AAAI 2022 | 可解释性ViT登场,谷歌AI提出层次嵌套Transformer模型
近来出现的一些视觉Transformer工作开始走向层次化堆叠block的模式,本文对这种层次化的设计进行了分析和改进,作者认为在Transformer模型中通过在非重叠图像块上提取特征,并以分层次的形式将其进行聚合是这种层次化设计的精髓,其中对多个块特征融合的函数(block aggregation function)可以促进跨区域非局部信息的交互。基于这一理念,本文提出了一种层次化嵌套Transformer(NesT),其仅需要在原始ViT代码上修改几行就可以实现。
本文来自谷歌AI研究院,目前已被AAAI2022接收。

论文链接: https://arxiv.org/abs/2105.12723
代码链接:https://github.com/google-research/nested-transformer

相比普通的ViT模型,NesT还有以下三个明显优势:
1. NesT拥有更快的收敛速度,所需的训练数据量也很小,可以同时在ImageNet和小型数据集(如CIFAR)上得到良好的泛化性能。
2. 将NesT扩展到图像生成任务上,在生成速度上相比之前的方法快了近8倍。
3. 在NesT中,通过嵌套的层次结构可以实现特征学习和抽象过程的解藕,同时这种结构可以天然的类比于决策树过程,本文基于此提出了一种全新的模型可解释方法CradCAT,可以对图像的显著性区域进行定位。
目前的ViT模型首先将输入的图像划分为图像块,然后使用类似于NLP模型中的方式对图像块提取特征。随后,使用多个自注意力层(self-attention)进行全局的信息交互,以实现长程的特征提取。最近的一些Transformer工作表明,ViT模型在大规模的标记数据集上可以超过卷积神经网络的精度,但是其在小数据集上进行训练时,优势并不明显。这可能是因为Transformer本身缺乏类似于卷积网络中局部性和平移等效性之类的归纳偏置。
目前已有一些工作对此进行改进,其中具有代表性的例如Transformer原作者Ashish Vaswani发表在CVPR2021上的HaloNets[1],以及微软亚研院获得ICCV2021 Best Paper的Swin Transformer[2]。这些工作都提出了一些特殊操作对自注意力机制进行了修改,先通过对局部块进行关注,随后进行块与块的信息交互。本文提出的NesT采用另一种方式进行改进,即保证原自注意力机制不变,引入聚合函数(block aggregation function)来提高模型的整体性能,同时可以为模型带来一定的可解释性。
二、本文方法
2.1 整体框架
本文方法的整体框架如下图所示,网络整体呈现层次化设计,不同层次中处理图像块的分辨率不同。每个层次中都堆叠了一定数量的标准Transformer层,来独立的对每个图像块提取局部自注意力特征,随后进行分层嵌套。在每两个层次之间设置的块聚合函数用来实现空间相邻块之间的信息传输。需要注意的是,在每个层次中的块都共享一套参数。
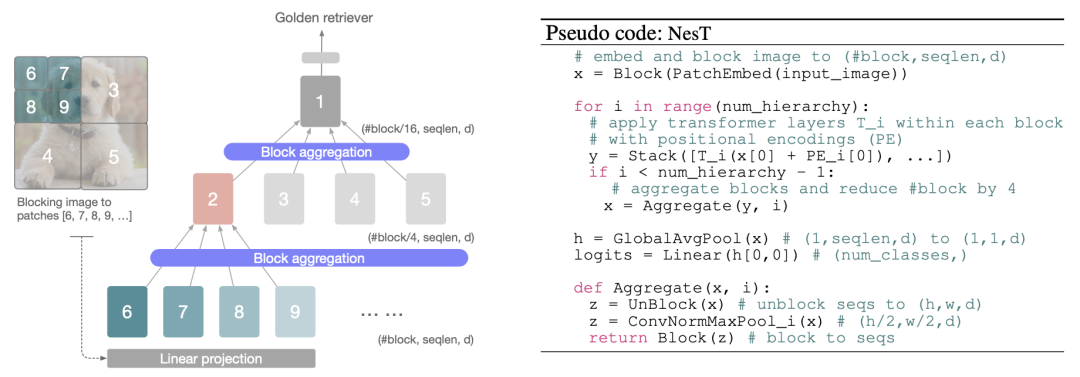
在每个块中,作者堆叠了一定数量的标准Transformer层,其中包含一个多头注意力层(MSA)和一个包含层归一化(LayerNorm)的前馈全连接网络(FFN),同时在每个层次中的序列中也加入了可训练的位置编码向量。图像块在每个Transformer层中的计算基本遵循标准的ViT[3]模式:
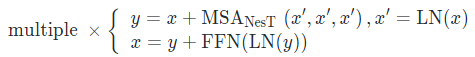
随后通过块聚合函数构建整体的嵌套层次结构,即每四个空间相邻块合并为一个,这种嵌套形式使得NesT非常容易实现,只需要对原始ViT代码修改几行即可,上图右侧为NesT的伪代码实现。
2.2 块聚合函数
从高层次的角度来看,NesT通过嵌套堆叠的方式构成了层次化的特征表示,这有些类似于金字塔的特征设计,同时也增大了模型的感受野。同时NesT聚焦于局部自注意力建模,作者发现在局部自注意力中,进行非局部的信息交换对于维持数据一致性非常重要,先前的Halonet[1]和Swin Transformer[2]分别通过“光晕操作(haloing operation)”和“窗口转换(shifted window)”来实现这一点,通过这种特殊的局部自注意力机制来保证空间的连续性,但是这两者无形中都增加了自注意力层的复杂度。从本文的实现来看,这种复杂的设计其实是不需要的。
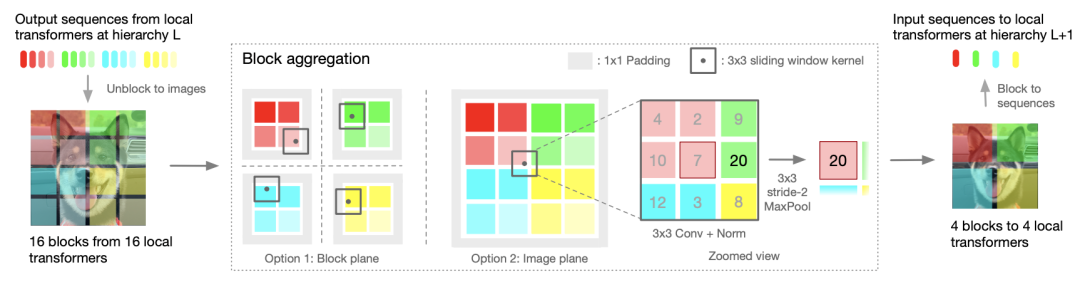
本文通过块聚合函数来实现不同层次块之间的信息通信,具体实现为一个简单的3x3卷积、归一化层和最大池化层。下图展示了块聚合函数分别应用于图像平面(即完整的图像特征图)和块平面(即与将合并的2×2块相对应的部分特征图)上的示意图。尽管二者都在空间上进行卷积操作和合并,但是在图像平面上进行块聚合允许不同层次之间的合并块(呈现不同的颜色)进行信息通信,这增大了模型的感受野。
2.3 GradCAT-梯度树遍历算法
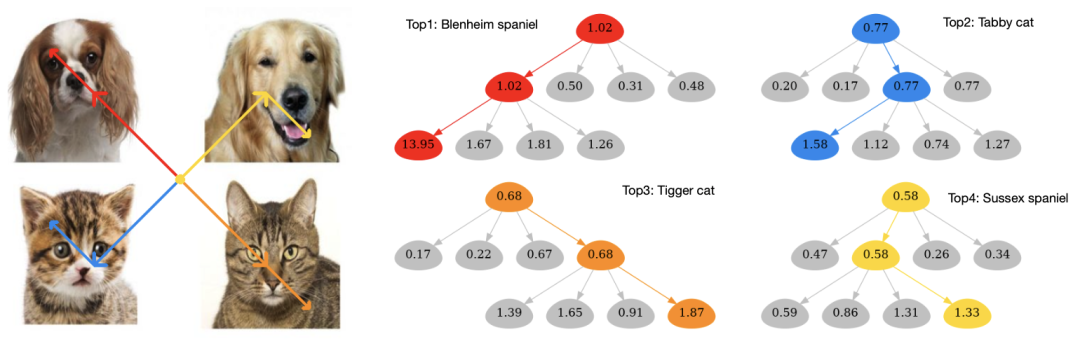
本文的另一大贡献是提出了一种新的模型可解释性方法GradCAT。该方法得益于NesT天然的树形结构,其在进行块划分的过程类似于一个决策树,其中每个块学习当前位置的非重叠图像块的特征,然后通过块聚合函数来选择更为重要的区域。
三、实验效果
本文分别在CIFAR、ImageNet和ImageNet-22K数据集上进行了实验。本文遵循原始ViT[3]设计了三种NesT结构,分别为tiny(NesT-T)、small(NesT-S)和base(NesT-B)。本文方法与其他方法在ImageNet和ImageNet-22K上的对比实验结果如下表所示。
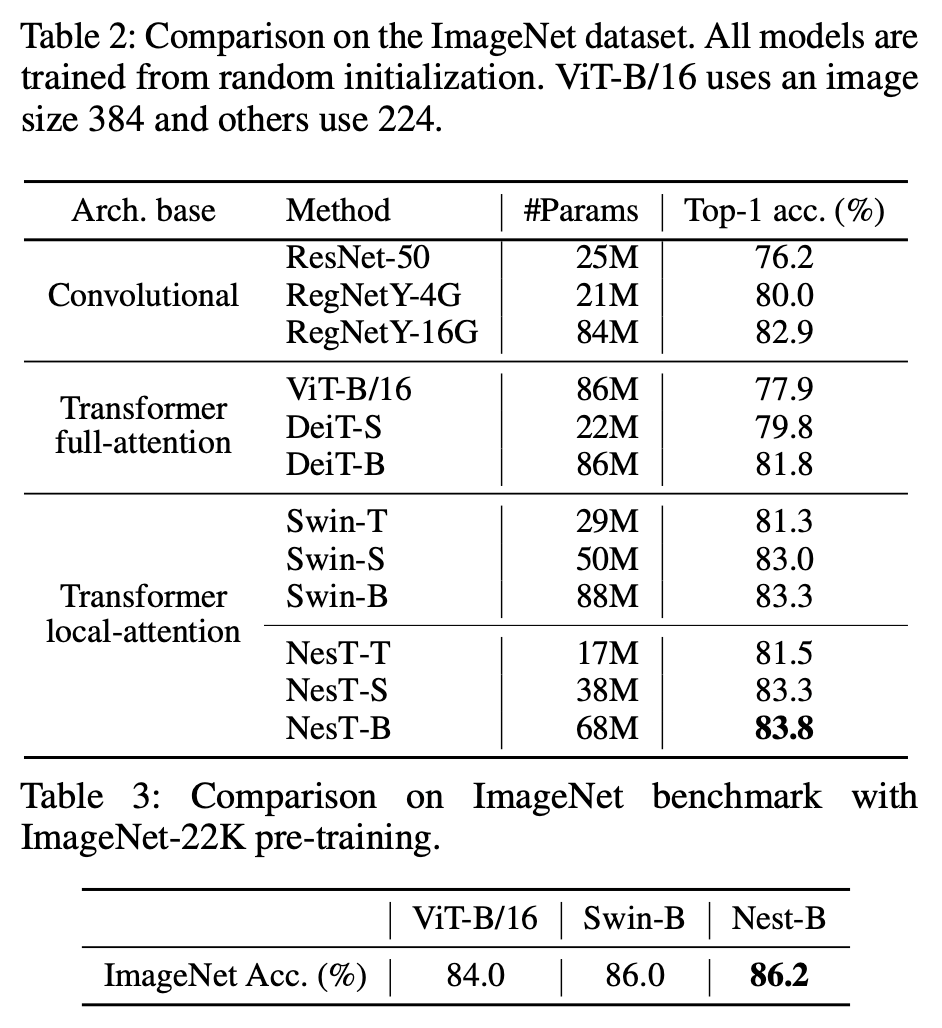
其中在ImageNet上的结果表明,NesT可以更加有效提升局部自注意力的性能,例如NesT-S结构可以与更高参数量的SWIN-B结构的结果持平。
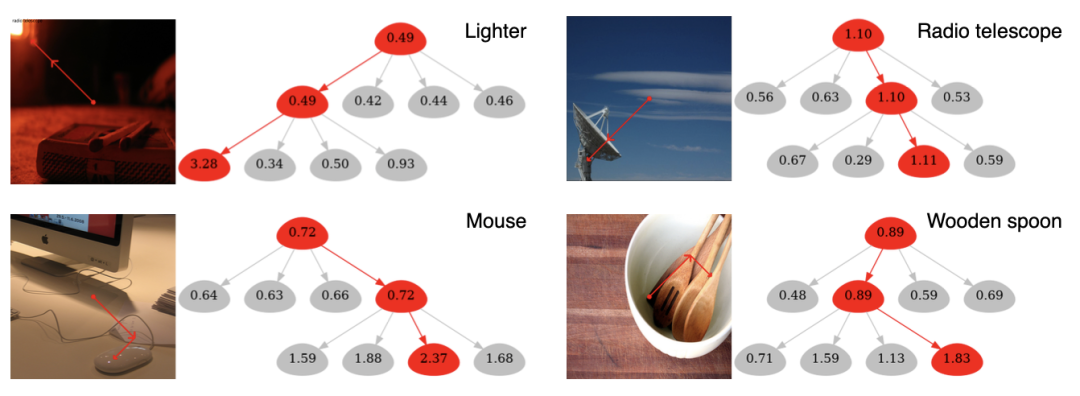
在视觉可解释性实验中,作者展示了使用GradCAT的可视化效果,如下图所示。通过对非重叠图像块的可视化树遍历,我们可以清晰的观察到NesT嵌套结构的决策过程。通过最大梯度回溯,决策路径可以正确定位整幅图像中产生正确预测的对象。
除此之外,作者还展示了一个类激活图(CAM)的对比效果,如下图所示,对比方法包括ResNet50和DeiT。从图中可以看出,NesT可以生成更加清晰的注意力图,更好的收敛于最显著目标的周围。

四、总结
毫无疑问,本文又是Transformer模型向视觉领域迈进的重要一步。本文提出的NesT以更加轻量和简单的实现,就可以显著提高数据效率和模型收敛速度。此外,本文天然的树形嵌套结构可以有效的解藕特征学习和特征信息提取的过程,并生成一种更加合理的特征解释,展现出了Transformer结构在模型可解释性方面的潜力。
[2] Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.
[3] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR.
作者:seven_
Illustrastion by icons8

扫码观看!
本周上新!

关于我“门”
▼

点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球