基于Adapter结构进行高参数效率的跨语言迁移学习
以下文章来源于王晋东不在家 ,作者王晋东
分享科研与研究生活的点点滴滴,包括但不限于:机器学习、迁移学习、元学习等,以及研究生、博士生生活的经验教训。
本文将为大家介绍「如何使用Adapter(适配器)结构、基于元学习和迁移学习思想对预训练语音识别(ASR)模型进行跨语言的迁移」。在这项工作中,我们主要研究了如何利用Adapter进行高参数效率(parameter-efficient)的预训练多语言ASR模型的迁移,并提出了「MetaAdapter」和「SimAdapter」对Adapter进一步优化;在仅使用「2.5%「和」15.5%「的可训练参数的情况下,使得识别词错误率(WER)相对全模型微调(fine-tune)分别降低了」2.98%和2.55%」。该研究成果已被语音领域顶级期刊 IEEE Transactions on Audio, Speech, and Language Processing (TASLP)接收。
本文作者:侯汶昕(东京工业大学硕士、现微软算法工程师, 知乎@Harold)
论文链接 :https://arxiv.org/abs/2105.11905
代码地址:https://github.com/jindongwang/transferlearning/tree/master/code/ASR/Adapter

语音识别是一种十分重要的技术,可以在很多场景下提高人们的生产力。在一代代科学家和工程师的努力下,语音识别系统在各种主流语言上都已经达到了非常好的效果,我们在生活中就能享受其带来的便利。然而,世界上有大约7,000种语言,其中「绝大部分」语言的使用者并不多,这些语言的数据也因而十分稀缺(我们称之为「低资源」(low-resource) 语言)。标注数据的稀缺导致近年来端到端语音识别的诸多成果迟迟不能落地到这些语言上。
带着这样的动机,我们开始思考如何利用迁移学习,将主流语言(如英语,中文等)的知识用来帮助低资源语言的学习,或者说如何让知识在多种语言之间共享,以便能够“四两拨千斤”,提升这些小语种上的语音识别表现。如下图所示,给定罗马尼亚语作为我们的目标语言,我们如何利用数据相对丰富的三种语言(意大利语、威尔士语、和俄语)来帮助训练更好的罗马尼亚语音识别模型?
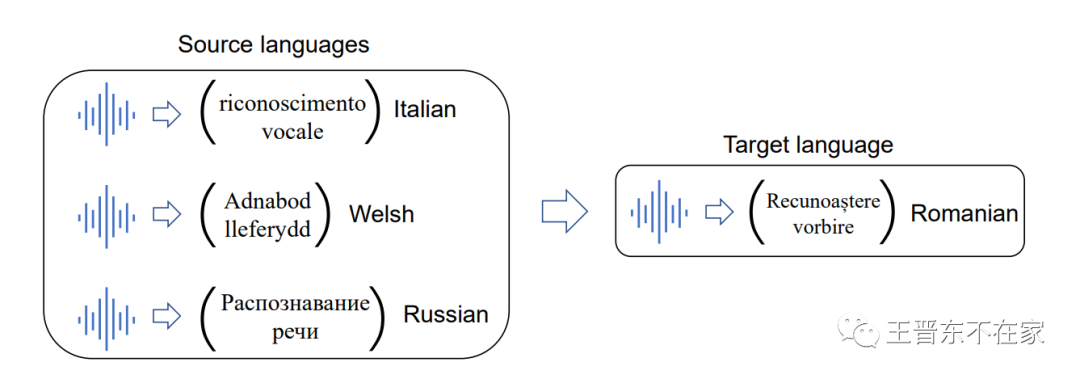
给定若干源语言,我们要如何将知识迁移到目标语言上?
幸运的是,近年来,如wav2vec2.0 [1] 等的预训练模型都已经推出了多语言版本,我们之前的研究也证明了「仅需要简单的微调(fine-tune)」,一个大规模的多语言模型就能被适配到一个低资源语言上,并能显著改善识别性能。
但与此同时,我们也发现了两个新的问题:
大规模的多语言模型往往含有大量的参数,导致在一些数据量非常少的情况下,「模型极容易过拟合」。
如果对于世界上的每一个小语种都维护一个微调后的大模型,那可想而知成本会十分巨大。
因此,受到Houlsby等人提出的「Adapter」的启发 [2],我们决定尝试使用Adapter来解决这个问题。
本节中我们会依次介绍我们使用的主干模型以及整体结构,原始版本的Adapter,我们提出的MetaAdapter和SimAdapter。
主干模型以及整体结构
本文中我们使用了自己预训练的多语言模型进行实验,当然我们的方法也可以用于wav2vec2.0等模型上。具体来说,我们的模型基于Transformer的结构,主要包含12层Encoder以及6层Decoder模型,我们结合了11种语料(包含42种语言,总时长约5,000小时)对模型进行预训练。我们采用了CTC-Attention混合损失函数来提升训练的稳定性和加速训练,即在Encoder的输出特征上增加CTC层,使用CTC损失进行约束。
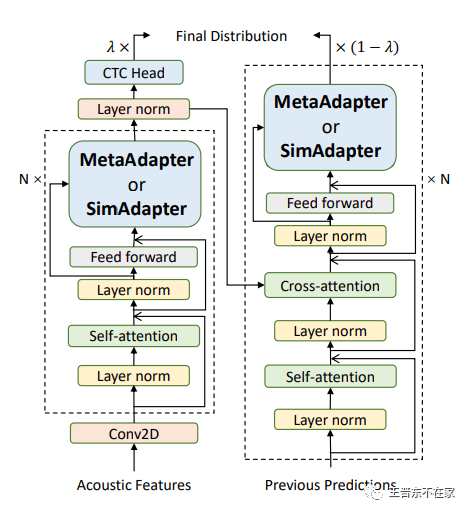
主干模型
我们将Adapter放在前馈层(Feed-Forward Networks)后面,从而对每一层的输出的特征进行调节。
什么是Adapter
Houlsby等人发现,对于一个预训练好的BERT,只需要在Transformer的每一层插入一个如下图所示的适配器(Adapter),就能在不改变模型主干参数的情况下将模型适配到各种下游任务,「甚至能够取得接近整个模型微调的表现」。适配器主要包含一个LayerNorm层,用于重新调节原始特征的尺度,接着是分别是一个降采样层和一个升采样层对特征进行压缩和还原,最后由一个残差连接保证原始特征依然能通过,从而提升Adapter训练时的稳定性。
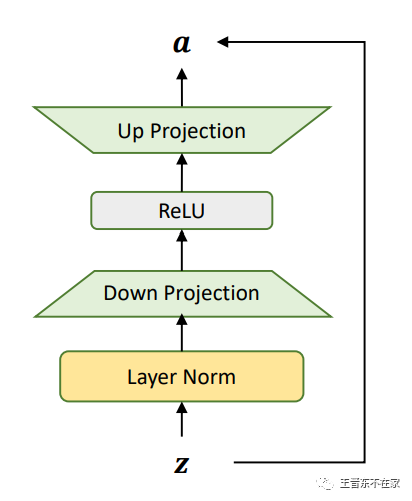
Adapter
MetaAdapter
MetaAdapter在结构上与Adapter完全一致,唯一不同的是,我们使用MAML(Model-Agnostic Meta-Learning)[3] 元学习算法来学习一个Adapter更优的「初始化」。MetaAdapter需要通过学习如何学习多种源语言,从而在各种语言中收集隐含的共享信息,从而来帮助它学习一个新的语言。
我们在实验中发现,MetaAdapter对于过拟合和极少数据量的鲁棒性、以及最终迁移效果均显著强于原始Adapter。
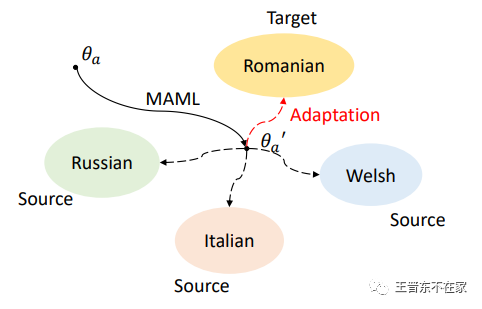
MetaAdapter
SimAdapter
如果说MetaAdapter需要通过收集「隐含」的共享信息来学习新的语言,那么SimAdapter则是「显式」地要求模型去建模各种语言的相似度关系,从而更好的学习目标语言,其结构如下图所示。我们认为多语言模型的原始特征是相对语言无关的,那么如果使用这些特征作为Query,将各语言Adapter(包括目标语言)输出的语言强相关特征作为Key和Value,那么就能通过构造注意力机制,从目标语言和源语言中分别提取一些有效信息,作为更好的目标语言特征。
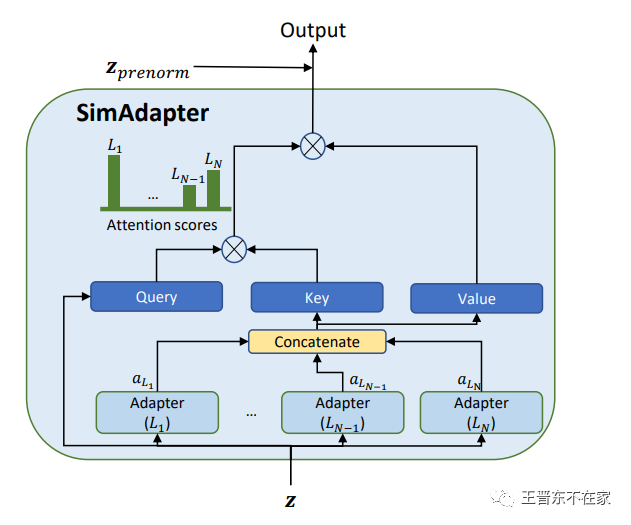
SimAdapter
由于篇幅限制,我们这里仅展示一下主要结果和我们认为比较有趣的结论,消融实验以及更多实验细节请参考原论文。
主要结果
我们在Common Voice的五种低资源语言上进行了实验,结果如下表所示。根据迁移与否以及迁移方式的不同,我们将各种方法分为3类:
不迁移(左边栏):包括了传统的DNN/HMM混合模型,从头训练的Transformer(B.和本文用的主干模型大小结构均一致;S.指为了抑制过拟合,而将参数量调小的版本),以及将预训练好的模型当作特征提取器,去学习目标语言的输出层。
基于微调的迁移(中间栏):包括了完整模型的微调,以及我们对于抑制过拟合的尝试(完整模型微调+L2正则化、仅微调模型最后几层参数)
基于Adapter的迁移(右边栏):即本文介绍的各种方法,其中SimAdapter+是结合了SimAdapter和MetaAdapter的升级版。
我们采用了两种平均方式来反应模型的不同能力:
直接平均:没有考虑不同语言内的数据量,对于尤其擅长极少数据的算法会更有优势
加权平均:考虑了不同语言本身的数据量,更适合用来衡量模型在各种情况下的综合表现

主要结果
由结果可以看出:
使用迁移学习的方法均明显好于不使用迁移学习的方法,印证了迁移学习的重要性
全模型微调有着非常强大的效果,对其施加传统的L2正则,抑或是仅微调模型最后几层参数效果都不是很好
原始的Adapter在合适的训练方法下基本可以达到和全模型微调相同的水平,说明了Adapter在ASR任务上的有效性
本文提出的SimAdapter和MetaAdapter均进一步提高了Adapter的表现,将它们结合后的SimAdapter+达到了文中最优的结果。
值得注意的是,我们发现MetaAdapter更擅长数据量极少的情况,而在SimAdapter则有着更均衡的表现
这样训练Adapter效果更好?
我们在本文中提出一种两阶段的训练方法用以提高Adapter在语音识别任务上的表现:模型迁移过程中需要学习一份新语言的词表,如果将该词表和Adapter一起训练,由于词嵌入的不断更新,可能会导致Adapter学习目标的混乱。同时学习Adapter和词表也可能会词嵌入会承担一部分Adapter的功能,导致Adapter无法学习到足够的语言相关的特征,造成后续SimAdapter的表现下降。因此,我们先将主干模型固定住,将新语言的词表映射到模型相同的隐空间(latent space)中,再将词表固定住学习Adapter,从而达到更好的效果。下表的结果印证了我们的猜想。
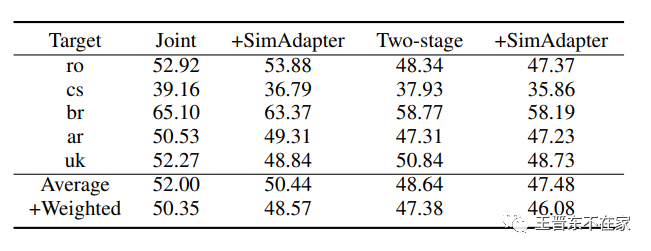
二阶段训练法
SimAdapter真的有在学习建模语言相似度
为了证明SimAdapter真的能够从其他语言学习到有用的知识,我们设计了两个实验:
在第一个实验中,我们尝试去除掉目标语言本身的Adapter,以要求SimAdapter仅通过源语言来学习一个对目标语言有用的特征,结果如下表所示。我们可以发现,「即使没有使用目标语言Adapter,SimAdapter依然能够在多数语言上取得较明显的提升」。
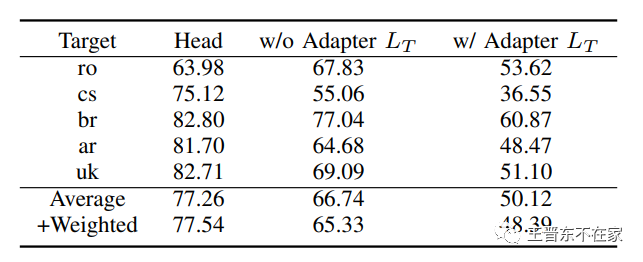
SimAdapter消融实验
在第二个实验中,我们在乌克兰语上训练两个不同的SimAdapter模型,以分析不同源语言的贡献。具体来说,我们分别选择了意大利语和俄语作为源语言。由于俄语和乌克兰语比意大利语更相似,使用俄语Adapter共同训练的SimAdapter应当获得更多收益。结果与我们的期望相符。我们观察到,使用意大利语Adapter的SimAdapter的词错误率为48.70,而使用俄语Adapter的词错误率仅为47.73,这表明相比意大利语,SimAdapter可以从俄语中学习更多的有用知识来建模乌克兰语。
本文研究了如何使用Adapter(适配器)对预训练语音识别(ASR)模型进行跨语言的迁移,并提出了两种改进措施进一步提升Adapter的迁移表现。我们一直认为,对于语音识别(乃至整个自然语言处理领域)而言,除了推进技术的最前沿之外,如何将既有的技术更好的推广,让更多的人能够共享技术的进步也是十分重要的事情。
References
2021-12-10

2021-12-09

2021-12-12

2021-12-12
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。