把CPU缓存堆到256MB,可能没有你想得那么美
原创
黄烨锋
电子工程专辑
2022-07-15 12:10
发表于
广东
收录于合集
电子工程专辑
《
电子工程专辑
》中国版创建于1993年,致力于为中国的
设计
、研发、
测试
工程师及技术管理社群提供资讯服务。
2056篇原创内容
公众号
半导体制造技术发展的一个好处,就是现在的人,能对10多年前的人做到降维打击。比如说2001年发布的Windows XP
操作系统
,对硬件最低配置要求包括至少64MB内存,推荐128MB大小确保流畅运行。
而在这个时代,不是说内存大小提升了多少,而是连
CPU
芯片上的L3 cache(三级
缓存
),容量都可以达到256MB——处理器的片上存储资源,其读写速度就比内存(main memory)要快得多了。
IBM
去年Hot Chips 2021上展示的Telum芯片,虚拟L3 cache大小就有256MB(虽然在实体硬件
设计
上有些差异)。有人可能会说,那不是面向消费电子的的(而是面向大型计算机)。
去年我们撰文谈到过,
AMD
基于
先进
封装
技术
,已经把面向电脑的
CPU
L3 cache堆到了最高192MB——而且是确确实实能够在市面上买得到、装进电脑里的;价格也不算多贵。这就是半导体技术,在某种程度上表现出的时代碾压。
不过片上cache这么大,真的有用吗?
有关多级cache的基础知识
花少许篇幅做个小科普。当代面向PC、手机的处理器,通常都会采用多级cache
设计
。比如
高通
骁龙
处理器、
Intel
酷睿
处理器,
CPU
部分都会有L1、L2、L3 cache。其中L1 cache最接近处理器核心,数据存取最快,容量也最小;接着是L2 cache,容量比L1 cache大很多,但速度会稍慢;L3是此类处理器的最后一级
缓存
系统(LLC),容量最大,但速度也最慢。
文首提到的256MB这么大的cache,一般都只会是L3 cache——这种cache通常是处理器多个核心共享的一种
缓存
(L1就是每个核心独有、而非共享的);某些系统可能会有L4 cache,但L4 cache很少见,且这种cache在介质上也已经不再是片上
SRAM
;还有一些系统,在更高的层级会多一级
System C
ache,现在的手机
AP
SoC
就是这样。
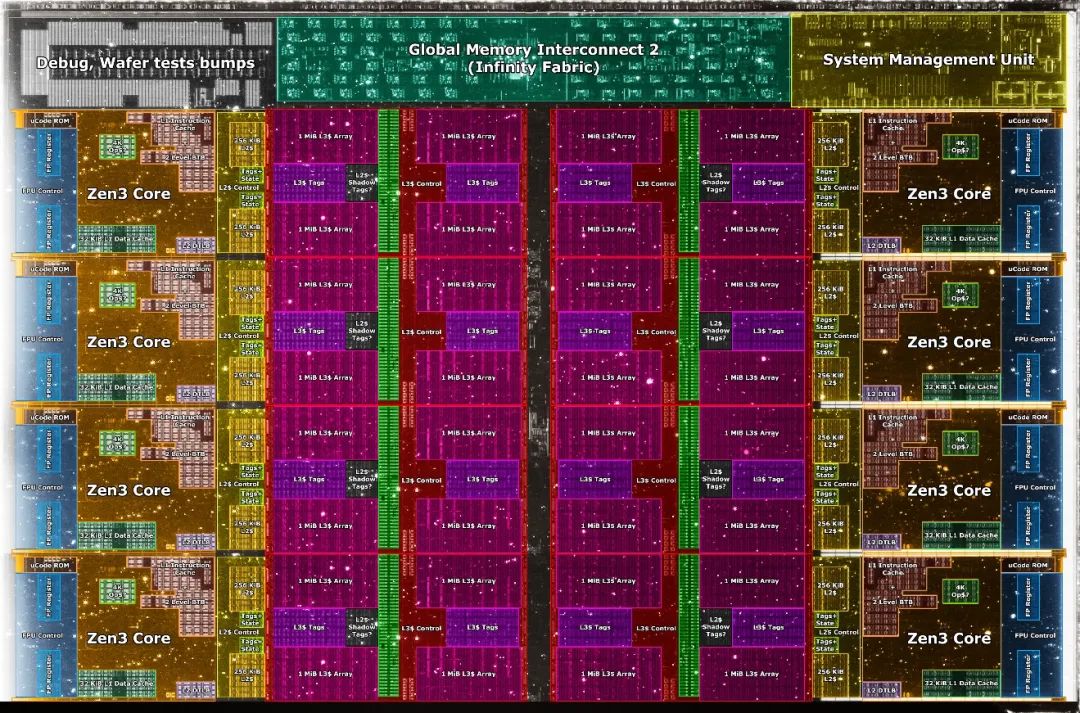
AMD Zen
3的die shot,中间那些红红的都是L3 cache, die shot from Fritzchens Fritz
DRAM
内存是一种很慢的存储系统。现代
CPU
会率先预测所需的数据(和指令),提前把内存里的数据放进cache里。在核心需要的时候就可以立即取用。而多级cache的方案,是在速度、延迟、面积、成本等方面的某种权宜之计。
依据这个原理,更大的片内cache不就越有利于处理器的速度和性能提升吗?实际上,行业从以前PC处理器连L2 cache都不在片内,到现在L3 cache大到能装Windows XP(删去),还是历经了较长的历史发展期的。但cache可不是越大就一定越好的。
各方权衡
从当代
中央处理器
的die shot不难发现,cache可能是占据了最大面积的。片上cache用料增多,通常就意味着die size要变大,面积增大成本就要跟着急剧提升。要不然计算机也不需要内存、硬盘这种更多级的存储系统了。但也不光是成本致cache做不大,相关因素还包括利用率、延迟等。
从芯片
设计
的角度来说,各级cache的设计都受到一定的限制,比如L1 cache的位置和layout,不同的容量,在设计上就可能会有很大差别(而且在系统层面似乎还与更多因素相关)。利用率相关的问题,则有了我们常听到的cache miss rate, hit rate(未命中率/命中率)这类词。
CPU
的
设计
目标普遍在于最小化cache miss,也就是数据应当随时在cache中准备就绪——因为如果cache里没有,需要去内存取数据,就是上百个周期的延迟问题了。
特别值得一提的是“延迟(latency)”,它与cache大小很相关。cache越大,延迟一般也就越久。一方面是因为cache做大以后,面积也就变大了,和核心之间的物理距离也会变远;而更重要的是要从更大的空间里,去找到数据,要耗费的时间也更久。
比如说当代较小的L1 cache访问延迟可能低至3个
时钟
周期,而大的会增长到5个;小尺寸L2 cache延迟8个周期,大的甚至可以达到19个周期。听起来好像也没什么,但1个周期的节约在芯片
设计
上都是极为精贵的。做大cache,或许会有助于提升命中率,但延迟也可能十分致命。
先进
封装
工艺
实现的大cache
去年
AMD
更新了自家的Ryzen 5000系列处理器,在原有5000系列处理器的基础上,出了个“3D V-cache”版。就是在原本的处理器die上方叠了一层L3 cache。
上面这张图是去年的Computex大会上,Lisa Su展示的Ryzen 5900X,其中一片die的上方垂直堆叠了一片L3 cache(左上方的那片die,即CCD die)。
AMD
表示,成品处理器上每片CCD都可以最多叠96MB
SRAM
,那么对于Ryzen 5000而言,最多就能堆出192MB L3 cache。
这种3D堆叠方案是基于
台积电
的So
IC工艺
技术,其亮点在于堆叠两片die是采用hybrid
bonding
键合
,能够达成显著更小的键合间距。《
电子工程专辑
》8月刊的封面故事很快将对
先进
封装
技术
做比较全面的解读,其中也会包含
台积电
的这种
3D堆叠技术
,欢迎届时阅读。
AMD
当前面向服务器的Epyc,和面向PC的Ryzen,都已经有了应用3D V-cache技术的产品问世。而且AMD也明确表示后序的
Zen
4、Zen 5等新架构,也会持续推进3D V-cache的布局工作。
针对Ryzen 5000 + 3D V-cache的宣传,
AMD
主要把着力点放在游戏上,表示相比于原版没有用3D V-cache的处理器,游戏性能平均提升15%。
更大容量cache的代价
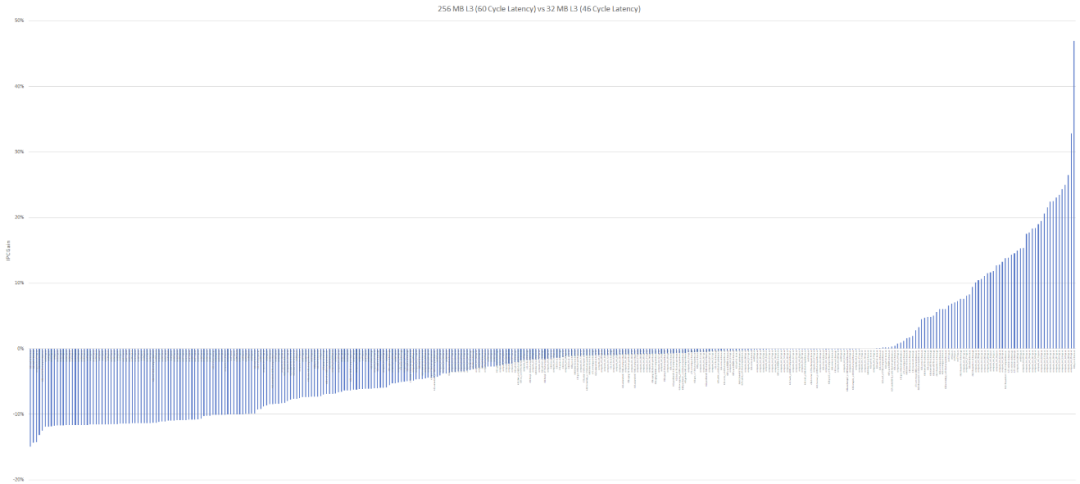
要说性能的话,此前Chips and Cheese对
IBM
Telum处理器,和带3D V-cache的Ryzen处理器做了模拟
测试
。基于IBM此前公布的消息,IBM Telum跑在5+
GHz
基频之上,且256MB L3 cache平均延迟在12ns左右(
5G
Hz 60个周期)。(此项对比中,
AMD Zen
3架构的32MB L3平均延迟46个周期)
Chips and Cheese所做以下相关指令追踪的大量
测试
,是通过模拟的方式来明确高延迟cache带来的影响。
从结果来看,某些子项获得了相当大幅度的性能提升,但也有很多对IPC产生了负面影响,最糟糕的情况下有超过10%的副作用。IPC低10%,在
CPU
领域基本就是一代
微架构
的差异。
没有受益于更大容量L3 cache的
负载
,主要是因为在32MB容量之下,cache hit rate
缓存
命中率就已经很高了。再把容量提升到256MB,更高的延迟实际上是对IPC造成最大影响的干扰项。还有不少
负载
的working set size非常大,即便有8倍的cache容量增加,提升的那点命中率也不足以抵消延迟更长造成的影响。
Chips and Cheese在评论中提到,从另一个角度来看,要用上更大的L3 cache,带来高延迟的前提下,需要显著缩减cache miss rate未命中率,才能够在更多应用中带来实际收益;否则对这部分应用而言,基本就是在浪费die面积、徒增功耗。
再来看看
AMD
的3D V-cache,毕竟
IBM
Telum离我们普通用户还是有些遥远。
AMD
的这类产品已经上市了,以Ryzen 5800X3D为例,这颗芯片约等于Ryzen 5800X加了3D V-cache的版本,
CPU
的L3 cache从原本的32MB,增加到了96MB,是原版5800X的3倍之大;达到了Windows XP的内存容量最低安装需求(删去...)。
不过基于芯片的具体规格,更大的L3 cache从外部特性来看就已经付出了代价。首先是核心超频特性被禁用,而且基频降了400Mhz,睿频降了200MHz,这和电压方面的限制应该有关;密度更高还是叠起来的cache,显然对于榨取核心性能会有影响。这对于更倚重核心性能的
负载
,可能会不利。
另一点是Ryzen 5800X3D的价格更高了,达到了5900X的价格水平。而后者的
CPU
核心数比前者多出4个,频率也更高;当然L3 cache容量不及前者。可见用更多的die去搞大cache,的的确确付出了代价。
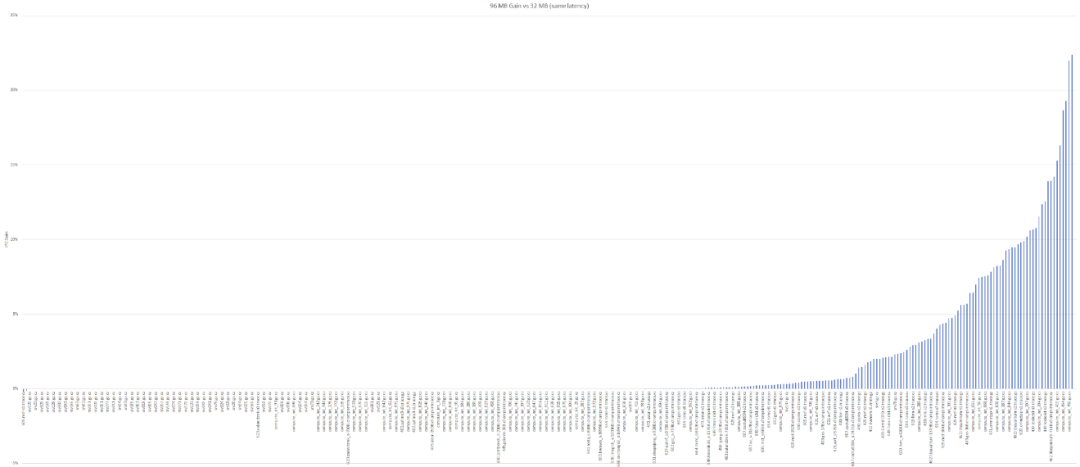
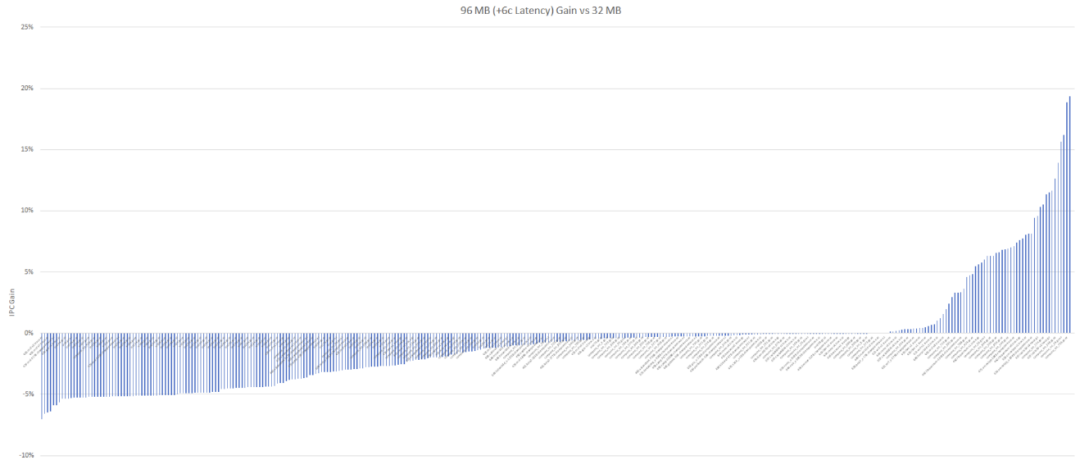
因为
AMD
方面并未给出V-cache的延迟信息,所以Chips and Cheese做了两组模拟
测试
。其一是假定96MB L3 cache的延迟与32MB一样——这是个
理想
情况,可以想象成是3D
封装
技术带来的红利;还有一组是设定96MB L3 cache延迟为52个周期——也就是相比于32MB L3 cache多出6个周期的延迟,结果如下:
在延迟无增加的情况下,一切自然是十分美好的。增加6个周期延迟以后,这张图基本是前面
IBM
Telum 256MB cache的翻版。不过大部分对延迟比较敏感的
负载
,性能损失也就不到5%。虽说5%的IPC降低也挺不好看,但实际应用中的感知应该不会那么明确。上述模拟相关的
测试
详情,可前往Chips and Cheese网站做参详。
所以
AMD
把它定位于“游戏”
值得一提的是,这个
测试
并不是要否定
IBM
和
AMD
用大cache的
设计
。因为的确是存在部分子项,在cache容量增大后有显著收益。而且IBM此前多代产品都有用大cache的传统,毕竟其目标市场很明确,就是较大working set size的
负载
类型:这类应用对延迟本身就相对的没那么敏感。
比较遗憾的是,Chips and Cheese并未明确哪些类型的
负载
,因为延迟增加而存在明确的性能退步。但好在
AnandTech
上个月已经对Ryzen 5800X3D做了
测试
(但很遗憾的是,没测延迟;从系统测试结果来看,延迟好像也并未构成大的影响)。
实际上,
AMD
针对这类型的芯片做宣传时也明确它面向“游戏”。
AnandTech
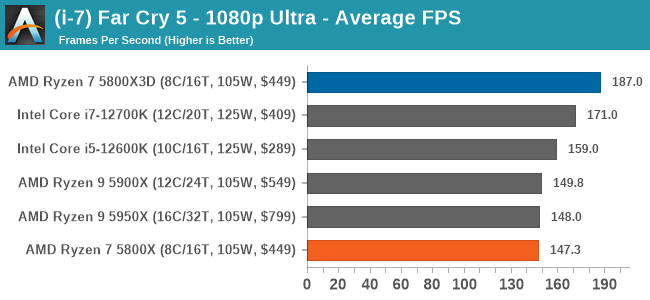
测了不少游戏,本文只给出几个比较具有代表性的,《孤岛惊魂5》、《无主之地3》和《最终幻想15》。
注意图中的价格标注应该是错误的,5800X的价格是350美元
在常规分辨率下,5800X3D在大半游戏里,都可越级秒杀自家更高定位的产品,以及隔壁的竞品;虽然价格也的确变高了。比如在《孤岛惊魂5》1080p Ultra画质下,Ryzen 5800X3D相比原版5800X,帧率提升了多达27%;比核心数更多、IPC更高、频率也更高的
酷睿
i7-12700K领先9%。
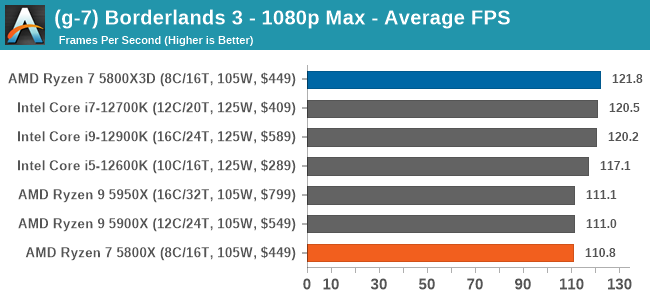
不过在不同分辨率和某些个别游戏里,
测试
结果会有差异,比如在
4K
分辨率下,Ryzen 5800X3D的大容量cache就变得无足轻重了,可轻易被主频和核心数更多的
Intel
超越。还有像《战争机器战略版(Gears Tactics)》《奇异小队(Strange Brigade)》这种游戏,对
AMD
的U本来也没有那么友好,即便常规分辨率下,5800X3D其实也讨不到多少好处。
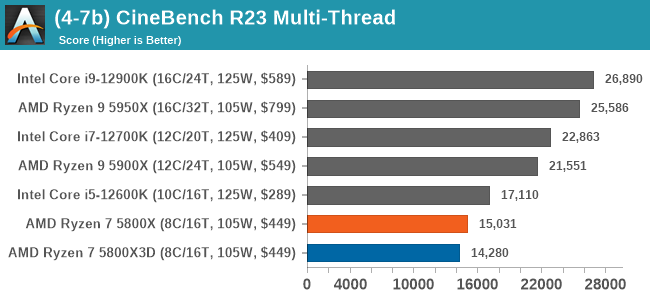
不过在游戏之外,各类系统
测试
或真是
负载
测试都表现出,Ryzen 5800X3D的大cache没有什么软用。而且因为前文提到了其核心频率相比原版5800X还更低,所以某些测试里的成绩还弱于5800X,更不要说和核心
微架构
迭代的12代
酷睿
比。比如Cinebench R23
多线程
、
Blender
测试
。
基本可以明确的是,PC使用场景下,非游戏类应用,3D V-cache即便达成了更大的cache性能,而且
封装
技术还很高级,价格还更贵,也帮不上什么忙。无怪乎
AMD
将此完全面向游戏玩家做宣传。所以对普通用户而言,还是要依据需求来决策选择。
不过我们感觉,像3D V-cache这种在工程上付出了较大努力的产品,还是值得相当程度的肯定的。尤其
AMD
这个系列的产品,乃是时下先进
封装
工艺
技术发展的典型代表;更何况不是还有应用了3D V-cache的Epyc服务器处理器吗?
作者:黄烨锋 资深产业分析师
EET
电子工程专辑
原创
END
预览时标签不可点
收录于合集
#
个
上一篇
下一篇
阅读原文