来源:内容来自ctimes,谢谢。
半导体行业观察最有深度的半导体新媒体,实讯、专业、原创、深度,50万半导体精英关注!专注观察全球半导体最新资讯、技术前沿、发展趋势。《摩尔精英》《中国集成电路》共同出品,欢迎订阅摩尔旗下公众号:摩尔精英MooreElite、摩尔芯闻、摩尔芯球
2461篇原创内容
公众号
新一代的高效能系统正面临资料传输的频宽限制,也就是记忆体撞墙的问题,运用电子设计自动化与3D制程技术,IMEC证实3D SoC设计能大幅提升性能并降低功耗,成为备受瞩目的异质整合解决方案。
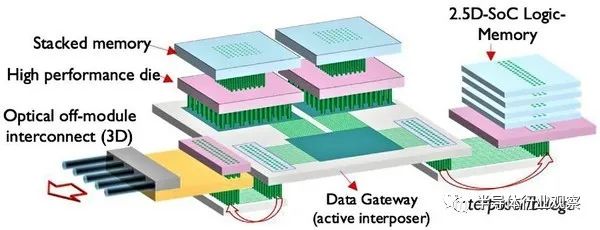
资料密集的高效能系统用于先进运算、伺服器或深度学习应用,然而,现在却面临着所谓的「记忆体撞墙(memory wall)」问题,而且这项挑战日益严峻,资料存取速度难以突破瓶颈。为了推倒这面高墙,3D系统单芯片(SoC)整合技术备受瞩目。利用这套异质整合方法,芯片系统能自动分割为多个独立芯片,并实现这些芯片的3D同步设计与互连(interconnect)。在2021年IEEE国际电子元件会议(IEDM)上,IMEC的研究团队发表了两篇3D SoC与晶背互连技术的论文,其中一篇列举了3D SoC这项设计概念的技术优势,目标要实现多芯片的异质系统整合,超越时下炙手可热的小芯片(chiplet)设计。IMEC资深研究员,同时也是3D系统整合研究计划的研发副主任Eric Beyne表示:「小芯片概念涉及了多个小芯片的独立设计与制造,著名的例子就是高频宽记忆体(HBM),它把多个DRAM芯片堆叠起来,接着透过介面汇流排,把堆叠连接到处理器芯片,因此在应用上必须容忍一定的延迟时间。有鉴于此,小芯片设计永远无法在逻辑单元与一级和二级快取记忆体之间实现快速存取。」3D SoC整合技术采用直接连接且距离更短的互连导线来进行记忆体与逻辑单元的分割,最终能显著改善传输性能。在论文中,IMEC团队展示了一项经过优化的3D SoC设计,将记忆体巨集(memory macro)置于最上层芯片,其余逻辑单元则在底层,其运作频率与2D设计相比,提高了40%。图一: IMEC于2021 IEDM展示的未来高效能系统抽象视图:高效能芯片与3D SoC记忆体堆叠布建于主动式中介层上方,并将中介层作为闸道,以2.5D的方式连接到局部HBM和光学收发器模组。
为了实现全功能化的3D SoC,关键的技术挑战也纳入了讨论。IMEC主任研究员,也是布鲁塞尔自由大学教授的Dragomir Milojevic指出:「从设计面来看,在进行逻辑单元和记忆体的分割时,都要采取3D SoC协同设计的策略。这就会用到专属的电子设计自动化(EDA)工具,才能同时顾及两方的设计,并在布局与布线时,利用自动化工具完成系统分割与3D关键路径优化。透过与益华电脑(Cadence)合作,我们已经取得这些先进工具。」他接着分享,在技术层面,晶圆对晶圆的异质接合解决方案将会持续发展,进一步提升芯片之间的互连导线密度,这对一级和二级快取分割来说是必要技术。图二: IMEC于2021 IEDM展示间距为700nm的晶圆对晶圆异质接合技术。
高效能3D SoC的系统分割可能会将部分或全部的记忆体巨集布建在最上层芯片,逻辑单元则置于最下层。在技术上要做到这点,可以将放置逻辑单元的晶圆主动侧正面,以低温晶圆对晶圆的接合技术,链结到记忆体所在的晶圆主动侧正面。在这种配置下,原本的两面晶背会变成3D SoC系统的外侧。Eric Beyne点明:「现在我们可以考虑利用这些『空出来的』晶背,用于讯号绕线,或是直接供电给逻辑单元晶圆上的电晶体。传统制程通常把绕线和电源供应设计在晶圆正面,所以在处理复杂互连导线的后段制程中,必须努力争取空间,而晶背在这类设计中仅仅作为封装用的芯片载体。」他进一步说明,2019年Arm的模拟结果首次证明在CPU设计中导入晶背电源供应网路(power delivery network;PDN)所带来的正面效益。该CPU设计采用IMEC开发的3nm制程,位于薄型化晶背的互连导线连接到晶圆正面的3nm电晶体,两者透过落在埋入式电源轨(buried power rail;BPR)结构上的矽穿孔(through silicon via;TSV)相连。根据模拟结果,晶背PDN的传输效率比传统的正面PDN还高出7倍。因此,可以预期在记忆体与逻辑单元堆叠(memory-on-logic)的3D SoC应用上,运用晶背PDN来供电给位于底层且功耗较大的核心逻辑电路,将能额外加强性能。甚至还能设计替代的3D SoC系统分割方案,把像是一级快取SRAM等的部分记忆体芯片置于底部,从晶背实现电源供应。晶背PDN除了扩展3D SoC设计的潜能,还曾被提议可用于积层型单芯片逻辑与SRAM的SoC应用,协助达成元件与芯片的进一步微缩。IMEC3D系统整合研究计划负责人Geert Van der Plas说道:「研究结果显示,将电源供应网路转移到晶圆背面是个有趣的解决方案,不仅能用来面对后段制程的布线壅塞挑战,还能减低压降。」「3D SoC方案的主要差别是将一片虚拟晶圆接合到目标晶圆,以利进行晶背研磨和金属化。」他进一步解释。IMEC的合作伙伴近期就宣布在其中一款先进制程芯片中采用这种晶背PDN设计。
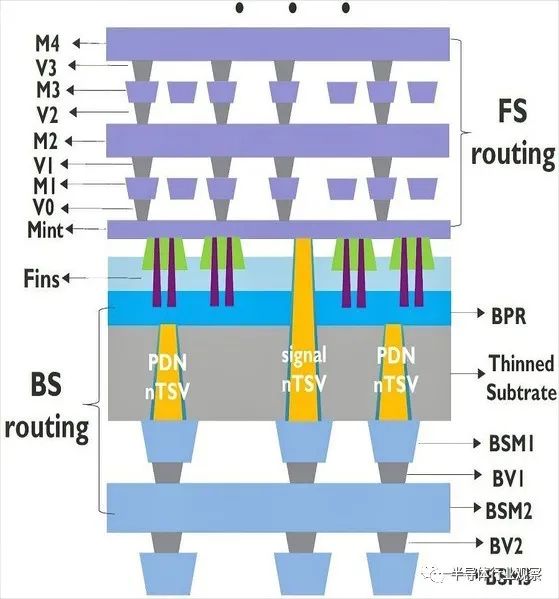
晶背PDN的技术优势已在特定设计中获得验证,而善用晶背的其它效益还可望在全域讯号绕线的应用上浮现。IMEC已联手益华电脑,针对在晶背进行部分绕线的SRAM巨集与逻辑电路设计,首次进行评估与优化。SRAM巨集不仅与记忆体单元阵列有关,还包含位址解码器、控制单元等与处理器设计相关的周边电路。图三: IMEC于2021 IEDM展示传统制程的晶圆正面后段制程、背面PDN和讯号布线。其中,晶背利用纳米矽穿孔(nano-TSV;nTSV)将导线向外连接,包含连至BPR的PDN布线,以及连至晶圆正面导线的讯号布线。
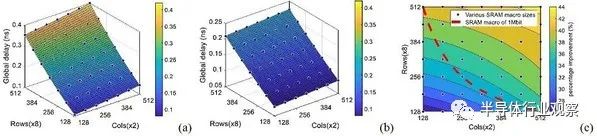
SRAM巨集和逻辑单元的讯号绕线最多需要3层晶背金属层,而纳米矽穿孔负责将晶背导线连接至晶圆正面。SRAM巨集的设计导入了2nm纳米片电晶体,而且只有用于周边电路的全域绕线会与晶背导线相连。逻辑单元则运用环形振荡结构来评估利用晶背进行讯号绕线所带来的影响,逻辑标准单元也采用2nm制程的叉型片。实体布局方面,IMEC选用了同样以2nm叉型片制程设计套件(PDK)制成的64位元Arm CPU,以确保环形振荡器的模拟结果能够发挥作用。Geert Van der Plas解释:「根据研究,与正面布线相较,晶背布线在改善长距离讯号绕线的延迟和功耗上,出乎意料地表现突出。我们成功展示了SRAM巨集的性能最高能提升44%,功耗最多降低30%,逻辑单元的传输则能加速至2.5倍,功耗效率增加60%。」图四: SRAM巨集在不同列行设计下的全域布线读取延迟时间:(a)晶圆正面(b)背面(c)从正面至背面的延迟差距。巨集大小涵盖128*128*16=256kbit~512*512*16=4Mbit。
为了评估这些电路的性能与功耗,IMEC进行了多项实验并建立模型。Dragomir Milojevic指出:「实验涉及了纳米矽穿孔制程在电容与电阻方面的优化,以确保晶圆正面与背面的导线之间能够维持良好的电气连接。这些参数也被馈入模型以进行模拟。最后我们采用设计—技术偕同最佳化(design-technology co-optimization)策略驱动的布线优化技术,可望在未来持续精进。」成果显示,透过降低晶背导线的电容,性能可再提升20%。
这套异质3D SoC方案透过改良系统架构设计与3D整合技术来实现,经证实,是可以有效提升系统性能的可行方法。利用底层晶背进行电源传输或讯号绕线,还能达到其它效能提升。IMEC首度展示了在SRAM巨集与逻辑电路导入晶背互连技术的正面效果。这些晶背导线还能为高效能3D SoC与积层型单芯片SoC实现性能升级。
摩尔芯闻您的半导体行业内参,每日精选8条全球半导体产业重大新闻解读,一天只花10分钟,享受CEO的定制内容服务。与30万半导体精英一起,订阅您的私家芯闻秘书!欢迎订阅摩尔精英旗下更多公众号:摩尔精英、半导体行业观察、摩尔App
250篇原创内容
公众号
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2930内容,欢迎关注。
『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!