你就是你自己paper最好的审稿人:宾大苏炜杰提出peer review新机制

本文转载自丨智源社区


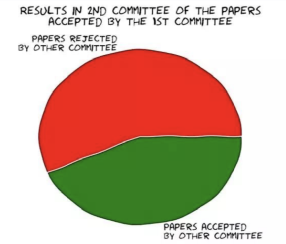
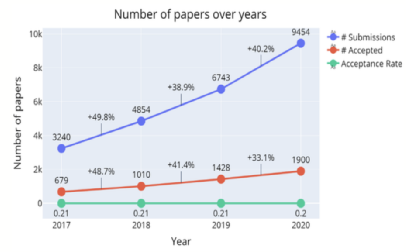
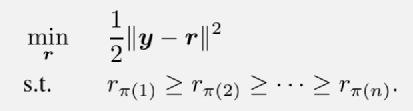
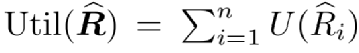

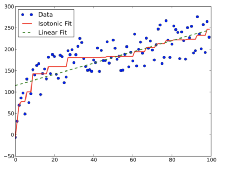
虽然效用函数为凸一定程度上符合研究者的偏好,但是对于一些追求中稿数量的研究者,效用函数可能是一些特殊的非凸函数(例如阶梯状的函数)。如何改进技巧应用到这种问题上?
当前改进同行评审已经有一些初见成效的工作,如何将他们结合进来?
保序机制的准确性是使用L2误差来衡量的。有没有更符合实际情况的误差函数?
如何应对投稿人策略性地利用保序机制,例如故意提交低质量论文变相抬高分数?
在跨学科评审和多个审稿人多个作者的情况下,如何保证噪声的可交换性,如何对应修改保序机制?
保序机制要求提供论文质量的排序是否有附带好处?比如要求作者对自身论文质量有更清楚的认识,促使科研工作者努力提高论文质量,减少投稿量。此外还可能会减少会议论文常见的“guest authorship”。这或许能缓解学术界的“内卷”。

https://arxiv.org/pdf/2110.14802.pdf
https://www.toutiao.com/i7039916197835506209/?timestamp=1639147753&app=news_article&group_id=7039916197835506209&use_new_style=1&req_id=202112102249130101310380762754C599&wid=1639647590857
https://arxiv.org/pdf/2109.09774.pdf
https://www.reddit.com/r/MachineLearning/comments/r24rp7/d_peer_review_is_still_broken_the_neurips_2021/
https://hub.baai.ac.cn/view/10481
https://zhuanlan.zhihu.com/p/90666675
https://cloud.tencent.com/developer/article/1172713
http://eprints.rclis.org/39332/
2021-12-10

2021-12-09

2021-12-12

2021-12-25

2021-12-29

由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。