Arm发布全新CPU/GPU IP:Cortex-X3性能提升34%,新旗舰GPU可支持光线追踪
去年5月,Arm发布了第一代基于64位ARMv9指令集的处理器IP:超大核心Cortex-X2、高性能大核心Cortex-A710,高能效小核心Cortex-A510。同时,Arm还发布了三款Mali GPU IP——Mali G710/G510/G310。
时隔1年之后,6月28日,Arm带来了全新的Arm IP组合,其中包括第二代的ARMv9 CPU内核Cortex-X3和Arm Cortex-A715,并对Cortex-A510和 DSU-110(DynamIQ 共享单元)进行了重要更新,提升了Cortex-A510的能效表现,同时DSU-110最高可支持12核心。

Arm表示,新的 Armv9 CPU 展示了其对释放计算性能的承诺,旨在突破峰值性能的极限并提供卓越的持续性能和效率。
同时,新的Armv9 CPU和对Arm Cortex-A510与DSU-110的更新构成了Arm新的全面计算解决方案 (TCS22)的基础。
Arm全面计算战略植根于开发者可及性、安全性和计算性能,旨在为所有消费级设备市场提供优异的性能表现。通过优化的系统设计和实施,助力合作伙伴不断突破极限。
与此同时,Arm还推出了全新的旗舰级GPU产品 Arm Immortalis。这是首款可在移动端支持基于硬件的光线追踪的 GPU,可提供更为真实的沉浸式游戏体验。
Cortex-X3:性能最高提升34%
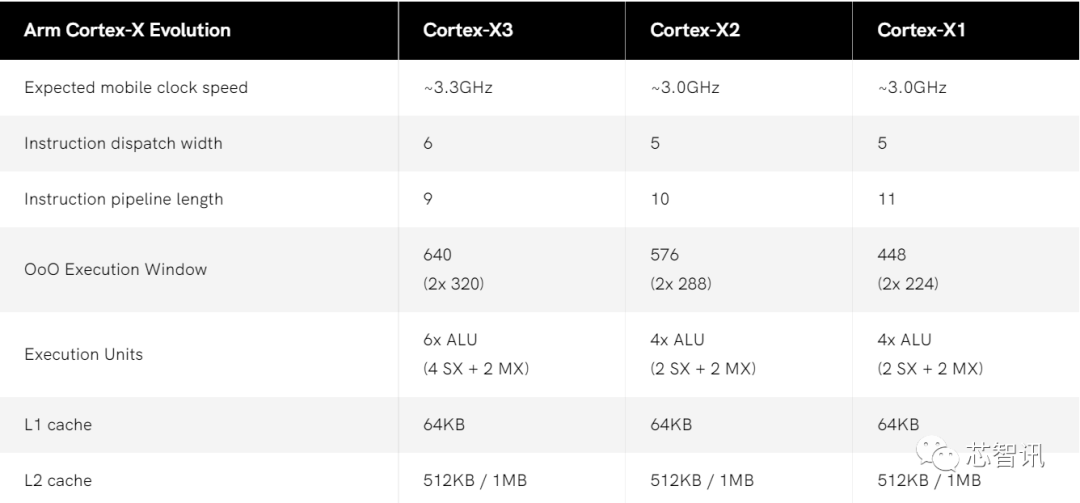
作为Arm面向超高性能市场的第三代Cortex-X系列CPU IP,Cortex-X3同样是一款面向旗舰级智能手机/平板或笔记本产品的CPU IP,相比上一代的Cortex-X2来说,Cortex-X3带来了双位数(相同工艺制程下大约提升了11%)的IPC性能提升。
具体来说,如果是应用在旗舰级Android智能手机/平板电脑上,Cortex-X3将可带来25%的性能提升;如果是应用在Windows on Arm笔记本电脑设备上,Cortex-X3则可带来34%的性能提升。

虽然,Arm并没有介绍Cortex-X3的具体能耗表现,但是根据Arm提供的一张图显示,在SPECint_base2006测试下,在相同的性能水平,Cortex-X3的功耗通常要高于Cortex-X2。虽然在最高性能下,Cortex-X3的功耗更高,但是性能提升的幅度要比功耗提升的幅度更高。这也意味着Cortex-X3的能效表现比Cortex-X2更好。
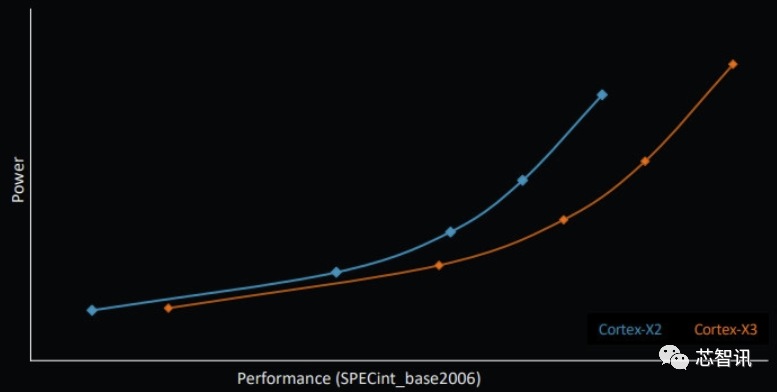
根据Arm向媒体透露的数据显示,Coretx-X3内核(按照时钟频率相当于3.6GHz、拥有1MB L2 和 16MB L3缓存进行模拟)的峰值性能要比今年英特尔中高端 Core i7-1260P处理器的P核(性能内核)高出34%。而这一数据是基于在SPECRate2017_int_base 单线程基准测试中得出的。不过,如果与苹果的M系列的高性内核似乎仍有差距。
相比前代产品来说,Cortex-X3内核之所以能够实现在IPC性能上的大幅提升,主要得益于其核心前端的大量优化工作,比如改进了分支预测准确性,并带来了更低的延迟,这要归功于用于间接分支(带指针的分支)的新的专用结构。同时,L1/L2分支目标缓冲区 (BTB) 也显著增加了50%,L0 BTB 容量更是达到了原来的10倍,并允许预测器提前获取更多指令以利用更大的BTB。
此外,Cortex-X3还拥有一个比Cortex-X2要小50%(与 X1 相同的 1.5K 条目),但是却更高效的微操作(解码指令)缓存,这要归功于减少抖动的改进填充算法。这种较小的 mop 缓存还允许 Arm 将总流水线深度从 10 个周期减少到 9 个周期,从而减少发生分支错误预测和刷新流水线时的惩罚。
不过,如果要与英特尔在笔记本电脑市场竞争,Arm芯片设计厂商需要集成更多的Cortex-X3内核以及其他效率内核进行组合。比如英特尔新的面向轻薄笔记本电脑的28瓦处理器,就拥有四个性能内核和八个效率内核。
对此,Arm也对于此前的推出的DynamIQ 共享单元DSU-110进行了升级,使得Arm芯片设计厂商能够将最多12个Cortex-X3内核或其他内核整合到一个处理器当中(此前最多只支持8个内核),并支持高达 16MB 的 L3 缓存。同时具有最新的 ISA 功能。
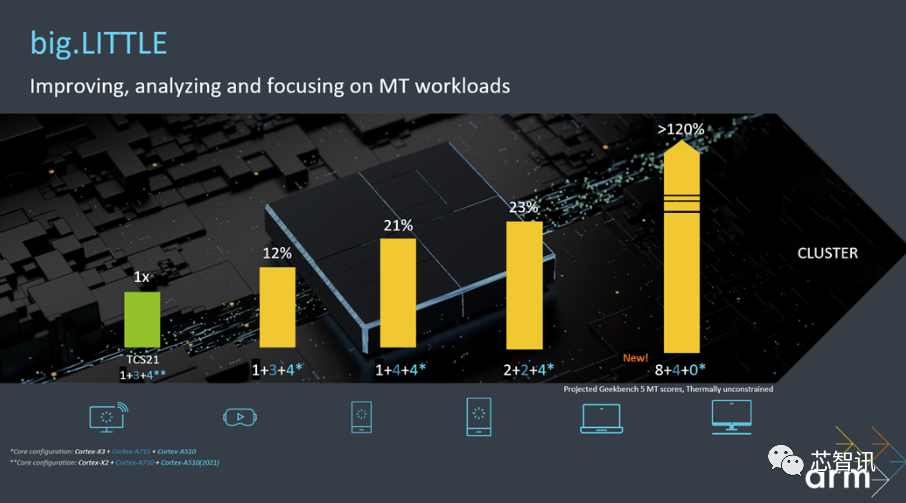
Arm 产品管理高级总监 Saurabh Pradhan表示,“这些变化提高了我们合作伙伴的灵活性,并提供了资源来充分发挥Arm CPU 的潜力,从而改善用户体验。我们的合作伙伴现在可以针对具有新配置(例如 8 个 Cortex-X3 CPU 内核和 4 个 Cortex-A715 CPU 内核)的高端笔记本电脑设备,解锁新一代消费设备。”
Cortex-A715:高性能与高能效的平衡
Cortex-A715是Arm在去年推出的高性能大核心Cortex-A710的继任者,主要面向需要兼顾高性能和能效的移动设备。需要指出的是,Cortex-A715仅支持AArch64 64位指令而不再兼容32位,而此前的Cortex-A710则保留了对于32位的兼容。
具体性能及能效表现上,Arm表示,在相同主频和相同制造工艺的情况下,Cortex-A715 的性能比 Cortex-A710 提高了5%。虽然这样的性能提升幅度远低于之前Cortex-A710相比Cortex-A78的性能提升的幅度(10%)高出 10%。值得可喜的是,Cortex-A715 的效能比Cortex-A710提升了20%,这意味着Cortex-A715在性能保持提升的同时,功耗能够大幅降低,提升设备的续航时间。
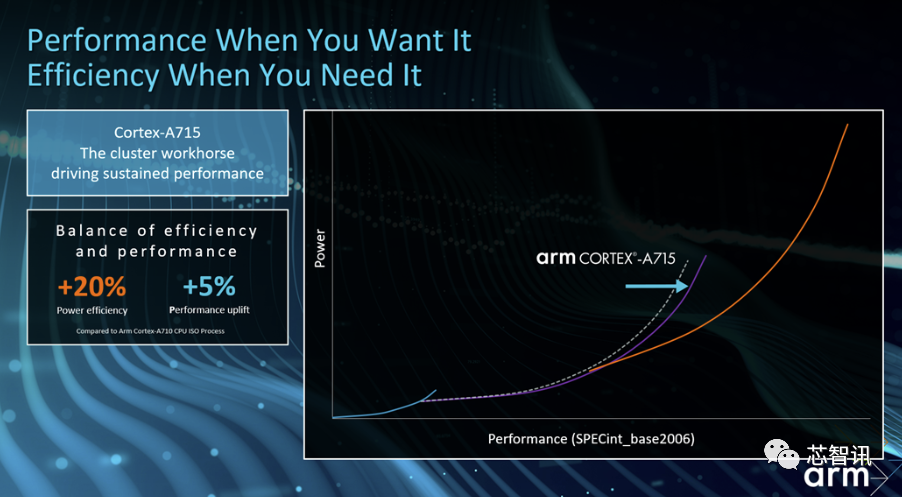
Arm表示,Cortex-A715在能效上的大幅提升,将推动其成为 big.LITTLE CPU 集群当中的CPU内核集群主力。
新版Cortex-A510:功耗进一步降低
除了新的CPU内核之外,Arm还对去年的推出的Armv9 CPU内核Cortex-A510进行了更新,这个小核CPU主要面向高能效、低功耗而设计。Arm在保持了2021版本Cortex-A510性能的基础上,提升了能效表现,使得其功耗进一步降低了5%。
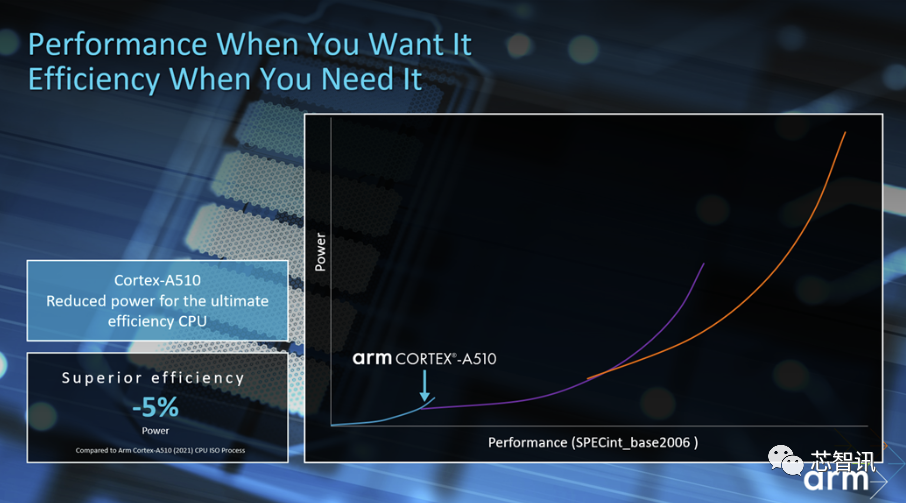
Arm表示,我们将小核CPU的终极效率推向了全新的高度,更低的功耗意味着终端设备可以获得更长的电池续航时间。
第二代Armv9的安全演进
Arm通过第二代 Armv9 CPU,引入了全新的非对称内存标记扩展 (MTE) 和增强的特权访问永不 (EPAN),以改进访问控制。
MTE 检测可防止整个系统的内存安全漏洞,为应用程序开发人员提供上市时间优势。支持 MTE 的设备可以快速有效地识别代码中的缓冲区溢出和堆损坏。
非对称 MTE 在这些安全漏洞的速度、精度和目标之间提供了更高的灵活性。这有利于软件开发与更稳定的应用程序,同时也使 MTE 能够在整个生态系统中更广泛地推出。

全新旗舰系列GPU:Immortalis-G715,支持光线追踪
一直以来,Arm每年都会更新其Mali系列GPU,Mali系列GPU也是迄今为止全球出货量最大的 GPU,目前已达到了80亿个。但是今年,Arm意外的推出了名为“Immortalis”的全新旗舰系列GPU,旨在为旗舰级智能手机提供最高性能和最佳图形性能,最卓越的游戏体验。
作为“Immortalis”系列的首款产品——Immortalis-G715,相比前代的Mali-G715 GPU带来了诸多的改进和新的功能。其中,包括用于显着节能和进一步提升游戏性能的可变速率着色 (Variable Rate Shading) 图形功能,以及改进的执行引擎,并在硬件层面支持光线追踪,支持超过10个内核以上的组合。Mali-G715只支持7-9 个内核,Mali-G615仅支持最多6个核心。

具体来说,所谓“可变速率着色”是一种新的图形功能,它通过优化渲染在图形和视觉效果方面提供显着的节能和性能提升。从本质上讲,它需要一个场景并将渲染集中在需要它的部分上,并以精细的像素粒度进行渲染。通常,这将是游戏动作发生的地方。需要较少焦点的区域(例如背景风景)以更粗的像素粒度进行渲染。如下图所示,游戏场景仍将保持其感知的视觉质量,但会节省能源。在游戏内容上启用可变速率着色时,我们看到每秒帧数 (FPS) 提高了 40%。

在执行引擎上,Arm重新设计了执行引擎的关键元素,以提高计算能力和能源效率。与上一代 Mali GPU 相比,我们重新设计了Immortalis-G715的转换块以显着减少面积。Arm还重新审视了在 Mali-G710 中重新调整的融合乘加 (FMA),以进一步提高电源效率。此外,Arm将 FMA 模块增加了一倍,以进一步提高功率,以提供更高级视觉效果所需的计算。最后,Arm还增加了对矩阵乘法指令的支持,这对于计算摄影和图像增强等移动用例至关重要,以帮助实现 2 倍的架构 ML 改进。
通过所有这些变化,我们可以巧妙地提高功率,将 FMA 功率提高 2 倍,但面积仅增加 27%。从本质上讲,Arm将计算能力提高了一倍,而硅面积只是适度增加。
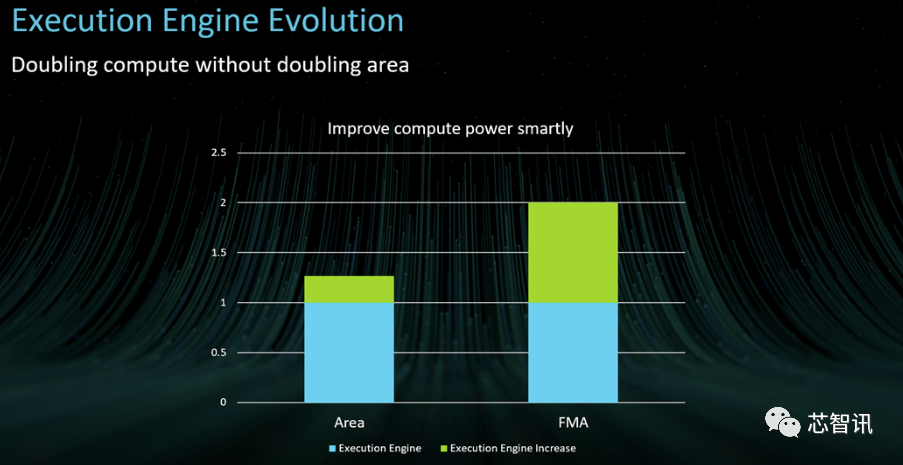
除了执行引擎之外,Arm还在新 GPU 的其他领域进行了 PPA(性能、功耗和面积)改进。
命令流前端(去年随 Mali-G710 推出的一项功能)已变得更快。这是通过添加基于硬件的跨流同步、添加更多本机命令和增加记分板数量来实现的。峰值三角形吞吐量增加了两倍。Arm优化了纹理映射器中的显式 LOD(细节级别)查找以使吞吐量翻倍,并添加了坐标预处理器单元以提高立方体贴图查找的效率。最后,Arm将 Arm 固定速率压缩 (AFRC) 技术(在去年的主流 Arm Mali-G510 GPU 中首次引入)添加到我们的新 GPU 中以节省带宽。
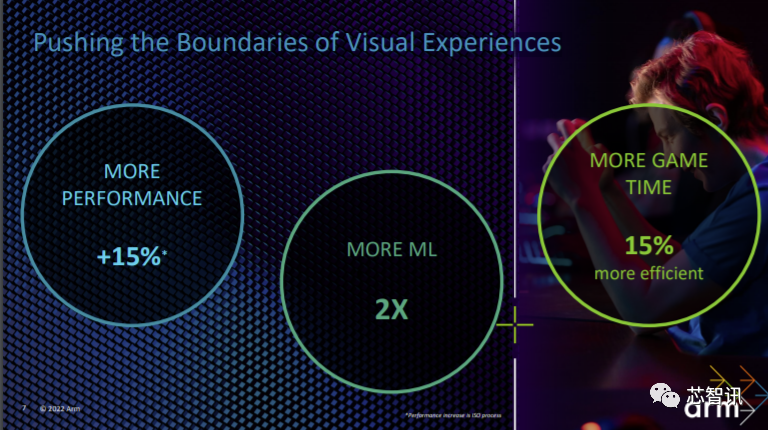
具体性能表现上,Immortalis-G715与上一代高级和次高级 Mali GPU 相比,仅微架构的性能就提高了15%。此外,Immortalis-G715还将带来2倍的机器学习性能的提升,15%的能效提升。
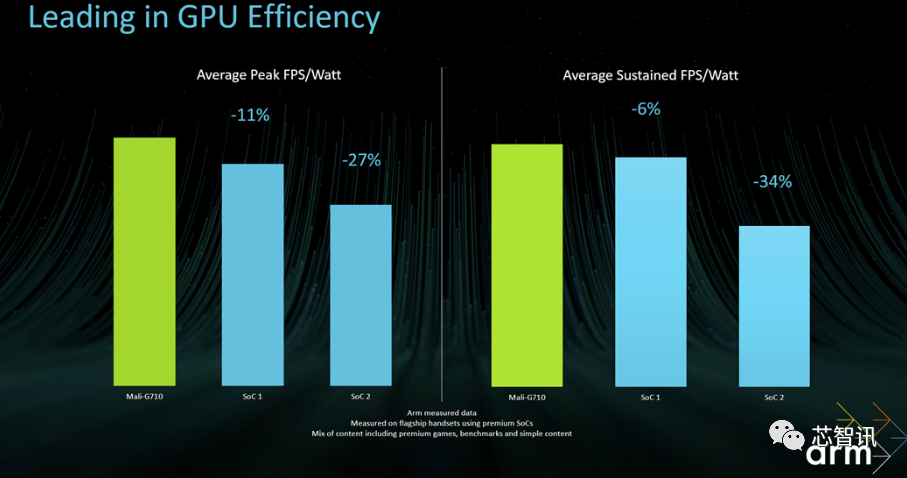
Arm表示,Immortalis-G715 GPU的能效提升是建立在Arm Mali-G710 GPU的高能效基础之上的。根据Arm公布的数据显示,Mali-G710在旗舰和高端Android智能手机上提供出色的 GPU 效率,在包括高级 AAA 游戏、基准测试和轻型工作负载在内的各种内容中,Mali-G710 在峰值和持续工作负载方面均以 FPS/W 的速度击败了竞争对手。
近年来,随着手机游戏市场的持续增长,更复杂和身临其境的 AAA 游戏体验现在在移动设备上越来越常见。领先的 AAA PC 和主机游戏都有移动版本,包括 Genshin Impact、PUBG、Fortnite、使命召唤和王者荣耀等等。此外,新一代用户越来越多地选择移动设备作为他们首选的游戏平台。这主要是由于移动设备上游戏的便利性和功能。

去年,Arm推出的Mali-G710 GPU已经支持基于软件实现的光线追踪效果。联发科也已经在其旗舰产品天玑9000中利用了这一功能,通过移动端光线追踪SDK,将光线追踪技术引入到手机端,但是其是通过软件的形式来实现的,不仅会带来较大的功耗,同时所带来的光线追踪体验提升也相对有限。
而此次Arm推出的Immortalis-G715 GPU则是直接在硬件层面加入了对于光线追踪技术的支持,在大幅提升游戏体验的同时,功耗也得到了进一步控制。
根据Arm公布的数据显示,Immortalis-G715 上的光线追踪仅使用了 4% 的着色器核心区域,同时通过硬件加速实现了 300%以上的性能提升。
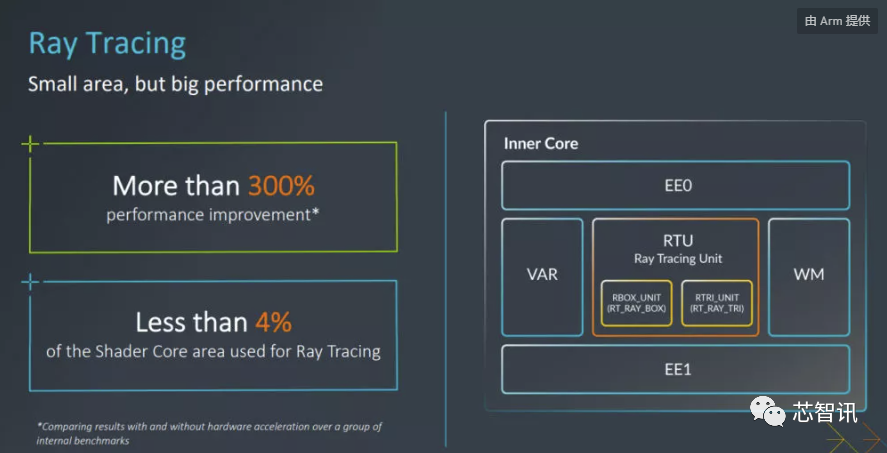
Arm认为,光线追踪代表了移动游戏内容的范式转变。因此决定在 Immortalis-G715 上引入基于硬件的光线追踪支持,因为合作伙伴也已经准备好,硬件已经准备好,并且开发者生态系统已经或即将准备就绪。
Arm称,当Immortalis-G715 于 2023 年初出现在旗舰智能手机中时,这将是生态系统开始探索其游戏内容的光线追踪技术的基础。随着未来几年技术的不断发展,这将有助于为在移动设备上运行的游戏全面过渡到光线追踪做好准备。
Arm全面计算解决方案 (TCS22)
在推出以上CPU IP的基础上,Arm宣布推出 2022 全面计算解决方案 (Total Compute Solutions 2022,TCS22),即利用以上IP组合实现CPU内核间以及与GPU之间的进一步的协同计算,可提供不同级别的性能、效率和可扩展性,以完善各类终端市场的用户体验。

作为 TCS22 的一部分,Cortex-X3、Cortex-A715、Cortex-A510 CPU内核,以及Mali GPU、Immortalis GPU可以配对组合使用,以应对不同的终端需求。
Arm计划通过其TCS22计划向客户提供一系列“专用”芯片设计配置,将各种技术结合在一起,包括其不断扩大的CPU和GPU 设计组合。
据了解,TCS22 的 Arm IP 组合可在一系列工作负载中实现 28% 的性能提升,并可降低 16% 的能耗。
Arm表示,其全面计算战略植根于开发者可及性、安全性和计算性能,旨在为所有消费级设备市场提供优异的性能表现。通过优化的系统设计和实施,助力合作伙伴不断突破极限。
编辑:芯智讯-浪客剑
台湾76家半导体上市公司平均薪资曝光:最高人均138.2万元/年!联发科第3,台积电排名19!
龙芯登陆科创板:2021年净利暴涨227.8%!与MIPS知识产权相关诉讼仍在继续
前台积电厂长+前尔必达社长!昇维旭拟建12吋DRAM厂,计划2024年1季度试产
10Gbps!全球最快!国产最强LPDDR5/5X接口IP成功量产!
2021年全球NOR Flash市场:兆易创新收入暴增100%,份额升至23.2%!
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116