刚刚过去的冬奥会开幕式,是一场美轮美奂的视觉盛宴,抛弃了2008年夏季奥运会的人海战术,今年的开幕式重点突出的是科技与艺术的融合。
当中,最值得一提的要属和平鸽环节,运用了实时跟踪的AI技术,场地上飘落的雪花紧紧伴随着700多位演员的脚步移动,让人不禁感慨离夏季奥运会开幕只过了半年,人类科技进步竟然如此之大。

梦幻的视觉效果背后,其实是「AI实时视频特效」,即实时捕捉和交互,通过图像识别,几乎0延时捕捉演员位置及姿态,并渲染出相应的美术效果。演员也因此有了自由发挥的空间,无需按照既定的位置进行跑动。这套系统最终根据鸟巢的场地特点进行了算法优化,呈现出「如影随形」的效果。除此之外,AI还可以自动生成逼真生动的视觉效果。开幕式中令人印象深刻的「黄河之水天上来」,是图形处理算法,在大量学习中国传统水墨画之后,按照水墨纹理风格生成的。汹涌澎湃的效果丝毫不输真实的影像纪录。
提到科学与艺术的融合,就不得不提到一位跨世纪的天才——达芬奇。作为一个同时在物理学,数学,解剖学方面都颇有建树的科学家,达芬奇非常擅长将艺术创作与科学探讨结合起来,比如将「黄金分割率」大量应用到绘画作品当中等,这在世界艺术史上是独一无二的。无独有偶,四个世纪后的天才物理学家爱因斯坦也是一位热爱音乐与文学的科学家,他始终认为科学与艺术是相通的,并将艺术与科学奉为毕生追求的事业。另一个传统的科学与艺术的例子,是「莫扎特的音乐骰子游戏」。这个游戏由176条小步舞曲小节,96条三重奏小节,两张写满数字的规则表以及两粒六面筛子组成。游戏规则非常简单,两粒骰子被随机投掷16次,根据投掷结果,规则表中对应的小步舞曲片段被一次选定,组成一支随机的小步舞曲。而数百年后的1956年,Lejaren Hiller和Leonard Isaacson 尝试利用AI谱写了新的音乐。到了2021年,德国的一些科学工作者甚至利用AI续写了贝多芬的第十交响曲。近年来,一些大厂和会议也通过种种形式将AI与艺术紧紧联系了起来,如NVIDIA举办的AI艺术画廊,NeurIPS Workshop,中国人工智学会艺术与人工智能专委会,中国计算机学会计算艺术分会以及2021年10月在北京举办的世界音乐人工智能大会等。这些工作能够促进学术交流和产学研合作,加快了艺术科技的产业化。二、大模型吟诗,Jukebox 谱曲
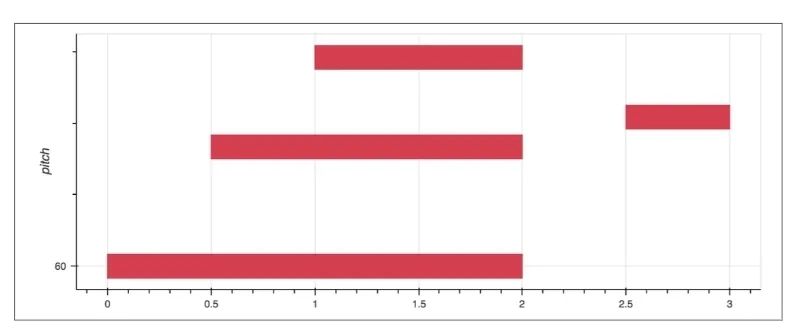
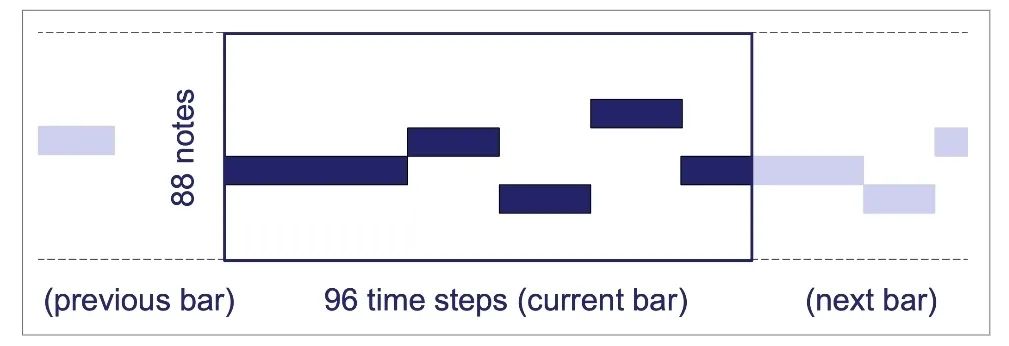
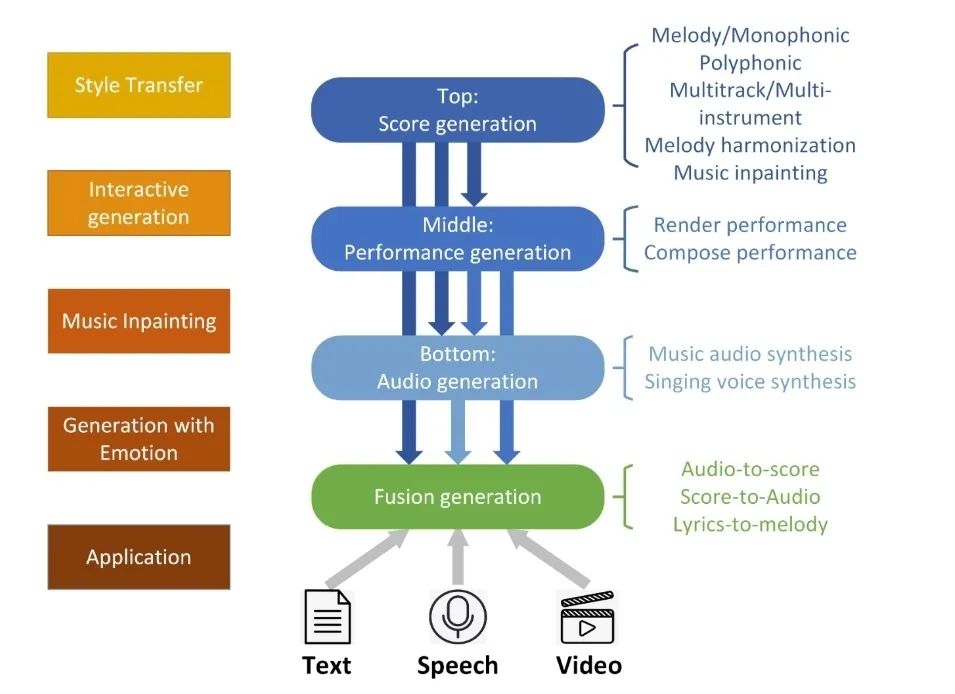
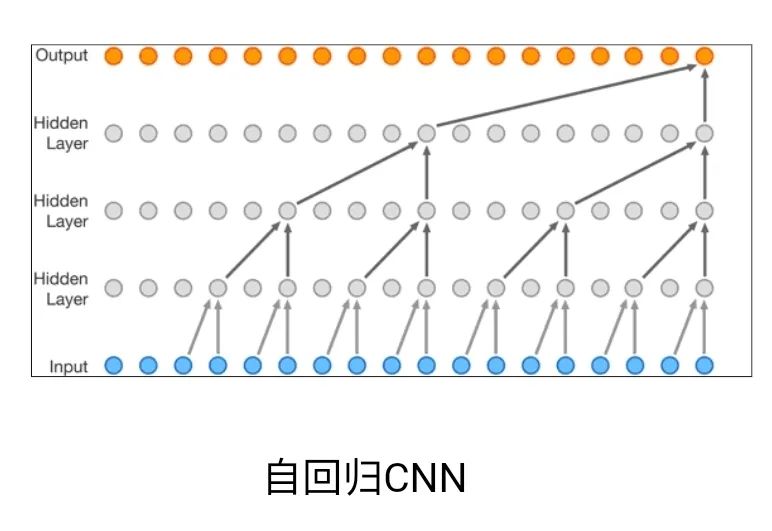
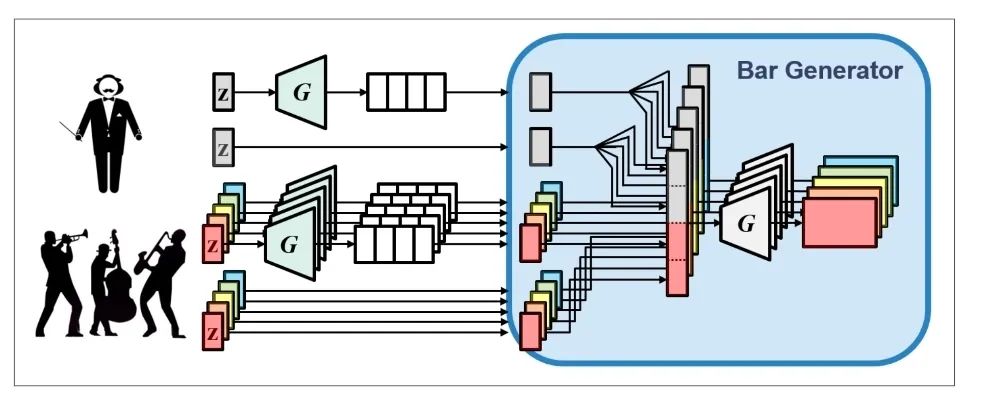
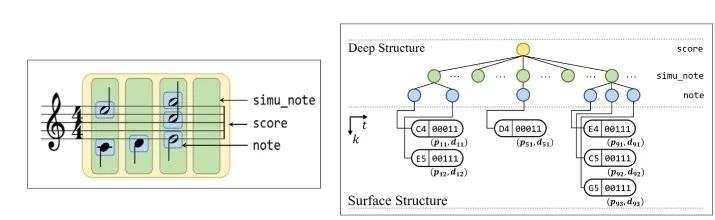
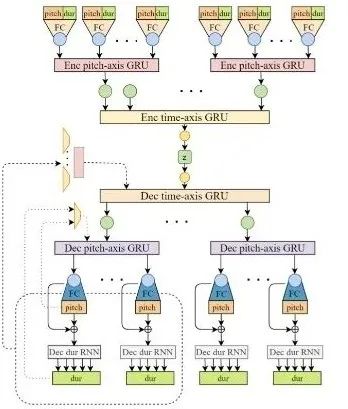
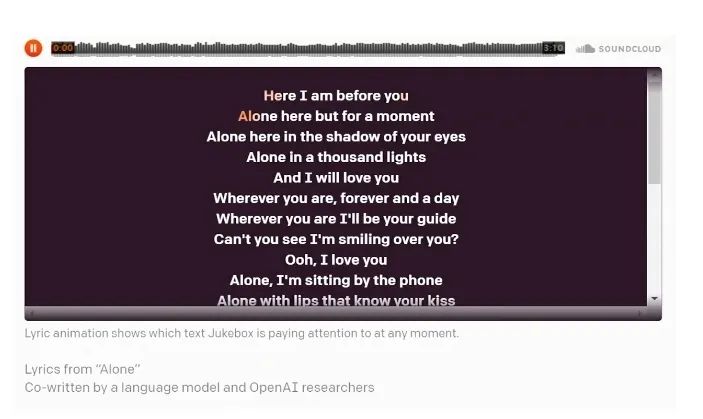
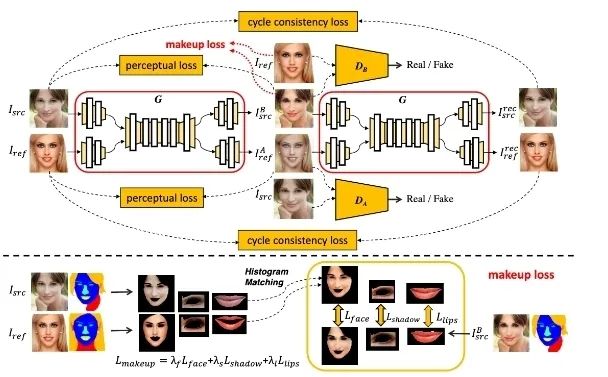
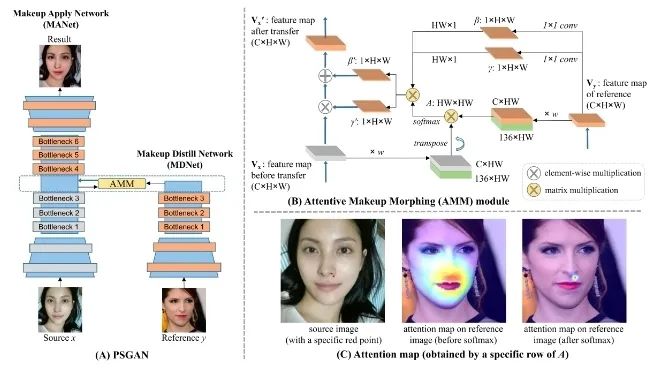
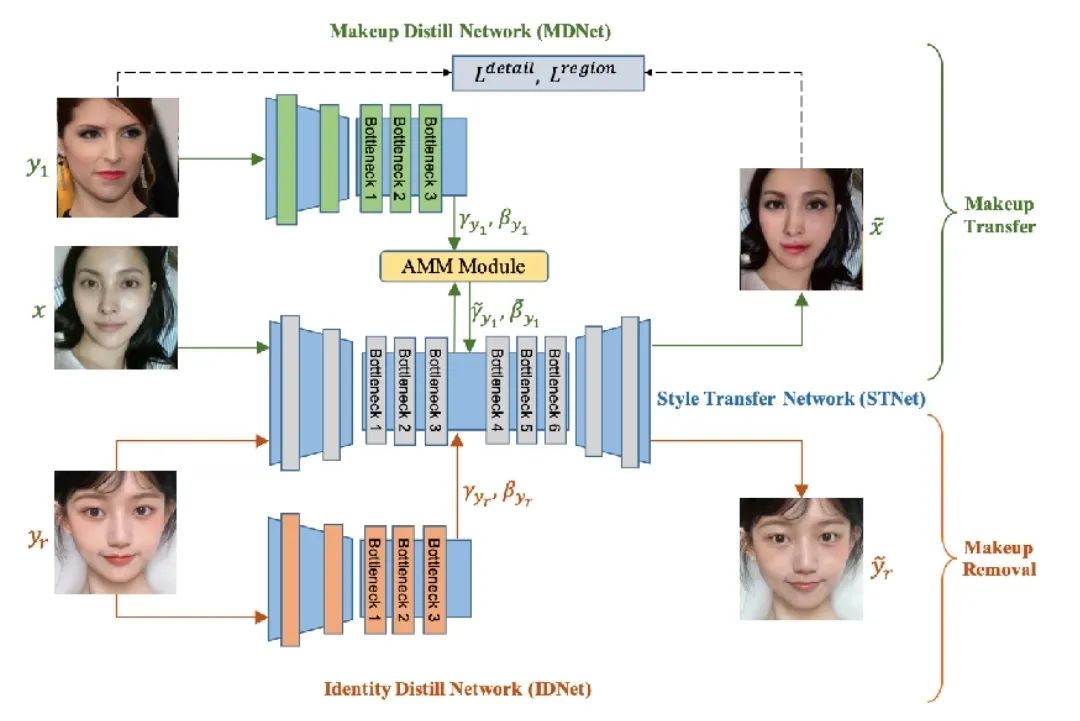
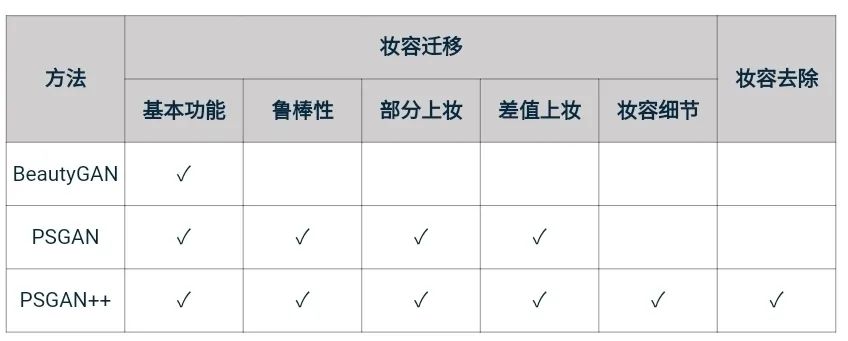
首先,对于文本理解任务,不得不提到「GPT-3」与「悟道」等大模型,这些大模型在诗词创作,问答等任务中取得了十分出色的表现。此外,在进行诗词创作时,清华大学的「九歌」模型表现也很出彩,对于给定的主题,关键词等,他们能够生成比较有意境的诗词。比如《夜过虹桥机场》: 而GPT-3也可以根据给出的一段合适的提示,生成续写诗词。另外,我们还可以利用AI进行文学创作,如给定主题「秋色」,并规定体裁:现代文,对联,文言文,我们可以得到如下的结果:除此之外,美国查普曼大学学生制作了一部短片《solisitors》,该短片20秒之后的剧本都是由AI编写完成,而且与欧·亨利风格的短片一样,影片的最后还设置了一个大反转。出处:Brown T B, Mann B, Ryder N, et al. Language models are few-shot learners[J]. arXiv preprint arXiv:2005.14165, 2020.像文字一样,作曲家设计了各种各样的符号,用乐谱来表示音乐。为了让计算机和程序能够处理、甚至生成音乐,人们设计了各种各样的音乐表示。接下来我们根据不同的音乐表示,梳理音乐生成领域的一些代表性工作。第一种表示形式是音频(Audio),我们通常将音频信号进行短时傅里叶变换,得到梅尔谱,从而进行后续的建模。第二种表示形式是符号化的MIDI事件,每个MIDI事件是一个token,从而整个音乐可以类比为NLP中的句子。MIDI事件包括音符的开始和结束、音符强度、时间移动、节奏变化等。第三种表示形式是钢琴卷帘(Pianoroll)。对于单轨音乐,使用横轴表示节拍(也就是时间),纵轴表示不同音高的音符,例如钢琴的88个音。这样可以用二维数组来直观地表示音乐,就像图片一样,这样可以方便地使用计算机视觉中的方法,比如GAN模型。对于多轨音乐(比如多种乐器),只需要使用不同的维度来表示,就像彩色图片的RGB三个通道一样。 接下来进入到AI音乐创作的部分,音乐生成整体上包含音符生成、演奏效果生成、音频生成三个层级,分别有不同的方法和应用。音乐创作方面早期一个有代表性的工作,是谷歌2016年发布的WaveNet模型,它将音频的波形分为多个时间步,然后使用自回归的卷积神经网络来进行预测。AAAI 18 上发表的 MuseGAN 使用了多轨 Pianoroll 的音乐表示形式,从而将音乐当做图像,利用 GAN 实现音乐生成。这类方法生成的音乐具有较为真实的模式和结构,但无法生成较长的音乐。2019年的Music Transformer是比较早的使用Transformer进行音乐生成的工作。它将音符表示成MIDI形式的token,从而使用类似于NLP中的方法进行序列建模。PianoTree VAE是使用VAE模型进行音乐生成的例子。它基于乐理知识提出了树形结构,将音乐分为note、simu-note、score三个层级,底层的note记录每个音符的音高和时长。上图的VAE中,上半部分对音乐进行编码,得到一个隐向量z,下半部分对z进行解码,重构出整个音乐。在生成时只保留解码器,在学习到的z的分布中随机采样一个z,通过解码得到新的音乐。 然后是Jukebox,由OpenAI提出,它可以基于给定的流派、艺术家和歌词生成演唱音频。它使用了多尺度 VQ-VAE 以压缩音频,基于歌词训练Transformer以生成新的模式,最后使用Transformer和CNN进行上采样和解码。2020年MIT发布的Foley Music可以对静音的音乐演奏视频进行音乐恢复,他们的方法是提取视频中的人体关键点,使用encoder-decoder方式生成MIDI序列,最后合成音频波形。最后是视频背景音乐生成任务,这里介绍的是我们发表于ACM MM2021上的工作,获得了最佳论文奖。背景音乐对于一个视频的观感来说有很重要的作用,但人为的进行背景音乐检索、根据音乐对视频进行剪辑是很消耗时间的,并且还会面临版权问题,因此我们提出使用AI模型自动生成视频的背景音乐。此前的方法只能针对乐器演奏视频进行音乐重建,但不能针对任意的视频生成背景音乐。此外,乐器演奏视频的音乐是由视频唯一决定的,而配乐任务中一个视频可以有多种配乐。因此我们所做的背景音乐生成是一个全新的任务。这个新任务的主要问题是缺少足够的视频-音乐配对数据,无法进行端到端的学习,而且音视频间关系较为复杂。针对于此问题,我们的方法提出了三种音视频间节奏关系。从视频中提取视觉节奏特征,转换为音乐节奏特征后,与用户输入的音乐特征一起,输入到可控音乐生成模型中,生成视频背景音乐。此外,用户可以指定音乐的流派和乐器,从而对音乐进行个性化设置。我们主要提出了音乐与视频的三种节奏关系:1、视觉运动速度与simu-note密度;2、视觉运动显著性与simu-note强度;3、视频时间与音乐节拍第一个关系是视频运动速度和simu-note的密度,我们发现快速的动作通常对应于较急促的音乐,比如,从西班牙斗牛的视频可以看出,运动速度较快的视频,音乐中音符密度比较大。下图为运动速度和音符密度的另一个例子,《泰坦尼克号》电影视频中画面动作较为缓慢,因而音乐也比较舒缓。第二个关系是视频运动显著性和simu-note强度。对于视频转场等特殊情况,音乐中应该有特殊的节拍,使观众在视觉和听觉上都受到震撼。视频中转场较多,音乐中强拍也较为明显。最后一个关系,是视频和背景音乐应当同时开始和结束,比如在一个视频中随着画面淡出,音乐也逐渐结束。介绍完三种节奏关系后,我们介绍Controllable Music Transformer模型,它采用了多轨的符号化音乐表征,将音乐token表示为note token和bar/simu-note token两种类型,分别代表音符以及节奏相关信息。每个token由六种属性构成,包括强度、密度、时长、音高、乐器和节拍。从视频中提取的节奏特征映射到强度和密度两个属性上,从而控制音乐的生成。训练阶段,从音乐中提取特征,控制模型重建该音乐。预测阶段,从视频中提取特征,转换为音乐特征后,控制背景音乐的生成。对于局部音乐特征,包括音符密度、音乐强拍,我们在预测过程中替换 token 的相应属性,实现局部控制。对于全局音乐特征,例如音乐流派以及乐器,用户可以自行指定,置于序列开头。一个典型的例子是世界三大名画之一:荷兰画家伦勃朗《夜巡》的修复:18世纪时,为了迁址到新的阿姆斯特丹市政大厅悬挂,原画的四边曾经被裁剪,因而造成了无法挽回的破坏。直到2019年,荷兰国立博物馆才启动修复项目,利用AI技术补绘《夜巡》。他们通过51 TB 的原画拍摄数据,以临摹本作为负样本,伦勃朗原画为正样本,训练AI学习并模仿伦勃朗的风格,重新绘制这幅画的四边。Language-Guided Image Editing我们尝试用语言指导的图像编辑替代费时费力的手工编辑。比如利用语言直接控制图片进行变亮,改变色调等操作。这里我们提出了一种跨模态循环机制和数据增强策略,以缓解数据不足和不平衡的问题。同时,我们也提出了评估编辑性能的新指标(RSS),使用Speaker模型重新描述输入-输出图像对以评估编辑性能。这也是AI与视觉艺术应用的一个典型例子。我们输入内容图像与艺术图像,输出带有特定艺术风格的图像。这项任务既可以在图像上进行,也可以对视频进行,但在对视频进行风格转换时,需要注意保持视频帧之间的连贯性。受启发于艺术风格转换网络,设计了一个初步可用的系统,集成妆容推荐和妆容迁移。给定一张素颜图像,系统可针对五官进行个性化的妆容推荐;提出深度转换网络(Deep Localized Makeup Transfer Network ) ,根据推荐的妆容生成换妆后图片。2018年,又根据GAN网络对这个工作进行提升。使用生成对抗网络在非成对的数据集上实现实例级别的妆容迁移;收集了Makeup Transfer(MT)数据集,包含近三千张带妆图片与一千张素颜图片。2020年,针对素颜图片与带妆图片中人脸不对齐问题,实现姿态和表情鲁棒的妆容迁移;面向用户友好性,设计可控的部分换妆、差值换妆等个性化妆容编辑。2021年,再次进一步针对PSGAN迁移结果的不足,通过Detail Makeup Loss改进了妆容细节的迁移(高光、腮红);提出卸妆模块,可对带妆图片进行卸妆,并使其与换妆模块整合在一个统一的框架下。
三、未来展望
在智能创作上融合大数据是必然的趋势。俗话说,见多识广,熟读唐诗三百首,不会作诗也会吟,从海量无标注数据中挖掘和提取先验知识对机器智能创作有显著的增益。
随着算力增长,当前的智能创作研究进展大有这个趋势,从前两年NLP领域GPT-3的提出,到音乐生成模型Jukebox以及最近火热的视觉语言预训练模型CLIP,DALL-E,都用跨越式的性能提升证明了大模型和大数据的必要性。机遇和挑战是并存,大模型大数据虽可提供很好的先验,但如何设计好的无监督/自监督代理任务来从有噪声的数据中挖掘适合特定任务的先验知识依旧需要解决。此外,在利用大数据大模型会吟诗之后,需要作诗,更要弄清楚创作的套路和规则,比如作曲作诗都有固有的一些规则,比如韵律和乐理知识来约束,将规则融入到模型才能更好的发挥大数据的能量。除了更大的数据量和算力,我们还可以让艺术家选择性地加入AI的创作过程。这个系统将利用人工智能的高效性,同时保留艺术家对创作过程的可控性,从而创作出更加合理的作品。从这个视角来看,我们不再拘泥于「如何构建更加智能的艺术创作系统」,而是去探索「如何将人的交互加入系统中」。四、Q&A
Q1:为什么选择钢琴曲作为生成音乐的出发点?如果想生成中国古典音乐,有哪些难点?A:首先,选择钢琴是因为钢琴的大和弦不会太难听,在真正生成音乐时,如果采用多个声部的合成方式,曲子听起来会比较悦耳;而中国民乐中很多音的频谱都离中心比较远,这有可能导致多个乐器同时发声时,人耳听起来效果不佳;另外,一些古籍中的乐谱,精华或许在于一些颤音之类的特殊音,这种音乐对于我们目前的建模技术来说,比较难以实现。后续我们希望能够通过比如对民乐进行分类,风格迁移之类的工作,实现这种民乐的合成。Q2:对用户而言,如何准确描述不同音乐家的音乐特征,以生成自己需要的风格的音乐?A:基本上可以从三个方向进行特征提取:一是和弦,不同的作曲家对于和弦的用法是不同的;二是和弦的走向,比如现代音乐的和弦走向有许多固定的套路,古代作曲家们也有不同的和弦走向;三是利用机器提取乐曲的其他特征,然后根据学习的结果对合成的乐曲进行微调。A:音乐方面现在已有客观和主观的评价标准。客观标准包括音乐的悦耳程度,是否和谐,重复性和结构性等;主观方面,刘老师的团队设置了评价界面来进行用户体验研究;另外,也有平台将合成作品与人类的作品一起放在线上售卖,这时可以根据合成作品的成交量来进行评价。Illustration by Julia Gnedina from icons8关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: 点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球