来源:内容由半导体芯闻(ID:MooreNEWS)编译自tomshardware,谢谢。
半导体芯闻您的半导体行业内参,每日精选8条全球半导体产业重大新闻解读,一天只花10分钟,享受CEO的定制内容服务。与30万半导体精英一起,订阅您的私家芯闻秘书!欢迎订阅摩尔精英旗下更多公众号:摩尔精英、半导体行业观察、摩尔App
256篇原创内容
公众号
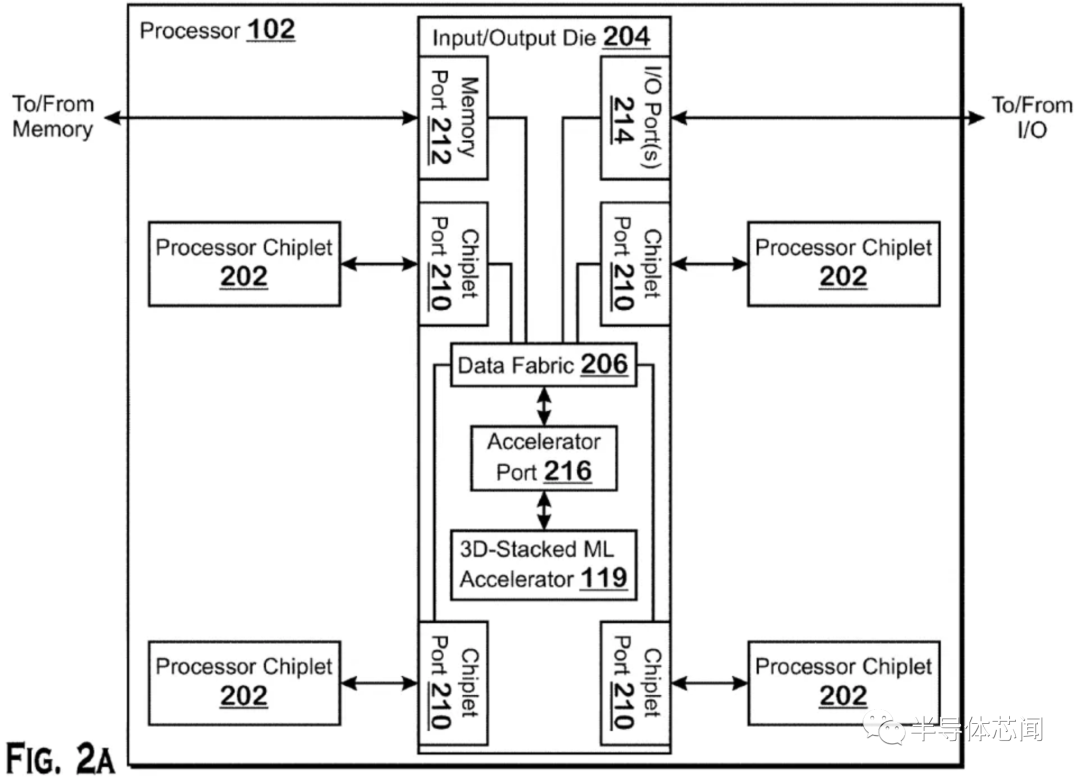
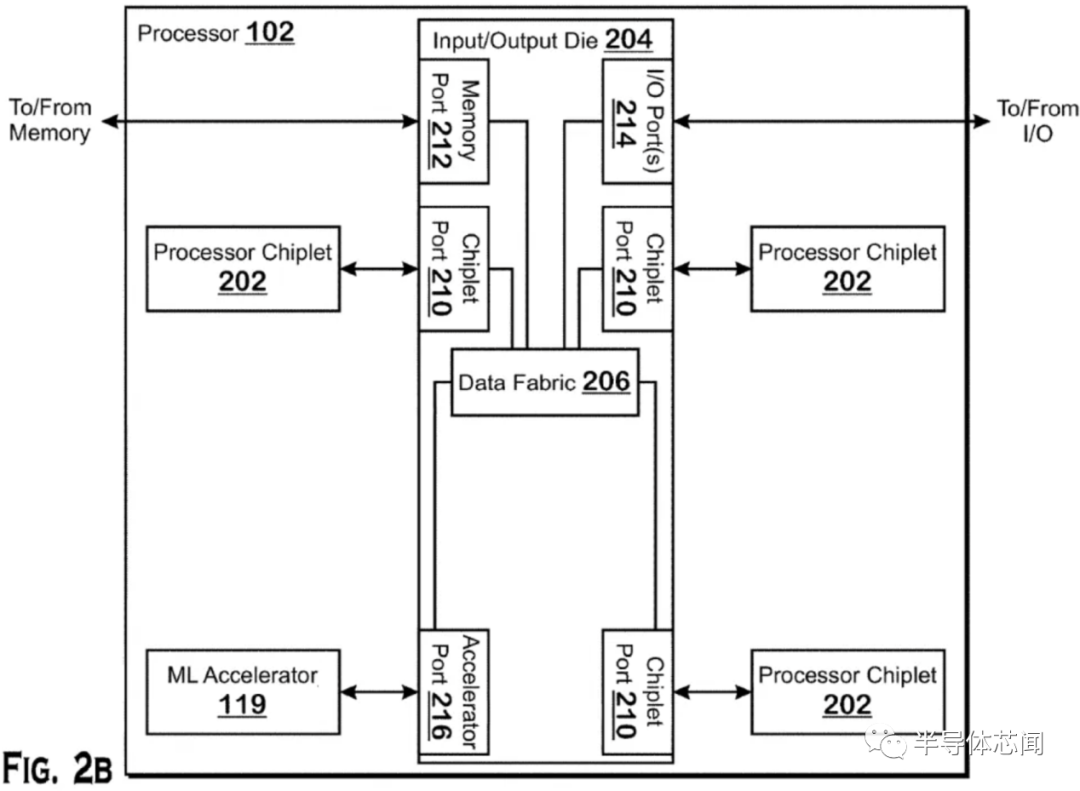
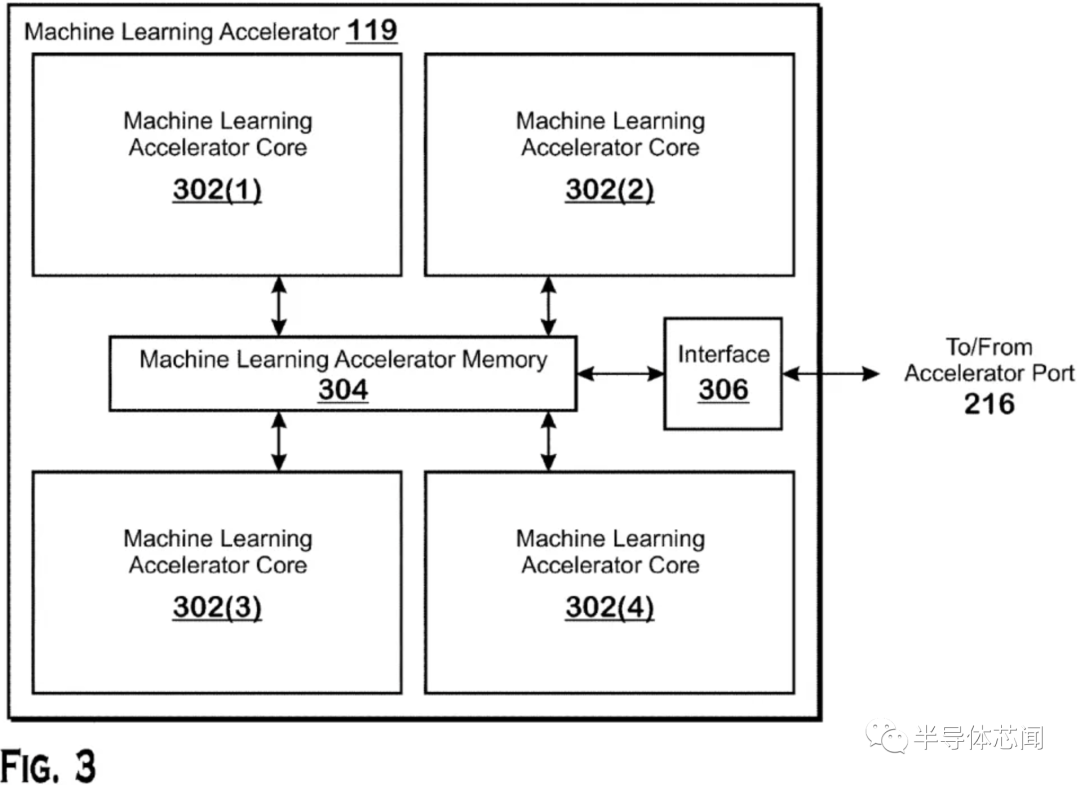
AMD 在其财报电话会议上宣布,它将在其 CPU 产品组合中注入 Xilinx 的 FPGA 驱动的 AI 推理引擎,首批产品计划于 2023 年上市。消息表明 AMD 正在迅速采取行动,以整合其 540 亿美元收购 Xilinx 的成果加入其阵容,但这并不完全令人惊讶——该公司最近的专利表明,它已经在实现将 AI 加速器连接到其处理器的多种方法方面取得进展,包括使用复杂的 3D 芯片堆叠技术。AMD 将其 CPU 与同一封装中的内置 FPGA 配对的决定并不是全新的——英特尔在 2015 年底以 167 亿美元收购 Altera获得的 FPGA 产品组合中尝试了相同的方法. 然而,在英特尔早在 2014 年宣布了 CPU+FPGA 组合芯片甚至演示了测试芯片之后,该芯片直到 2018 年才到货,然后只是以有限的实验方式。显然,这种方式走到了死胡同。因为多年来我们没有听到更多关于英特尔项目或其任何其他衍生产品的消息。AMD 尚未透露其 FPGA 注入产品的任何细节,但该公司将 Xilinx FPGA 芯片连接到其芯片的方法可能会更加复杂。虽然英特尔利用标准 PCIe 通道及其 QPI 互连将其 FPGA 芯片连接到 CPU,但 AMD 最近的专利表明,它正在开发一个可容纳多种封装选项的加速器端口。这些选项包括 3D 堆叠芯片技术,类似于它目前在Milan-X 处理器中用于连接 SRAM 小芯片的技术,将 FPGA 小芯片融合到处理器的 I/O 芯片 (IOD) 之上。这种芯片堆叠技术将提供性能、功率和内存吞吐量优势,但正如我们在AMD 现有的使用 3D 堆叠的芯片中看到的那样,如果将小芯片放置在靠近计算芯片的位置,它还会带来阻碍性能的热挑战。AMD 在 I/O 芯片上放置加速器的选择非常有意义,因为它有助于解决热挑战,从而使 AMD 能够从相邻的 CPU 小芯片 (CCD) 中提取更多性能。AMD 还有其他选择。通过定义一个加速器端口,该公司可以在其他裸片之上容纳堆叠的小芯片,或者简单地将它们安排在使用分立加速器小芯片而不是 CPU 小芯片的标准 2.5D 实现中(见上图)。此外,AMD 还可以灵活地使用其他类型的加速器,例如 GPU、ASIC 或 DSP。这为 AMD 自己的专有未来产品提供了过多的选择,还可以让客户将这些不同的小芯片混合和匹配到 AMD 为其半定制业务设计的定制处理器中。随着数据中心定制浪潮的持续,这种基础技术肯定会派上用场,AMD 自己最近发布的128 核 EPYC Bergamo CPU 就是明证。它带有一种针对云原生应用程序进行了优化的新型“Zen 4c”内核。AMD 已经使用其数据中心 GPU 和 CPU 来处理 AI 工作负载,前者通常处理训练 AI 模型的计算密集型任务。AMD 将主要使用 Xilinx FPGA AI 引擎进行推理,它使用预先训练的 AI 模型来执行某个功能。AMD 自适应和嵌入式计算集团总裁 Victor Peng 在公司财报电话会议上表示,赛灵思已经在图像识别和嵌入式应用和边缘设备(如汽车)中的“各种”推理应用中使用了 AI 引擎。Peng 指出,该架构是可扩展的,非常适合公司的 CPU。推理工作负载不需要那么多的计算能力,并且比数据中心部署中的培训更为普遍。因此,推理工作负载被大规模部署在庞大的服务器群中,Nvidia 创建了 T4 等低功耗推理 GPU,而英特尔则依靠其 Xeon 芯片中的硬件辅助 AI 加速来解决这些工作负载。AMD 以差异化芯片为目标定位这些工作负载的决定,可能使该公司在某些数据中心部署中与英伟达和英特尔一较高下。不过,一如既往,软件将是关键。AMD 首席执行官 Lisa Su 和 Peng 都重申,公司将利用 Xilinx 的软件专业知识来优化软件堆栈,Peng 评论说:“我们绝对致力于统一的整体软件,支持广泛的产品组合,尤其是在 AI 方面。所以你会在金融分析师日听到更多关于这一点的信息,但我们肯定会在推理和训练方面都倾向于人工智能。”
半导体行业观察最有深度的半导体新媒体,实时、专业、原创、深度,60万半导体精英关注!专注观察全球半导体最新资讯、技术前沿、发展趋势。欢迎订阅摩尔精英旗下公众号:摩尔精英MooreElite、半导体芯闻、摩尔芯球。
2595篇原创内容
公众号