AI毕加索来了,借助CLIP模型轻松画素描!
如果说,深度学习的目标是将低层高维的图像数据,转换为高层低维的抽象表达的话,那素描线一定是一种非常重要的抽象视觉表达。目前,使用计算机对目标生成素描线的技术也是视觉领域中一个非常重要的话题。抽象意味着需要识别目标或者场景的基本视觉概念,随后再将这些概念转换为素描线段或着其他的描述语言。而对于机器而言,首先需要具有非常鲁棒的图像语义提取能力,才可能对任意目标图像生成描述。
本文使用了之前在文本图像合成领域中大放异彩的CLIP(Contrastive-Language-Image-Pretraining)模型[1],并将二者进行巧妙的结合提出了CLIPasso模型。CLIPasso的命名来源于著名画家毕加索(Picasso),本文正是受启发于毕加索的系列石版画作品“Le Taureau”。本文由苏黎世理工学院和特拉维夫大学等单位合作完成。

论文链接:https://arxiv.org/abs/2202.05822 项目主页:https://clipasso.github.io/clipasso/
代码链接:https://github.com/yael-vinker/CLIPasso

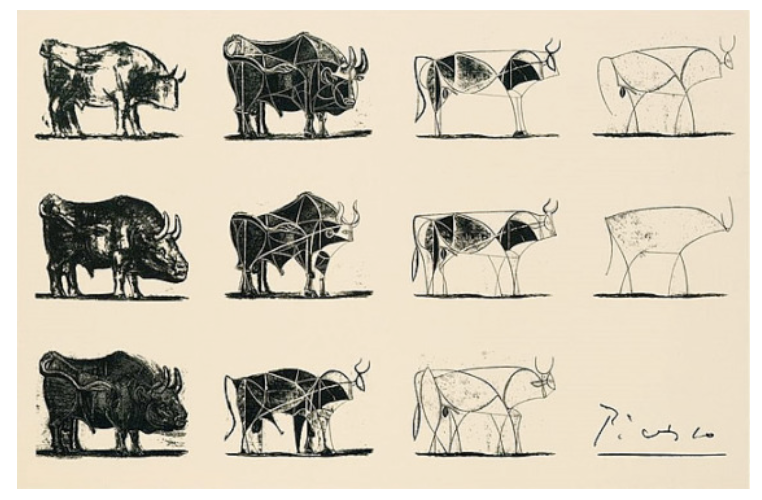
在这一系列中,毕加索描绘了一头公牛的渐进抽象,他将一头公牛从一幅具体的、完全渲染的解剖图变成了只有几条线条构成的素描画,仍然捕捉到了公牛的视觉特征,如下图所示:
CLIPasso使用CLIP的感知损失作为素描线生成的语义监督,而无需像之前方法一样使用大规模素描线数据集进行训练。同时使生成的素描线图展现了多层次的抽象,保持了一定的可辨识性和基础拓扑结构。下面我们来看一下具体的生成效果。

CLIPasso可以像毕加索一样,将一个具体目标逐渐简化为素描图,素描线段的数量同时也表示了抽象的程度,可以看到,即便是最抽象的程度(最右边的火烈鸟和马只画了几笔),人类也可以进行辨识。
一、本文方法
本文将每条素描线表示为具有四个控制点的贝塞尔曲线,为了简单起见,在模型优化阶段,只优化控制点的位置,其他参数例如曲线程度、宽度和不透明度都固定。随后通过改变素描线的数量n来控制图像的抽象程度。
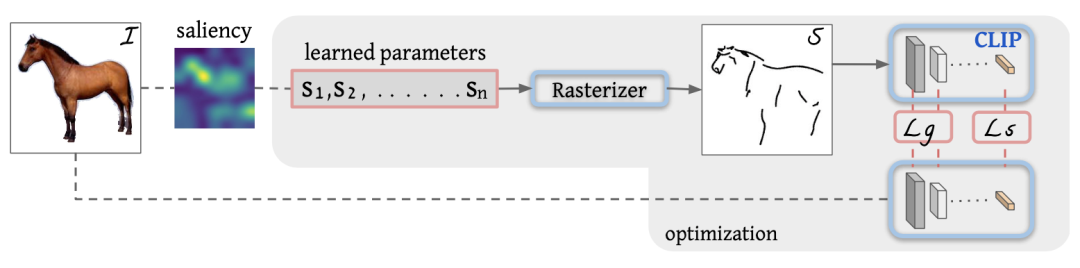
上图为本文方法的整体框架,首先给定图像I,我们的目标是生成同时保留目标语义特征和几何结构的目标图像S,首先对图像I生成一个显著性图寻找显著区域来确定素描线的起笔位置。接下来,在优化过程中,将素描线参数输入到可微分的光栅器R中来生成素描线图,随后将生成的草图S和输入图像I一起送入CLIP模型中计算CLIP感知损失。通过计算损失并不断更新素描线的控制点,模型逐渐达到收敛。
损失函数
由于素描线图具有高度稀疏的特点,因此使用像素级损失函数不足以测量生成图像与标签之间的距离。因此本文创新性的引入了CLIP感知损失,CLIP模型在各种模态的图像数据集上进行了预训练,因此具有计算素描线图像语义的能力,而无需进一步的微调训练。本文使用CLIP模型的最后一层特征对图像进行高级语义编码,将生成草图和输入图像之间的CLIP语义距离可以定义如下:
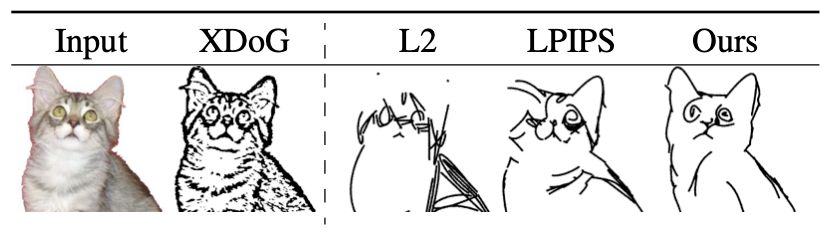
其中XDoG[2]为边缘检测的结果,L2损失只能帮助网络学习简单的彩色像素,LPIPS[3]虽然被定义为语义距离,但是其生成的图像仍然接近边缘检测的结果,使用CLIP损失的结果具有更好的语义测量效果,同时也保留了原有图像的属性。
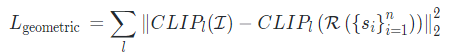
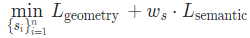
初始位置

二、实验效果
在实验部分,作者首先与之前传统素描线生成的方法进行了对比,这些方法统一通过数据驱动的方式进行优化,需要特殊的数据集进行微调训练,而本文方法与此不同,其不限于训练期间所观察到的类别,没有固定的类别,这使得模型本身具有强鲁棒性。下图展示了本文方法与目前流行的5种方法的对比效果,其中D方法只在含有鞋子的数据集上进行训练,因此这里只能在鞋子的图像上进行对比。这些方法中的每一种都定义了一个特定的目标类别,这个类别会影响模型的最终输出风格,同时也限制了模型的泛化能力。
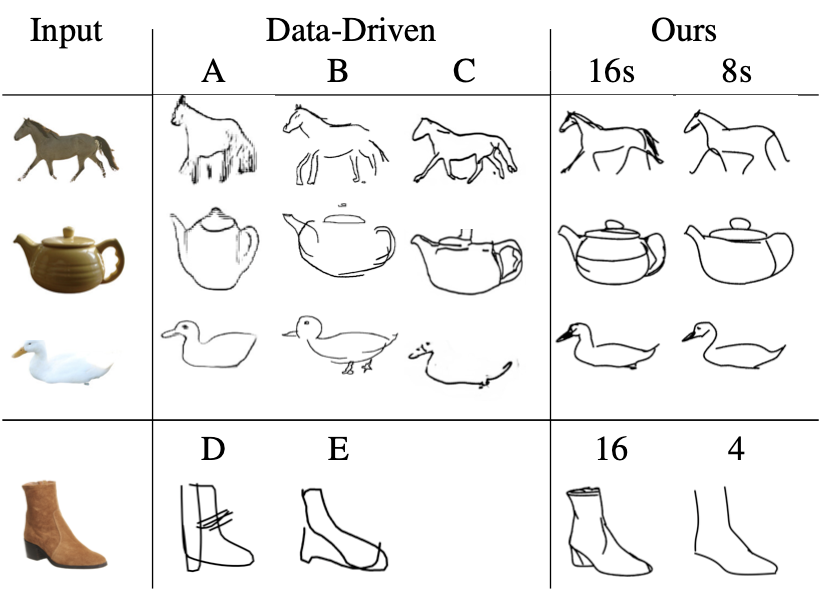
此外,作者也将本文方法与CLIPDraw方法[4]进行了对比,并且将CLIPDraw中的文本输入替换成本文的目标图像,这样可以将输入图像重新编码到与CLIP相同的嵌入空间中。为了进行可视化比较,作者也将CLIPDraw的描绘语言替换成与本文一致的贝塞尔曲线。从下图中可以看出,CLIPDraw的绘制结果虽然可以识别出目标的各个部分,但是缺少了几何结构的稳定性,因而导致整体的结构被打乱了。
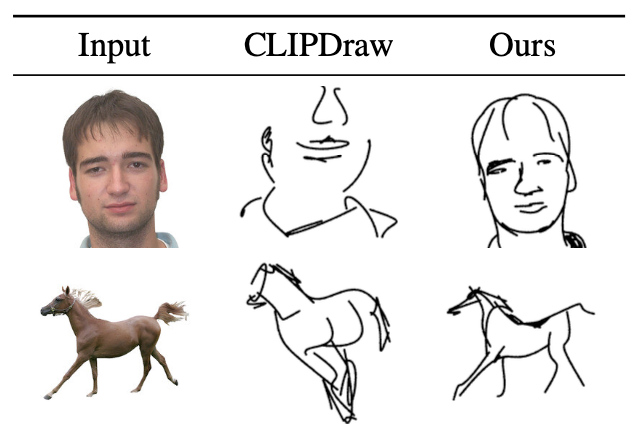
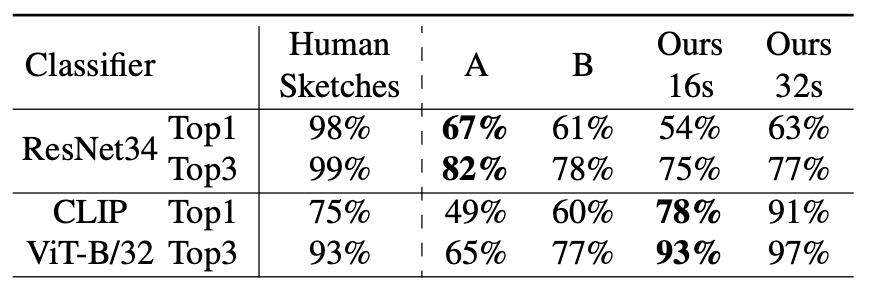
除了视觉效果对比,作者还进行了素描线画可识别性的对比,从SketchyCOCO数据集中选择了五个动物类别,并随机抽取每个类别的五幅图像进行实验。其中包含对生成图像的类别级别和实例级别的对比,共设置了人类感知和分类模型感知两个实验结果。其中人类感知实验邀请了121名受试人员对生成图像进行测试,实验结果如下表所示,在抽象程度为16和32时,本文方法已经有较好的识别效果,即使在高度抽象的8笔画时,仍然也达到了95%的实例可识别能力。
对于分类模型感知实验,作者选用了两个预训练分类器,分别是ResNet34和CLIP ViT-B/32,分类结果如下表所示:
三、总结
本文借助CLIP模型强大的图像语义提取能力,提出了一种新颖的图像素描线合成方法CLIPasso,达到了近乎于毕加索的艺术抽象效果,并且无需在特定的数据集上进行训练。CLIPasso可以推广到各种类别上进行快速高效的草图绘制,同时保留原图在类别级别和实例级别的语义视觉特征。
但是其仍存在一定的缺陷,例如在面对有复杂背景的图像,生成素描线图可能会受到背景的影响,作者提出可以通过背景掩码预处理进行屏蔽。
此外,由于CLIPasso在绘图时,所有的笔画同时进行优化,因此在开始绘制之前,必须先手动确定好笔画的数量,才能保证最后的抽象程度,作者称在后续的工作中可以将生成图像的抽象层次也作为一个可学习的参数进行优化。
参考文献
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. CoRR, abs/2103.00020, 2021.
[2] Holger Winnemoller, Jan Eric Kyprianidis, and Sven C. Olsen. Xdog: An extended difference-of-gaussians compendium including advanced image stylization. Comput. Graph., 36:740–753, 2012.
[3] Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018.
[4] Kevin Frans, Lisa B. Soros, and Olaf Witkowski. Clipdraw: Exploring text-to-drawing synthesis through language-image encoders. CoRR, abs/2106.14843, 2021.
作者:seven_

扫码观看!
本周上新!

关于我“门”
▼

点击右上角,把文章分享到朋友圈
点击“阅读原文”按钮,查看社区原文
⤵一键送你进入TechBeat快乐星球