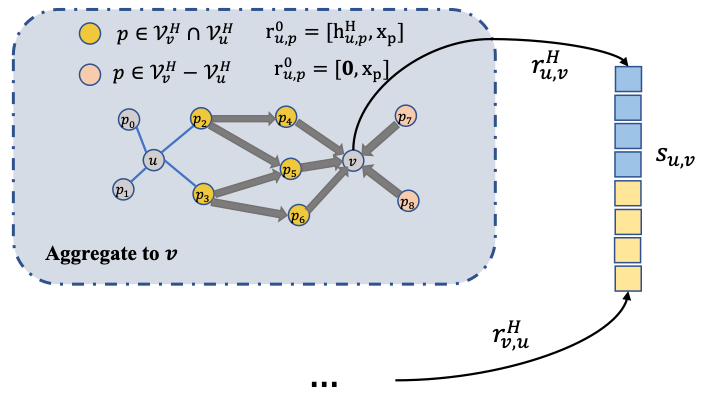
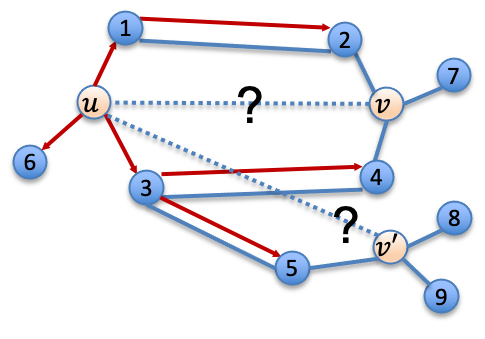 图7 缓存策略动机
图7 缓存策略动机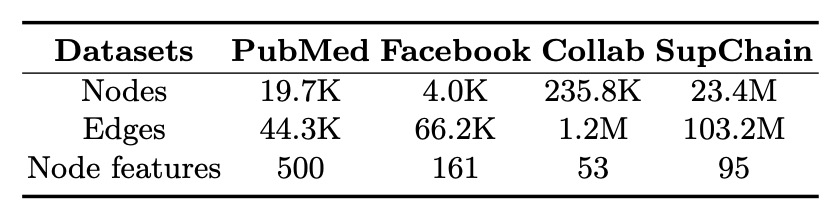
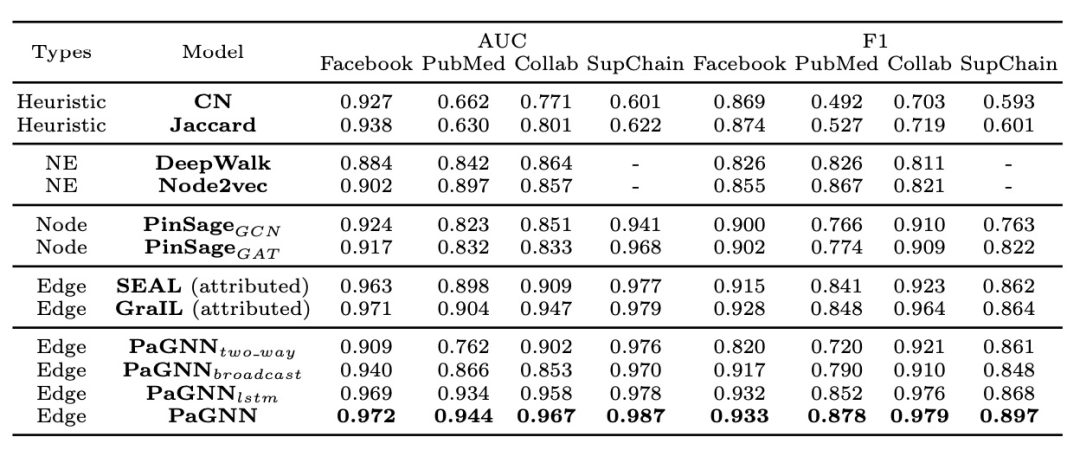
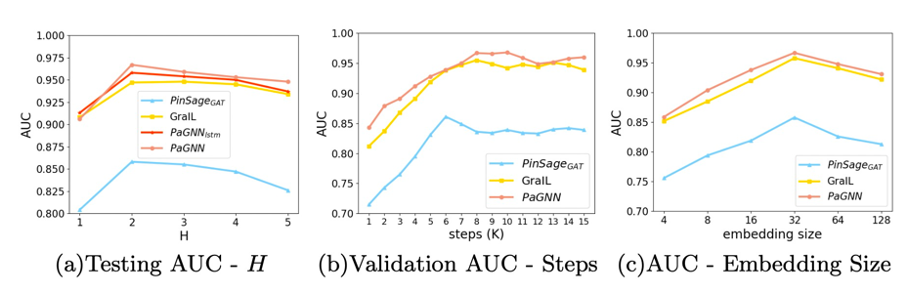 图8 参数敏感度
图8 参数敏感度 图9 模型实例分析
图9 模型实例分析 图10 路径条数和标签的关系
图10 路径条数和标签的关系


